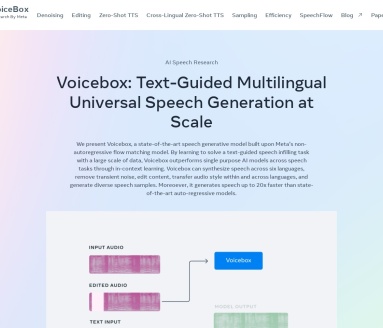
Voicebox
工具简介
探索Voicebox,Meta开发的非自回归流匹配模型,支持六种语言,20倍速生成语音。去噪、编辑、风格转换,体验上下文学习的强大功能。
详细介绍

Voicebox:Meta的尖端语音生成模型,开启语音合成新时代
Voicebox是由Meta公司开发的一款革命性的语音生成模型,采用非自回归流匹配技术,能够通过大规模数据学习进行文本引导的语音填充任务。Voicebox不仅支持多语言合成,还能去除瞬态噪声、编辑内容、转换音频风格,并生成多样化的语音样本,其速度比现有自回归模型快20倍。
核心优势:
- 多语言支持:支持英语、法语、德语、西班牙语、波兰语和葡萄牙语,覆盖广泛的语言需求。
- 高效生成:比现有最先进的自回归模型快20倍,极大提升了语音生成效率。
- 上下文学习:通过上下文学习,执行未明确训练的任务,灵活性极强。
- 未来上下文利用:与传统自回归模型不同,Voicebox可以利用未来上下文,实现更精确的语音处理。
强大功能:
- 瞬态噪声去除:有效去除录音中的瞬态噪声,如门铃声或狗叫声,提升音质。
- 内容编辑:无需重新录音即可纠正误读的单词,简化编辑流程。
- 零样本文本到语音合成:通过上下文学习,合成具有任何音频风格的语音,满足多样化需求。
- 跨语言风格转换:跨语言转换音频风格,如使用法语提示生成英语语音,增强创作自由度。
- 多样化语音生成:通过采样技术,创造独特且富有表现力的音频风格,满足创意需求。
应用场景:
- 瞬态噪声去除:使用Voicebox重新生成被噪声污染的语音,提升录音质量。
- 内容编辑:对误读的文本进行编辑,Voicebox会相应调整语音输出,提高编辑效率。
- 零样本文本到语音合成:输入想要风格的参考音频和文本,Voicebox将合成听起来与参考一致的语音,满足个性化需求。
- 跨语言风格转换:使用非英语的音频提示生成英语语音,或将配音语音转换为原说话者的声音,增强跨语言交流。
- 多样化语音生成:Voicebox可以创建独特的音频风格,无需任何音频条件,激发创意灵感。
总结:
Voicebox作为Meta公司开发的多语言语音生成模型,凭借其上下文学习能力和高效生成速度,在语音合成、编辑和风格转换方面展现出了强大的潜力。尽管Voicebox具有巨大的应用前景,但Meta公司也意识到技术滥用的风险,并采取了相应措施,如建立有效的分类器来区分真实语音和由Voicebox生成的音频,以确保技术的负责任使用。目前,Voicebox模型和代码尚未公开提供,以确保其安全性和合规性。
相关工具

声动视界SoundView
声动视界SoundView:AI赋能视频内容全球化
标贝悦读AI配音
标贝悦读AI配音:快速转换文字为逼真语音

声咔AI配音
标题:声咔AI配音:专业音频创作的智能助手

Text To Speech
在线文本转语音服务:Text To Speech,快速转换多语言语音
Fish Audio
Fish Audio:开源AI语音合成与声音克隆工具

FineVoice
FineVoice:Fineshare的多功能AI配音工具
NaturalReader
NaturalReader:AI文本到语音转换的强大工具

Rask.ai
Rask.ai:AI驱动的音视频配音与本地化平台
Peech
Peech:智能文本到语音转换工具,提升听书体验

iMyFone VoxBox
SEO标题:iMyFone VoxBox:AI文本到语音和声音克隆的终极解决方案