AI 批量调用成本控制:从请求日志到预算阈值的完整工作流
来源:17golang原创
时间:2026-06-17 10:32:08 202浏览 收藏
AI 接口接入以后,最容易被低估的不是第一版功能,而是批量调用带来的成本波动。一个循环、一批导入任务、一个后台补数据脚本,如果没有日志、阈值和分流策略,很快就会把 token 用量推高。本文给出一套可复用工作流:先记录请求,再估算 token,接着设置预算阈值,最后把实时请求和离线批处理分开管理。
先说结论:AI 批量调用不要只在代码里“发请求”。更稳的做法是把每次调用都当成一条可审计任务,记录输入长度、输出长度、模型、业务场景和结果状态;对实时任务设置短路保护,对离线任务进入队列和批处理;每天用账单与本地日志做一次复查。这样成本异常会早暴露,而不是月底才发现。
- 目标和边界:先确认要控制哪类成本
- 全流程总览:AI 批量调用成本控制
- 阶段一:记录请求日志,先让用量可见
- 阶段二:估算 token 和预算阈值
- 阶段三:实时请求和离线批处理分流
- 我的推荐流程:从小流量到批量任务
- 常见误区与落地清单
目标和边界:先确认要控制哪类成本
这套流程的目标不是“尽量少用 AI”,而是让每一次调用都有边界。典型场景包括:批量摘要、客服历史对话整理、商品描述生成、简历解析、知识库清洗、离线报告生成。它们共同特点是调用量大、输入长度不稳定、失败后容易重试。
边界也要先定清楚。实时对话、后台补数据、离线批量任务不应该用同一套策略。实时任务更看重延迟和体验,离线任务更看重吞吐、可重跑和成本上限。把它们混在一起,往往会出现白天用户请求被批处理抢额度,或者离线任务因为重试把预算打穿。
| 任务类型 | 核心目标 | 风险点 | 控制方式 |
|---|---|---|---|
| 实时请求 | 低延迟、稳定响应 | 突发流量放大成本 | 限流、短路、降级回复 |
| 离线批量 | 高吞吐、可重跑 | 循环和重试失控 | 队列、批次、预算阈值 |
| 后台补数 | 补齐历史数据 | 长文本输入过大 | 抽样试跑、分段处理 |
全流程总览:AI 批量调用成本控制
一套可控的 AI 调用链路,至少要经过五个环节:请求日志、token 估算、预算阈值、队列降级、账单复查。少了前两个环节,成本不可见;少了中间两个环节,异常难拦住;少了最后复查,线上策略就很难持续改进。

