GO CountMinSketch计数器(布隆过滤器思想的近似计数器)
来源:脚本之家
时间:2023-01-01 21:57:50 479浏览 收藏
知识点掌握了,还需要不断练习才能熟练运用。下面golang学习网给大家带来一个Golang开发实战,手把手教大家学习《GO CountMinSketch计数器(布隆过滤器思想的近似计数器)》,在实现功能的过程中也带大家重新温习相关知识点,温故而知新,回头看看说不定又有不一样的感悟!
简介
CountMinSketch是一种计数器,用来统计一个元素的计数,它能够以一个非常小的空间统计大量元素的计数,同时保证高的性能及准确性。
与布隆过滤器类似,由于它是基于概率的,因此它所统计的计数是有一定概率存在误差的,也就是可能会比真实的计数大。比如一个元素实际的计数是10,但是计算器的计算结果可能比10大。因此适合能够容忍计数存在一定误差的场景,比如社交网络中推文的访问次数。
它一秒能够进行上百万次操作(主要取决于哈希函数的速度),并且如果我们每天有一个长度为100亿的数据流需要进行计数,计数值允许的误差范围是100,允许的错误率是0.1%,计数器大小是32位,只需要7.2GB内存,这完全可以单机进行计数。
原理
数据结构
CountMinSketch计数器的数据结构是一个二维数组,每一个元素都是一个计数器,计数器可以使用一个数值类型进行表示,比如无符号int:

