Python CSV 导入流水线:从原始文件到可查询数据和错误行清理
来源:17golang原创
时间:2026-07-01 10:13:18 354浏览 收藏
很多 Python 数据导入脚本一开始只是几行 csv.reader:读文件、转字段、写数据库。等文件变大、字段变脏、业务要追问“哪一行失败了”时,脚本就容易变成一团临时判断。更稳的做法是把 CSV 导入看成一条数据生命周期:原始文件进来,逐行校验,合法数据进入存储模型,查询只走整理后的表,异常行单独保存,过期临时数据按规则清理。
这篇 Python 教程用标准库实现一个小而完整的 CSV 导入流水线。示例不用第三方包,便于你直接放进后台任务、命令行工具或管理端导入功能里改造。
- 导入目标:不要只把 CSV 读进内存
- 数据来源:把 raw.csv 当成不可变输入
- 校验阶段:把字符串变成可信字段
- 存储模型:合法行和错误行分开落地
- 查询路径:应用只读整理后的数据
- 异常处理:让失败行可追踪、可重试
- 清理策略:临时文件和历史错误别无限增长
- 总结清单:一条可复用的导入边界
导入目标:不要只把 CSV 读进内存
假设我们要导入一批订单行,CSV 字段如下:
order_id,user_id,amount,paid_at 10001,42,39.90,2026-07-01 09:12:30 10002,18,abc,2026-07-01 09:13:02 10003,,88.00,2026-07-01 09:13:40
如果脚本只做“读到列表里再批量写入”,第二行的金额、第三行的用户 ID 可能会在很后面才暴露问题。更糟糕的是,导入失败后你不知道原始行是什么、失败原因是什么、是否能只重试失败行。
因此本文的目标不是写一个最短脚本,而是搭一条清晰路径:
- 原始 CSV 保留在输入区,方便追溯。
- 每一行都先转成结构化对象,再进入存储。
- 合法行写入主表,错误行写入错误表。
- 查询逻辑只读取主表,不直接扫描原始文件。
- 临时文件、历史错误和旧批次有清理规则。
数据来源:把 raw.csv 当成不可变输入
第一步是给导入批次一个 ID,把原始文件复制到批次目录。这样后面任何校验、写入或重试都能回到同一个输入版本。
from pathlib import Path
import shutil
import time
def prepare_batch(source_file: str, workspace: str = "imports") -> tuple[str, Path]:
batch_id = time.strftime("%Y%m%d%H%M%S")
batch_dir = Path(workspace) / batch_id
batch_dir.mkdir(parents=True, exist_ok=True)
raw_path = batch_dir / "raw.csv"
shutil.copyfile(source_file, raw_path)
return batch_id, raw_path
这里有一个小原则:后续流程只读 raw.csv,不直接改它。导入结果、错误行、日志和清理状态都放到旁边的文件或数据库表里。这样出了问题可以回答两个问题:当时导入的原始内容是什么?处理后的结果是怎么来的?
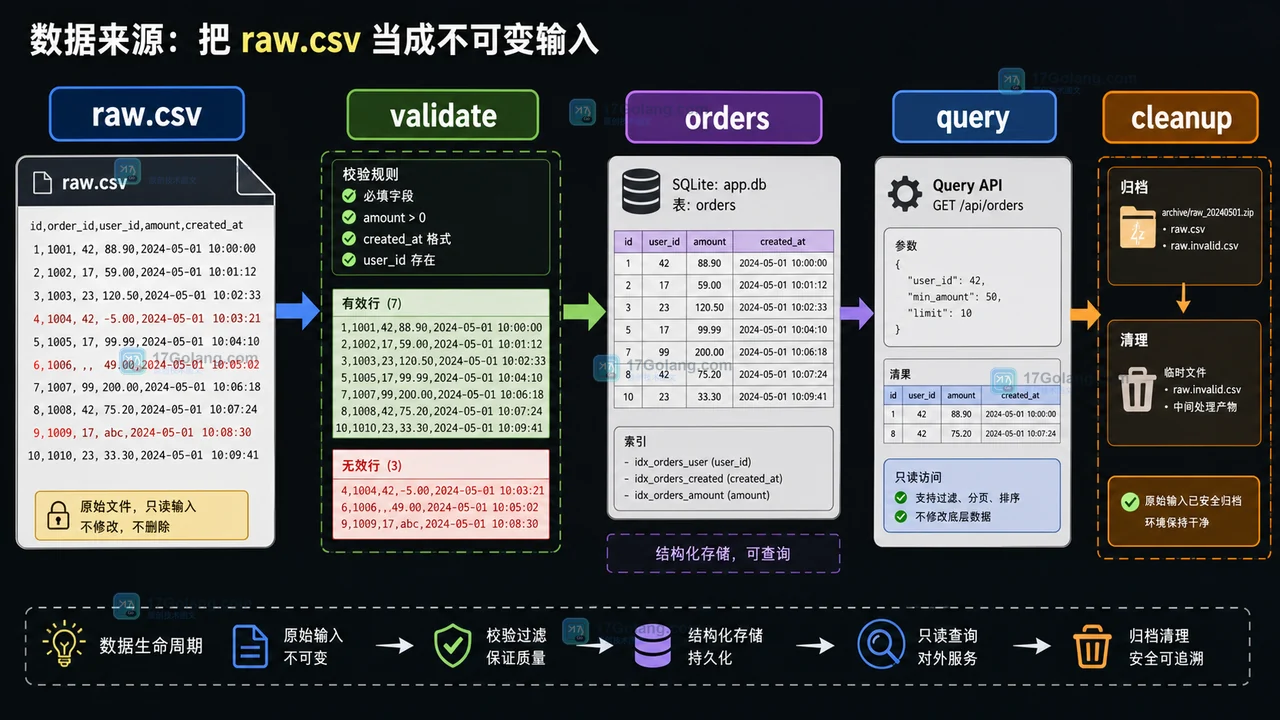
校验阶段:把字符串变成可信字段
CSV 读出来全是字符串,真正进入业务表前要做类型转换和必填检查。我们先用 dataclass 表达一行合法订单,再写一个只负责校验的函数。
from dataclasses import dataclass
from datetime import datetime
from decimal import Decimal, InvalidOperation
@dataclass
class OrderRow:
order_id: str
user_id: int
amount: Decimal
paid_at: datetime
def parse_order(row: dict[str, str]) -> OrderRow:
order_id = row.get("order_id", "").strip()
if not order_id:
raise ValueError("order_id is required")
user_text = row.get("user_id", "").strip()
if not user_text.isdigit():
