Go 实战单队列到优先级队列实现图文示例
来源:脚本之家
时间:2022-12-31 13:20:05 468浏览 收藏
本篇文章主要是结合我之前面试的各种经历和实战开发中遇到的问题解决经验整理的,希望这篇《Go 实战单队列到优先级队列实现图文示例》对你有很大帮助!欢迎收藏,分享给更多的需要的朋友学习~
优先级队列概述
队列,是数据结构中实现先进先出策略的一种数据结构。而优先队列则是带有优先级的队列,即先按优先级分类,然后相同优先级的再 进行排队。优先级高的队列中的元素会优先被消费。如下图所示:
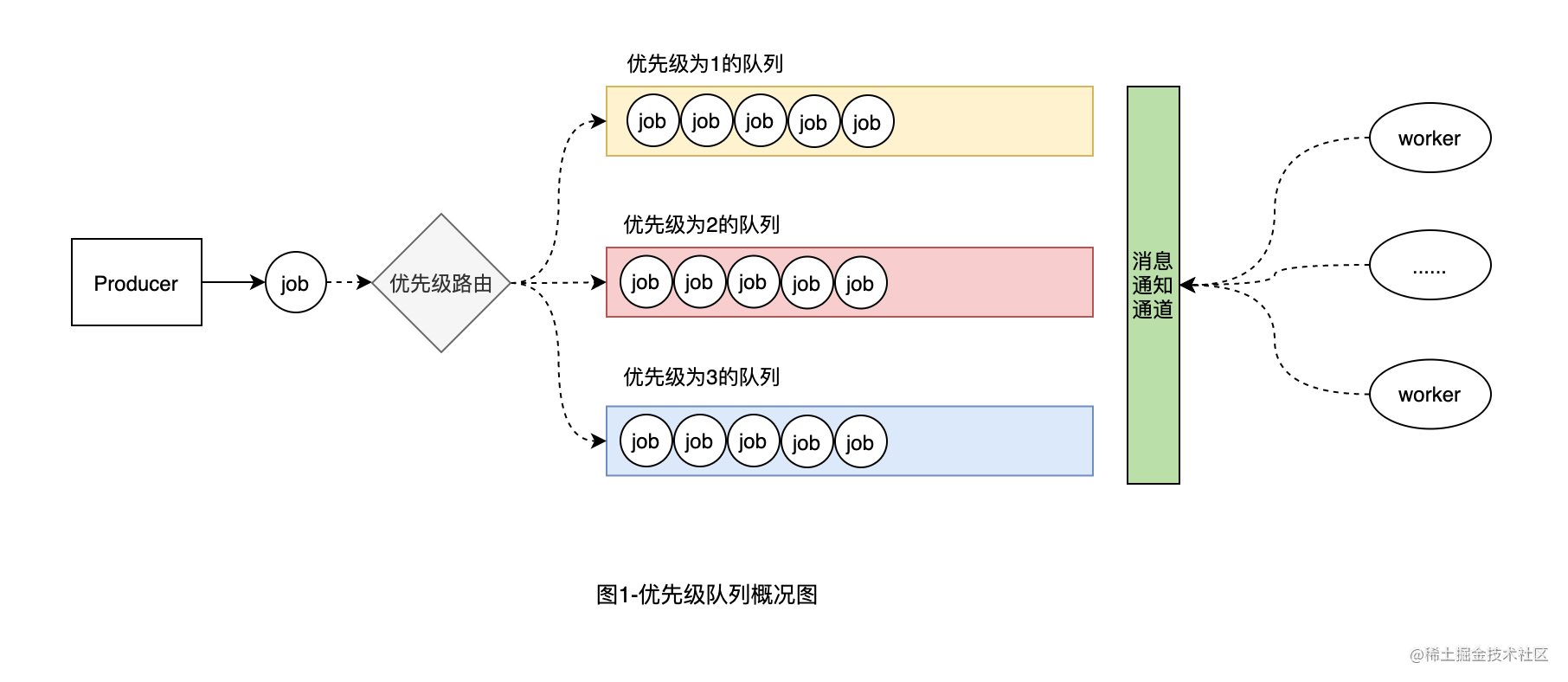
在Go中,可以定义一个切片,切片的每个元素代表一种优先级队列,切片的索引顺序代表优先级顺序,后面代码实现部分我们会详细讲解。
为什么需要优先级队列
先来看现实生活中的例子。银行的办事窗口,有普通窗口和vip窗口,vip窗口因为排队人数少,等待的时间就短,比普通窗口就会优先处理。同样,在登机口,就有贵宾通道和普通,同样贵宾通道优先登机。
在互联网中,当然就是请求和响应。使用优先级队列的作用是将请求按特定的属性划分出优先级,然后按优先级的高低进行优先处理。在研发服务的时候这里有个隐含的约束条件就是服务器资源(CPU、内存、带宽等)是有限的。如果服务器资源是无限的,那么也就不需要队列进行排队了,来一个请求就立即处理一个请求就好了。所以,为了在最大限度的利用服务器资源的前提下,将更重要的任务(优先级高的请求)优先处理,以更好的服务用户。
对于请求优先级的划分可以根据业务的特点根据价值高的优先原则来进行划分即可。例如可以根据是否是否是会员、是否是VIP会员等属性进行划分优先级。也可以根据是否是付费用户进行划分。在博客的业务中,也可以根据是否是大V的属性进行优先级划分。在互联网广告业务中,可以根据广告位资源价值高低来划分优先级。
优先级队列实现原理
01 四个角色
在完整的优先级队列中有四个角色,分别是优先级队列、工作单元、消费者worker、通知channel。