这里的关键不是某个单点工具,而是流程闭环。比如一次批量摘要任务,先记录每条输入长度和业务来源,再估算总 token 量;超过阈值就进入等待队列或拆小批次;任务完成后用服务端账单和本地日志核对,确认哪些场景最贵、哪些重试最多。
阶段一:记录请求日志,先让用量可见
第一阶段目标是可见性。很多成本失控不是模型突然变贵,而是业务侧不知道谁在用、为什么用、用了多少。请求日志建议至少记录这些字段:
- 业务场景:例如
product_summary、ticket_reply、report_draft。 - 模型名称和调用类型:实时、队列、离线批量。
- 输入长度、输出长度、估算 token、返回状态。
- 批次号、任务 ID、重试次数和降级原因。
def record_ai_call(row):
log = {
"scene": row["scene"],
"model": row["model"],
"mode": row["mode"],
"input_chars": len(row["prompt"]),
"output_chars": len(row.get("answer", "")),
"token_guess": row["token_guess"],
"status": row["status"],
"batch_id": row.get("batch_id", ""),
"retry_count": row.get("retry_count", 0),
}
save_log(log)
检查点很直接:任意一笔账单上涨,都能追到业务场景和批次号。如果只能看到总费用,看不到具体来源,就还没有进入可控状态。
阶段二:估算 token 和预算阈值
第二阶段目标是提前拦截。严格 token 计算可以使用对应模型的 tokenizer;如果只是上线前保护,也可以先用字符长度做保守估算,再在日志里用真实返回量校正。
def rough_token_guess(text: str) -> int:
# 中文、英文、代码混合时,先用保守倍率做上线保护。
return max(1, len(text) // 2)
def should_queue(prompt: str, daily_used: int, daily_limit: int) -> bool:
next_guess = rough_token_guess(prompt)
return daily_used + next_guess > daily_limit
阈值建议分三层:单请求上限、单批次上限、每日预算上限。单请求上限防止超长输入拖垮体验;单批次上限防止后台任务一次跑太多;每日预算上限防止异常循环在短时间内放大成本。
阶段三:实时请求和离线批处理分流
第三阶段目标是分流。实时请求不能无限等待,离线任务也不应该抢实时额度。可以按任务是否需要用户立刻看到结果来分:需要立即反馈的走实时通道;不急的进入离线批量队列,按批次回收结果。
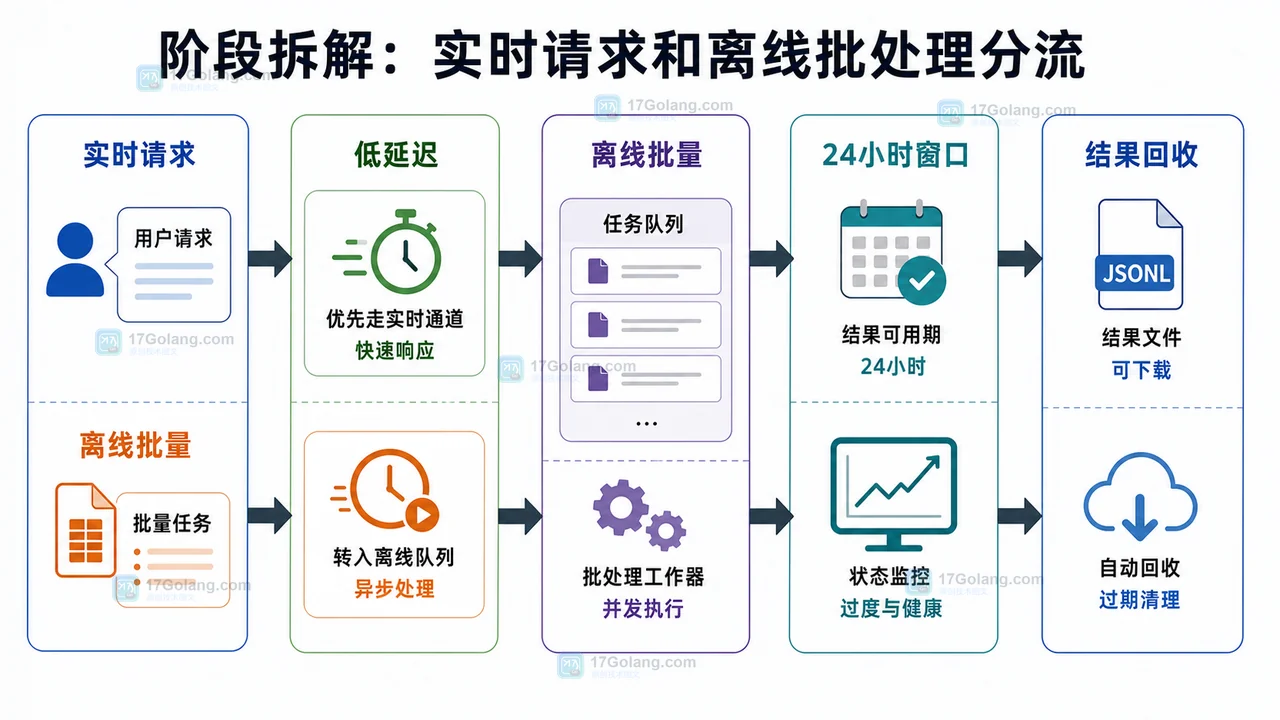
官方文档中,Batch API 面向非实时任务,通常按文件提交请求并在完成后取回结果。这个模式适合摘要、分类、清洗、批量改写等不需要立刻返回给用户的场景。实时链路则要保留更严格的延迟、失败和降级策略。
| 判断问题 | 推荐通道 | 检查点 |
|---|---|---|
| 用户是否正在等待结果 | 实时请求 | 延迟和失败率可观测 |
| 任务能否稍后拿结果 | 离线批量 | 批次 ID 和结果文件可追踪 |
| 预算是否快到阈值 | 队列或降级 | 不会继续放大成本 |
我的推荐流程:从小流量到批量任务
落地时不要一步到位直接跑全量。我的推荐流程是:
- 先选一个业务场景接入日志,至少连续观察一天。
- 用历史输入样本估算 token 区间,给单请求和单批次设置上限。
- 把实时请求和离线任务拆成两条队列,分别统计成功、失败、重试和降级。
- 离线任务先跑 100 条样本,确认质量、成本和结果回收方式。
- 每天固定复查账单和本地日志,把异常场景加入限制规则。
如果发现某个场景的 token 消耗特别高,不要只怪模型。先看输入是否没有裁剪、上下文是否重复拼接、历史记录是否无限追加、失败重试是否缺少次数上限。这些工程问题通常比模型选择更容易造成浪费。
常见误区与落地清单
常见误区有四个。第一,只记录接口成功失败,不记录输入规模;第二,把实时请求和离线任务放在同一条通道;第三,没有每日预算阈值,异常循环只能靠人工发现;第四,只看服务端总账单,不做业务场景拆分。
| 清单项 | 建议做法 | 通过标准 |
|---|---|---|
| 请求日志 | 记录场景、模型、输入输出长度 | 费用上涨能追到具体批次 |
| 预算阈值 | 设置单请求、单批次、每日上限 | 超过阈值自动排队或降级 |
| 任务分流 | 实时和离线任务分开 | 离线任务不影响用户请求 |
| 账单复查 | 每天核对服务端账单和本地日志 | 能发现异常场景和重试放大 |
总结一下:AI 批量调用的成本控制,核心是把“调用”变成“可审计任务”。请求日志让用量可见,token 估算让风险提前暴露,预算阈值让异常能停下来,实时和离线分流让资源更稳定,账单复查让策略持续变好。这个闭环搭好后,再扩展批量生成、内容清洗和知识库任务,心里会踏实很多。
-
284 收藏
-
387 收藏
-
328 收藏
-
426 收藏
-
147 收藏
-