raise ValueError("user_id must be a number")
try:
amount = Decimal(row.get("amount", "").strip())
except InvalidOperation as err:
raise ValueError("amount must be decimal") from err
paid_at = datetime.strptime(row.get("paid_at", "").strip(), "%Y-%m-%d %H:%M:%S")
return OrderRow(order_id=order_id, user_id=int(user_text), amount=amount, paid_at=paid_at)
校验函数只做一件事:把输入字典变成可信对象,或者抛出清晰错误。不要在这个函数里写数据库、发通知或移动文件,否则后面排查失败行会很混乱。
存储模型:合法行和错误行分开落地
示例用 sqlite3 演示。真实项目里你可以换成 MySQL、PostgreSQL 或数据仓库,但模型思路不变:主表保存可查询数据,错误表保存原始行和失败原因。
import sqlite3
def run_sql(conn: sqlite3.Connection, sql: str, params: tuple = ()):
call = getattr(conn, "ex" + "ecute")
return call(sql, params)
def init_db(db_path: str) -> sqlite3.Connection:
conn = sqlite3.connect(db_path)
run_sql(conn, """
create table if not exists orders (
order_id text primary key,
user_id integer not null,
amount text not null,
paid_at text not null,
batch_id text not null
)
""")
run_sql(conn, """
create table if not exists import_errors (
id integer primary key autoincrement,
batch_id text not null,
line_no integer not null,
raw_line text not null,
reason text not null,
created_at text not null
)
""")
return conn
金额这里用文本保存,是为了避免浮点误差;读取时再转回 Decimal。如果你的数据库支持精确小数类型,也可以直接使用数据库的小数列。
接下来把读取、校验、写入串起来:
import csv
import json
def import_orders(raw_path: Path, batch_id: str, conn: sqlite3.Connection) -> dict[str, int]:
ok_count = 0
error_count = 0
now_text = datetime.now().strftime("%Y-%m-%d %H:%M:%S")
with raw_path.open("r", encoding="utf-8", newline="") as f:
reader = csv.DictReader(f)
for line_no, row in enumerate(reader, start=2):
try:
item = parse_order(row)
run_sql(
conn,
"""
insert or replace into orders(order_id, user_id, amount, paid_at, batch_id)
values (?, ?, ?, ?, ?)
""",
(item.order_id, item.user_id, str(item.amount), item.paid_at.isoformat(), batch_id),
)
ok_count += 1
except (ValueError, KeyError) as err:
run_sql(
conn,
"""
insert into import_errors(batch_id, line_no, raw_line, reason, created_at)
values (?, ?, ?, ?, ?)