工作单元Job:队列里的元素。我们把每一次业务处理都封装成一个工作单元,该工作单元会进入对应的优先级队列进行排队,然后等待消费者worker来消费执行。优先级队列:按优先级划分的队列,用来暂存对应优先级的工作单元Job,相同优先级的工作单元会在同一个队列里。noticeChan通道:当有工作单元进入优先级队列排队后,会在通道里发送一个消息,以通知消费者worker从队列中获取元素(工作单元)进行消费。消费者worker:监听noticeChan,当监听到noticeChan有消息时,说明队列中有工作单元需要被处理,优先从高优先级队列中获取元素进行消费。
02 队列-消费者模式
根据队列个数和消费者个数,我们可以将队列-消费者模式分为单队列-单消费者模式、多队列(优先级队列)- 单消费者模式、多队列(优先级队列)- 多消费者模式。
我们先从最简单的单队列-单消费者模式实现,然后一步步演化成多队列(优先级队列)-多消费者模式。
03 单队列-单消费者模式实现
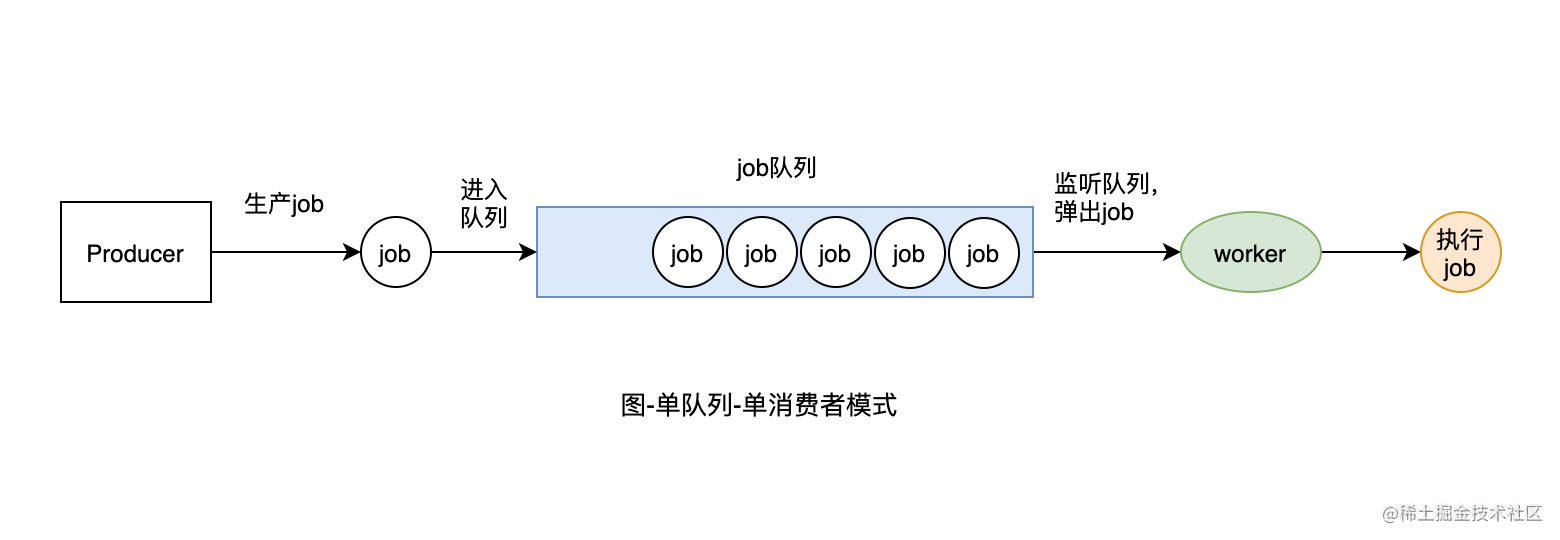
3.1 队列的实现
我们先来看下队列的实现。这里我们用Golang中的List数据结果来实现,List数据结构是一个双向链表,包含了将元素放到链表尾部、将头部元素弹出的操作,符合队列先进先出的特性。
好,我们看下具体的队列的数据结构:
type JobQueue struct {
mu sync.Mutex //队列的操作需要并发安全
jobList *list.List //List是golang库的双向队列实现,每个元素都是一个job
noticeChan chan struct{} //入队一个job就往该channel中放入一个消息,以供消费者消费
}
入队操作
/**
* 队列的Push操作
*/
func (queue *JobQueue) PushJob(job Job) {
queue.jobList.PushBack(job) //将job加到队尾
queue.noticeChan
到这里有同学就会问了,为什么不直接将job推送到Channel中,然后让消费者依次消费不就行了么?是的,单队列这样是可以的,因为我们最终目标是为了实现优先级的多队列,所以这里即使是单队列,我们也使用List数据结构,以便后续的演变。