增加计数
每个元素会通过不同的哈希函数映射到每一行的某个位置,并增加对应位置上的计数:
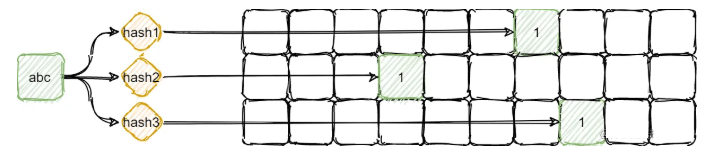
估算计数
估算计数也是如上图流程,根据哈希映射到每一行的对应位置,然后读取所有行的计数,返回其中最小的一个。
返回最小的一个是因为其他其他元素也可能会映射到自身所映射位置上面,导致计数比真实计数大,因此最小的一个计数最可能是真实计数:
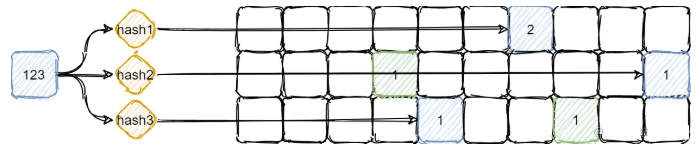
比如上图元素123映射到了元素abc第一行的相同位置,因此这个位置的计数累加了元素abc和元素123的计数和。但是只要我们取三行里面最小的一个计数,那么就能容忍这种情况。
当然,如果一个元素的每一行的对应位置都被其他元素所映射,那么这个估算的计数就会比真实计数大。
哈希函数
CountMinSketch计数器里面的哈希函数需要是彼此独立且均匀分布(类似于哈希表的哈希函数),而且需要尽可能的快,比如murmur3就是一个很好的选择。
CountMinSketch计数器的性能严重依赖于哈希函数的性能,而一般哈希函数的性能则依赖于输入串(一般为字节数组)的长度,因此为了提高CountMinSketch计数器的性能建议减少输入串的长度。
下面是一个简单的性能测试,单位是字节,可以看到时间的消耗随着元素的增大基本是线性增长的:
pkg: github.com/jiaxwu/gommon/counter/cm cpu: Intel(R) Core(TM) i5-10210U CPU @ 1.60GHz BenchmarkAddAndEstimate/1-8 2289142 505.9 ns/op 1.98 MB/s 0 B/op 0 allocs/op BenchmarkAddAndEstimate/2-8 2357380 513.7 ns/op 3.89 MB/s 0 B/op 0 allocs/op BenchmarkAddAndEstimate/4-8 2342382 496.9 ns/op 8.05 MB/s 0 B/op 0 allocs/op BenchmarkAddAndEstimate/8-8 2039792 499.7 ns/op 16.01 MB/s 0 B/op 0 allocs/op BenchmarkAddAndEstimate/16-8 2350281 526.8 ns/op 30.37 MB/s 0 B/op 0 allocs/op BenchmarkAddAndEstimate/32-8 2558060 444.3 ns/op 72.03 MB/s 0 B/op 0 allocs/op BenchmarkAddAndEstimate/64-8 2540272 459.5 ns/op 139.29 MB/s 0 B/op 0 allocs/op BenchmarkAddAndEstimate/128-8 1919720 538.6 ns/op 237.67 MB/s 0 B/op 0 allocs/op BenchmarkAddAndEstimate/256-8 1601738 720.6 ns/op 355.28 MB/s 0 B/op 0 allocs/op BenchmarkAddAndEstimate/512-8 950584 1599 ns/op 320.18 MB/s 0 B/op 0 allocs/op BenchmarkAddAndEstimate/1024-8 363592 3169 ns/op 323.17 MB/s 0 B/op 0 allocs/op BenchmarkAddAndEstimate/2048-8 187500 5888 ns/op 347.81 MB/s 0 B/op 0 allocs/op BenchmarkAddAndEstimate/4096-8 130425 8825 ns/op 464.15 MB/s 0 B/op 0 allocs/op BenchmarkAddAndEstimate/8192-8 67198 17460 ns/op 469.18 MB/s 0 B/op 0 allocs/op
数组大小、哈希函数数量、错误范围、错误率
数组大小、哈希函数数量、错误范围和错误率之间是互相影响的,如果我们想减少错误率和错误范围,则需要更大的数组和更多的哈希函数。但是我们很难直观的计算出这些参数,还好有两个公式可以帮助我们计算出准确的数值:
在我们可以确定我们的数据流大小和能够容忍的错误范围和错误率的情况下,我们可以根据下面公式计算数组大小和哈希函数数量:
n = 数据流大小 m = 数组大小 k = 哈希函数数量 eRange = 错误范围(ErrorRange) eRate = 错误率(ErrorRate) ceil() = 向上取整操作 E = 2.718281828459045(自然常数) m = ceil(E/(eRange/n)) k = ceil(ln(1/eRate))
应用
TopK(海量数据计数器)
对于海量数据流中频率最高的K个数,如果使用常规的map,由于内存大小限制,一般情况下单机无法完成计算,需要把数据路由到多台机器上进行计数。
而如果我们使用CountMinSketch则能够在单机情况下处理大量的数据,比如开头所提到对于一个长度为100亿的数据流进行计数,只需要7.2GB内存。这个计数结果可能存在一定误差,不过我们可以在这个基础上再进行过滤。
TinyLFU
TinyLFU是一个缓存淘汰策略,它里面有LFU策略的思想,LFU是一个基于访问频率的淘汰策略,因此需要统计每个元素被访问的次数。如果对每个元素使用一个独立的计数器,那么这个成本会很大,而且对于一个缓存淘汰策略来说,我们并不需要这个计数器非常大且非常准确。
因此TinyLFU使用一个计数器长度为4位的CountMinSketch计数器统计每个元素的频率,减少计数所消耗的内存空间,同时还引入了计数衰减机制避免某些之前热门但是当前已经很少被访问的元素很难被淘汰。
实现
这里给出一个Golang的泛型实现,这个实现支持uint8、uint16、uint32、uint64等基本类型计数器,实际上还可以实现比如长度为2bit、4bit、6bit的计数器,但是代码会稍微复杂一点(特别是非2的次方的计数器)。
package cm
import (
"math"
"github.com/jiaxwu/gommon/hash"
mmath "github.com/jiaxwu/gommon/math"
"github.com/jiaxwu/gommon/mem"
"golang.org/x/exp/constraints"
)
// Count-Min Sketch 计数器,原理类似于布隆过滤器,根据哈希映射到多个位置,然后在对应位置进行计数
// 读取时拿对应位置最小的
// 适合需要一个比较小的计数,而且不需要这个计数一定准确的情况
// 可以减少空间消耗
// https://citeseerx.ist.psu.edu/viewdoc/download?doi=10.1.1.591.8351&rep=rep1&type=pdf
type Counter[T constraints.Unsigned] struct {