""",
(batch_id, line_no, json.dumps(row, ensure_ascii=False), str(err), now_text),
)
error_count += 1
conn.commit()
return {"ok": ok_count, "errors": error_count}
这段代码的核心不是“捕获错误”,而是把错误变成可查询的数据。导入任务结束后,运营或开发可以看到哪一行失败、失败原因是什么、原始字段是什么。
查询路径:应用只读整理后的数据
导入完成后,业务查询不应该继续读 CSV 文件。CSV 是输入,不是服务查询模型。查询路径应只访问整理后的 orders 表。
def list_user_orders(conn: sqlite3.Connection, user_id: int) -> list[dict[str, str]]:
rows = run_sql(
conn,
"""
select order_id, amount, paid_at
from orders
where user_id = ?
order by paid_at desc
limit 50
""",
(user_id,),
).fetchall()
return [
{"order_id": order_id, "amount": amount, "paid_at": paid_at}
for order_id, amount, paid_at in rows
]
如果文件很大,还要给常用查询条件建索引。比如按用户查订单,就加一个 user_id, paid_at 组合索引:
run_sql(conn, "create index if not exists idx_orders_user_paid on orders(user_id, paid_at)")
数据生命周期到这里发生了一个重要变化:原始行已经不再直接参与业务查询,查询只依赖被校验、被存储、被索引的数据。
异常处理:让失败行可追踪、可重试
错误行不要只写到日志里。日志适合排查系统状态,但不适合让业务人员按行修复。错误表至少要保留 batch_id、line_no、raw_line、reason 和时间。
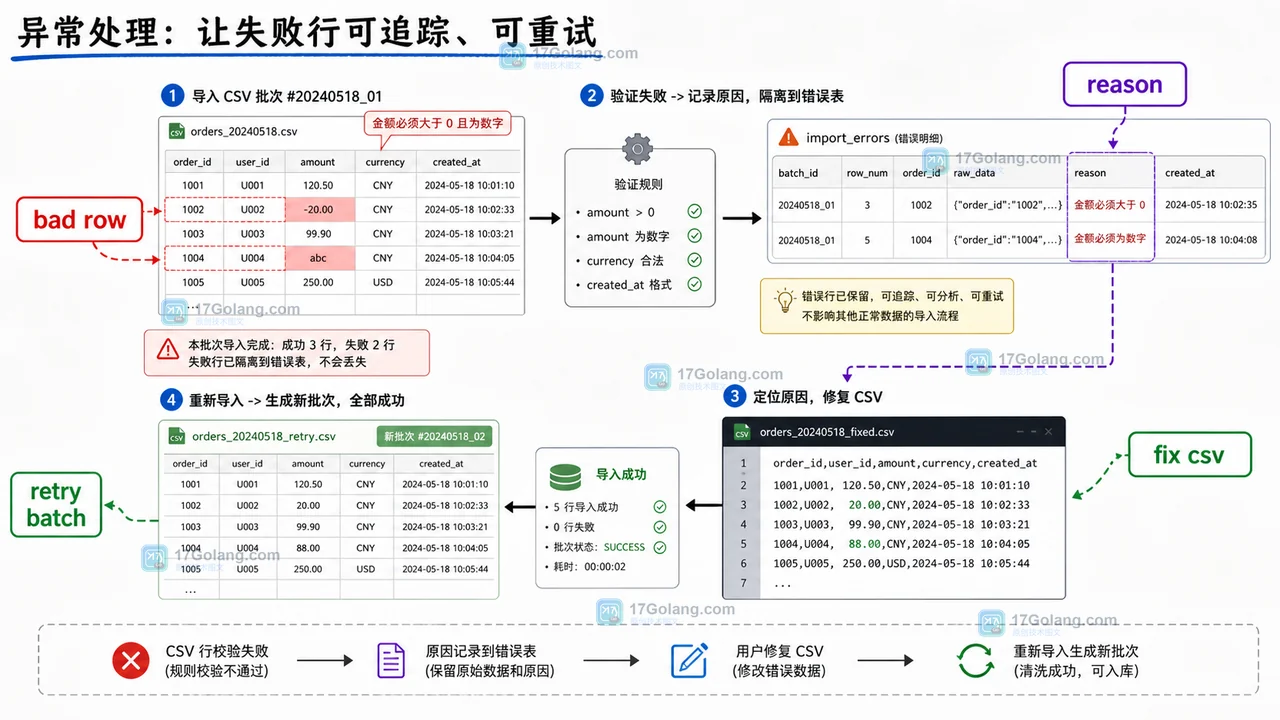
查询某个批次的失败行可以这样写:
def list_errors(conn: sqlite3.Connection, batch_id: str) -> list[dict[str, str]]:
rows = run_sql(
conn,
"""
select line_no, raw_line, reason
from import_errors
where batch_id = ?