还有一点,大家注意到了,这里入队操作时有一个 这样的操作:
queue.noticeChan
消费者监听的实际上不是队列本身,而是通道noticeChan。当有一个元素入队时,就往noticeChan通道中输入一条消息,这里是一个空结构体,主要作用就是通知消费者worker,队列里有要处理的元素了,可以从队列中获取了。 这个在后面演化成多队列以及多消费者模式时会很有用。
出队操作
根据队列的先进先出原则,是要获取队列的最先进入的元素。Golang中List结构体的Front()函数是获取链表的第一个元素,然后通过Remove函数将该元素从链表中移出,即得到了队列中的第一个元素。这里的Job结构体先不用关心,我们后面实现工作单元Job时,会详细讲解。
/**
* 弹出队列的第一个元素
*/
func (queue *JobQueue) PopJob() Job {
queue.mu.Lock()
defer queue.mu.Unlock()
/**
* 说明在队列中没有元素了
*/
if queue.jobList.Len() == 0 {
return nil
}
elements := queue.jobList.Front() //获取队里的第一个元素
return queue.jobList.Remove(elements).(Job) //将元素从队列中移除并返回
}
等待通知操作
上面我们提到,消费者监听的是noticeChan通道。当有元素入队时,会往noticeChan中输入一条消息,以便通知消费者进行消费。如果队列中没有要消费的元素,那么消费者就会阻塞在该通道上。
func (queue *JobQueue) WaitJob()
3.2 工作单元--Job的实现
一个工作单元就是一个要执行的任务。在系统中往往需要执行不同的任务,就是需要有不同类型的工作单元,但这些工作单元都有一组共同的执行流程。我们看下工作单元的类图。
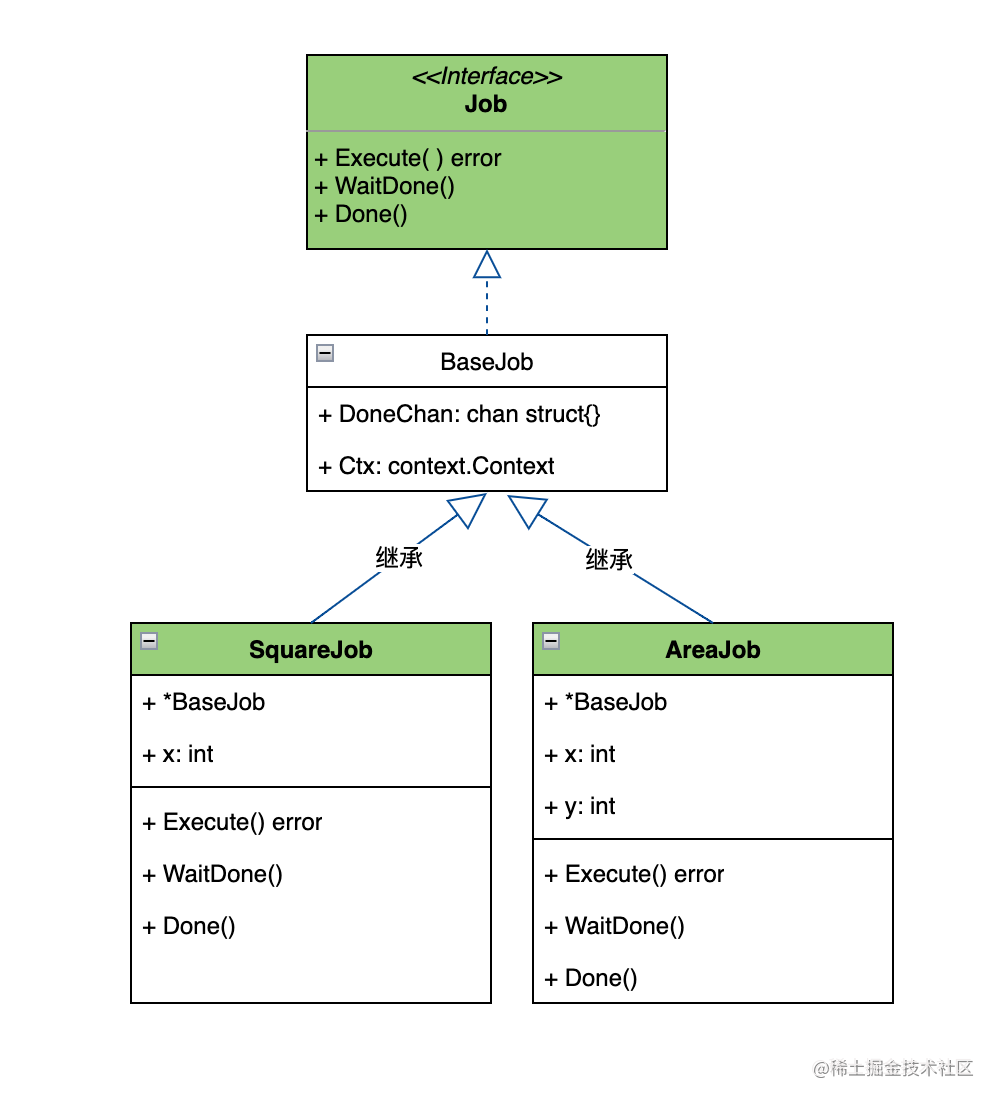
图-job类图
我们看下类图中的几个角色:
- Job接口:定义了所有Job要实现的方法。