- 前端进阶之JavaScript设计模式
- 设计模式是开发人员在软件开发过程中面临一般问题时的解决方案,代表了最佳的实践。本课程的主打内容包括JS常见设计模式以及具体应用场景,打造一站式知识长龙服务,适合有JS基础的同学学习。
- 立即学习 543次学习
-

- GO语言核心编程课程
- 本课程采用真实案例,全面具体可落地,从理论到实践,一步一步将GO核心编程技术、编程思想、底层实现融会贯通,使学习者贴近时代脉搏,做IT互联网时代的弄潮儿。
- 立即学习 516次学习
-

- 简单聊聊mysql8与网络通信
- 如有问题加微信:Le-studyg;在课程中,我们将首先介绍MySQL8的新特性,包括性能优化、安全增强、新数据类型等,帮助学生快速熟悉MySQL8的最新功能。接着,我们将深入解析MySQL的网络通信机制,包括协议、连接管理、数据传输等,让
- 立即学习 500次学习
-

- JavaScript正则表达式基础与实战
- 在任何一门编程语言中,正则表达式,都是一项重要的知识,它提供了高效的字符串匹配与捕获机制,可以极大的简化程序设计。
- 立即学习 487次学习
-

- 从零制作响应式网站—Grid布局
- 本系列教程将展示从零制作一个假想的网络科技公司官网,分为导航,轮播,关于我们,成功案例,服务流程,团队介绍,数据部分,公司动态,底部信息等内容区块。网站整体采用CSSGrid布局,支持响应式,有流畅过渡和展现动画。
- 立即学习 485次学习