counters [][]T
countersLen uint64 // 计数器长度
hashs []*hash.Hash // 哈希函数列表
maxCount T // 最大计数值
}
// 创建一个计数器
// size:数据流大小
// errorRange:计数值误差范围(会超过真实计数值)
// errorRate:错误率
func New[T constraints.Unsigned](size uint64, errorRange T, errorRate float64) *Counter[T] {
// 计数器长度
countersLen := uint64(math.Ceil(math.E / (float64(errorRange) / float64(size))))
// 哈希个数
hashsCnt := int(math.Ceil(math.Log(1.0 / errorRate)))
hashs := make([]*hash.Hash, hashsCnt)
counters := make([][]T, hashsCnt)
for i := 0; i
数据结构
这里的数据结构核心是一个k*m的二维数组counters,k是哈希函数数量,m是数组每一行的长度;countersLen其实就是m;hashs是哈希函数列表;maxCount是当前类型的最大值,比如uint8就是255,下面的计算需要用到它。
type Counter[T constraints.Unsigned] struct {
counters [][]T
countersLen uint64 // 计数器长度
hashs []*hash.Hash // 哈希函数列表
maxCount T // 最大计数值
}
初始化
我们首先使用上面提到的两个公式计算数组每一行长度和哈希函数的数量,然后初始化哈希函数列表和二维数组。
// 创建一个计数器
// size:数据流大小
// errorRange:计数值误差范围(会超过真实计数值)
// errorRate:错误率
func New[T constraints.Unsigned](size uint64, errorRange T, errorRate float64) *Counter[T] {
// 计数器长度
countersLen := uint64(math.Ceil(math.E / (float64(errorRange) / float64(size))))
// 哈希个数
hashsCnt := int(math.Ceil(math.Log(1.0 / errorRate)))
hashs := make([]*hash.Hash, hashsCnt)
counters := make([][]T, hashsCnt)
for i := 0; i
增加计数
对于一个元素,我们需要把它根据每个哈希函数计算出它在每一行数组的位置,然后增加对应位置计数器的计数值。
这里需要注意的是,计数值可能会溢出,因此我们首先判断是否溢出,如果溢出则设置为最大值。
// 增加元素的计数
func (c *Counter[T]) Add(b []byte, val T) {
for i, h := range c.hashs {
index := h.Sum64(b) % c.countersLen
if c.counters[i][index]+val
估算计数
同增加计数原理,把元素根据哈希函数映射到每一行数组的对应位置,然后选择所有行中最小的那个计数值。
// 估算元素的计数
func (c *Counter[T]) Estimate(b []byte) T {
minCount := c.maxCount
for i, h := range c.hashs {
index := h.Sum64(b) % c.countersLen
count := c.counters[i][index]
if count == 0 {
return 0
}
minCount = mmath.Min(minCount, count)
}
return minCount
}
今天关于《GO CountMinSketch计数器(布隆过滤器思想的近似计数器)》的内容就介绍到这里了,是不是学起来一目了然!想要了解更多关于golang的内容请关注golang学习网公众号!
-
860 收藏
-
843 收藏
-
826 收藏
-
809 收藏
-
792 收藏
-
Golang · Go教程 | 1小时前 | 并发 · HTTP · 性能优化 · 故障排查 · Go教程 · Go Goroutine 连接复用 pprof http.Client close Response.Body201 收藏
-
Golang · Go教程 | 4天前 | 并发 · 闭包 · for range · 迁移 · Go教程 · Go 1.22 · Goroutine 闭包 循环变量 Go教程 Go 1.22 for range113 收藏
-
331 收藏
-
Golang · Go教程 | 4天前 | 单元测试 · 错误处理 · Go教程 · errors.Join · errors.Is · errors.Is Go错误处理 Go教程 errors.Join 多错误返回 批量校验352 收藏
-
Golang · Go教程 | 4天前 | Context · 超时控制 · Go教程 · http.Client · Transport · Go context 请求超时 Transport http.Client Client.Timeout ResponseHeaderTimeout218 收藏
-
Golang · Go教程 | 4天前 | 文件下载 · Go教程 · 审计日志 · 接口安全 · 路径穿越 · Go 文件下载 审计日志 HTTP接口 filepath.Clean 安全下载 路径穿越362 收藏
-
273 收藏
-
Golang · Go教程 | 4天前 | CI/CD · gitHub actions · Go教程 · 自托管 Runner · 持续集成 · Go 持续集成 CI Go test GitHub Actions self-hosted runner 自托管 runner340 收藏
-
124 收藏
-
Golang · Go教程 | 4天前 | HTTP · 文件下载 · Go教程 · Range请求 · ServeContent · 断点续传 Content-Range Go教程 HTTP Range ServeContent 206 Partial Content 视频拖动250 收藏
-
Golang · Go教程 | 4天前 | csv · Go教程 · 后端架构 · 流式响应 · 大文件导出 · 大文件下载 FLUSH CSV导出 Go教程 流式写出 csv.Writer rows.Next251 收藏
-
Golang · Go教程 | 4天前 | HTTP服务 · Go教程 · 后端开发 · 超时配置 · 服务稳定性 · net/http WriteTimeout HTTP超时 Go教程 ReadHeaderTimeout IdleTimeout140 收藏
-