- BaseJob类(结构体):定义了具体Job的基类。因为具体Job类中的有共同的属性和方法。所以抽象出一个基类,避免重复实现。但该基类对Execute方法没有实现,因为不同的工作单元有具体的执行逻辑。
- SquareJob和AreaJob类(结构体):是我们要具体实现的业务工作Job。主要是实现Execute的具体执行逻辑。根据业务的需要定义自己的工作Job和对应的Execute方法即可。
接下来,我们以计算一个int类型数字的平方的SquareJob为例来看下具体的实现。
- BaseJob结构体
首先看下该结构体的定义
type BaseJob struct {
Err error
DoneChan chan struct{} //当作业完成时,或者作业被取消时,通知调用者
Ctx context.Context
cancelFunc context.CancelFunc
}
在该结构体中,我们主要关注DoneChan字段就行,该字段是当具体的Job的Execute执行完成后,来通知调用者的。
再来看Done函数,该函数就是在Execute函数完成后,要关闭DoneChan通道,以解除Job的阻塞而继续执行其他逻辑。
/**
* 作业执行完毕,关闭DoneChan,所有监听DoneChan的接收者都能收到关闭的信号
*/
func (job *BaseJob) Done() {
close(job.DoneChan)
}
再来看WaitDone函数,该函数是当Job执行后,要等待Job执行完成,在未完成之前,DoneChan里没有消息,通过该函数就能将job阻塞,直到Execute中调用了Done(),以便解除阻塞。
/**
* 等待job执行完成
*/
func (job *BaseJob) WaitDone() {
select {
case
SquareJob结构体
type SquareJob struct {
*BaseJob
x int
}
从结构体的定义中可知,SquareJob嵌套了BaseJob,所以该结构体拥有BaseJob的所有字段和方法。在该结构体主要实现了Execute的逻辑:对x求平方。
func (s *SquareJob) Execute() error {
result := s.x * s.x