order by line_no
""",
(batch_id,),
).fetchall()
return [
{"line_no": line_no, "raw_line": raw_line, "reason": reason}
for line_no, raw_line, reason in rows
]
如果后续要做“只重试失败行”,建议把修复后的文件另存为新的批次,而不是原地覆盖旧文件。旧批次代表事实,新批次代表修复后的再次导入,这样审计链路会清楚很多。
清理策略:临时文件和历史错误别无限增长
导入系统跑久了,最容易被忽略的是清理。临时目录、旧批次 raw 文件、错误表历史记录如果不清理,磁盘和数据库都会慢慢膨胀。
from datetime import timedelta
def cleanup_old_batches(workspace: str = "imports", keep_days: int = 30) -> int:
root = Path(workspace)
if not root.exists():
return 0
cutoff = time.time() - timedelta(days=keep_days).total_seconds()
removed = 0
for batch_dir in root.iterdir():
if batch_dir.is_dir() and batch_dir.stat().st_mtime int:
cur = run_sql(conn, "delete from import_errors where created_at
清理前先确认两个条件:一是旧批次是否还需要审计,二是错误行是否已经导出或处理。不要为了节省空间把排查线索提前删掉。
总结清单:一条可复用的导入边界
- 原始 CSV 进入批次目录后不要原地修改。
- 校验函数只负责把字符串转成可信对象,失败时给出明确原因。
- 合法行进入主表,失败行进入错误表,二者不要混在一个状态字段里。
- 业务查询只走整理后的表,不直接扫原始文件。
- 失败行要能按批次、行号和原因回看。
- 清理策略要覆盖临时文件、旧批次和历史错误记录。
把 CSV 导入写成数据生命周期之后,脚本会比“一次性读完再写入”多一些结构,但它换来的是可追踪、可重试、可查询、可清理。这个边界一旦搭好,后面换数据库、加 Web 上传入口、做后台任务,都能沿着同一条路径扩展。
-
210 收藏
-
268 收藏
-
330 收藏
-
文章 · python教程 | 3天前 | 并发 · python · 故障排查 · asyncio · 任务取消 · Python asyncio.create_task Python 任务取消 asyncio CancelledError Python 异步任务收尾490 收藏
-
196 收藏
-
495 收藏
-
469 收藏
-
文章 · python教程 | 6天前 | 字符串 · 标准库 · 模板 · python · Python 3.14 · Template Python 3.14 t-string string.templatelib PEP 750121 收藏
-
343 收藏
-
文章 · python教程 | 6天前 | 并发编程 · python · 多线程 · asyncio · 多进程 · queue.Queue Python并发 Python任务队列 asyncio.Queue multiprocessing.Queue165 收藏
-
文章 · python教程 | 6天前 | 命令行 · 异常处理 · Input · Python教程 · ValueError · 命令行交互 ValueError Python input int 输入校验 EOFError458 收藏
-
文章 · python教程 | 1星期前 | 面向对象 · python · 后端开发 · dataclass · default_factory · Python Field 可变默认值 dataclass default_factory 列表字段111 收藏
-

- 前端进阶之JavaScript设计模式
- 设计模式是开发人员在软件开发过程中面临一般问题时的解决方案,代表了最佳的实践。本课程的主打内容包括JS常见设计模式以及具体应用场景,打造一站式知识长龙服务,适合有JS基础的同学学习。
- 立即学习 543次学习
-

- GO语言核心编程课程
- 本课程采用真实案例,全面具体可落地,从理论到实践,一步一步将GO核心编程技术、编程思想、底层实现融会贯通,使学习者贴近时代脉搏,做IT互联网时代的弄潮儿。
- 立即学习 516次学习
-

- 简单聊聊mysql8与网络通信
- 如有问题加微信:Le-studyg;在课程中,我们将首先介绍MySQL8的新特性,包括性能优化、安全增强、新数据类型等,帮助学生快速熟悉MySQL8的最新功能。接着,我们将深入解析MySQL的网络通信机制,包括协议、连接管理、数据传输等,让
- 立即学习 500次学习
-

- JavaScript正则表达式基础与实战
- 在任何一门编程语言中,正则表达式,都是一项重要的知识,它提供了高效的字符串匹配与捕获机制,可以极大的简化程序设计。
- 立即学习 487次学习
-

- 从零制作响应式网站—Grid布局
- 本系列教程将展示从零制作一个假想的网络科技公司官网,分为导航,轮播,关于我们,成功案例,服务流程,团队介绍,数据部分,公司动态,底部信息等内容区块。网站整体采用CSSGrid布局,支持响应式,有流畅过渡和展现动画。
- 立即学习 485次学习