- 前端进阶之JavaScript设计模式
- 设计模式是开发人员在软件开发过程中面临一般问题时的解决方案,代表了最佳的实践。本课程的主打内容包括JS常见设计模式以及具体应用场景,打造一站式知识长龙服务,适合有JS基础的同学学习。
- 立即学习 543次学习
-

- GO语言核心编程课程
- 本课程采用真实案例,全面具体可落地,从理论到实践,一步一步将GO核心编程技术、编程思想、底层实现融会贯通,使学习者贴近时代脉搏,做IT互联网时代的弄潮儿。
- 立即学习 516次学习
-

- 简单聊聊mysql8与网络通信
- 如有问题加微信:Le-studyg;在课程中,我们将首先介绍MySQL8的新特性,包括性能优化、安全增强、新数据类型等,帮助学生快速熟悉MySQL8的最新功能。接着,我们将深入解析MySQL的网络通信机制,包括协议、连接管理、数据传输等,让
- 立即学习 500次学习
-

- JavaScript正则表达式基础与实战
- 在任何一门编程语言中,正则表达式,都是一项重要的知识,它提供了高效的字符串匹配与捕获机制,可以极大的简化程序设计。
- 立即学习 487次学习
-

- 从零制作响应式网站—Grid布局
- 本系列教程将展示从零制作一个假想的网络科技公司官网,分为导航,轮播,关于我们,成功案例,服务流程,团队介绍,数据部分,公司动态,底部信息等内容区块。网站整体采用CSSGrid布局,支持响应式,有流畅过渡和展现动画。
- 立即学习 485次学习
-

- 含蓄的音响
- 这篇技术贴真是及时雨啊,太详细了,很有用,码起来,关注up主了!希望up主能多写Golang相关的文章。
- 2023-01-19 06:25:59
-
- 坦率的黄豆
- 太细致了,收藏了,感谢大佬的这篇技术贴,我会继续支持!
- 2023-01-18 21:21:54
-
- 大意的钻石
- 感谢大佬分享,一直没懂这个问题,但其实工作中常常有遇到...不过今天到这,帮助很大,总算是懂了,感谢作者大大分享文章内容!
- 2023-01-06 04:32:33