fmt.Println("the result is ", result)
return nil
}
3.3 消费者Worker的实现
Worker主要功能是通过监听队列里的noticeChan是否有需要处理的元素,如果有元素的话从队列里获取到要处理的元素job,然后执行job的Execute方法。
我们将该结构体定位为WorkerManager,因为在后面我们讲解多Worker模式时,会需要一个Worker的管理者,因此定义成了WorkerManager。
type WorkerManager struct {
queue *JobQueue
closeChan chan struct{}
}
StartWorker函数,只有一个for循环,不断的从队列中获取Job。获取到Job后,进行消费Job,即ConsumeJob。
func (m *WorkerManager) StartWork() error {
fmt.Println("Start to Work")
for {
select {
case
到这里,单队列-单消费者模式中各角色的实现就讲解完了。我们通过main函数将其关联起来。
func main() {
//初始化一个队列
queue := &JobQueue{
jobList: list.New(),
noticeChan: make(chan struct{}, 10),
}
//初始化一个消费worker
workerManger := NewWorkerManager(queue)
// worker开始监听队列
go workerManger.StartWork()
// 构造SquareJob
job := &SquareJob{
BaseJob: &BaseJob{
DoneChan: make(chan struct{}, 1),
},
x: 5,
}
//压入队列尾部
queue.PushJob(job)
//等待job执行完成
job.WaitDone()
print("The End")
}
04 多队列-单消费者模式
有了单队列-单消费者的基础,我们如何实现多队列-单消费者模式。也就是优先级队列。
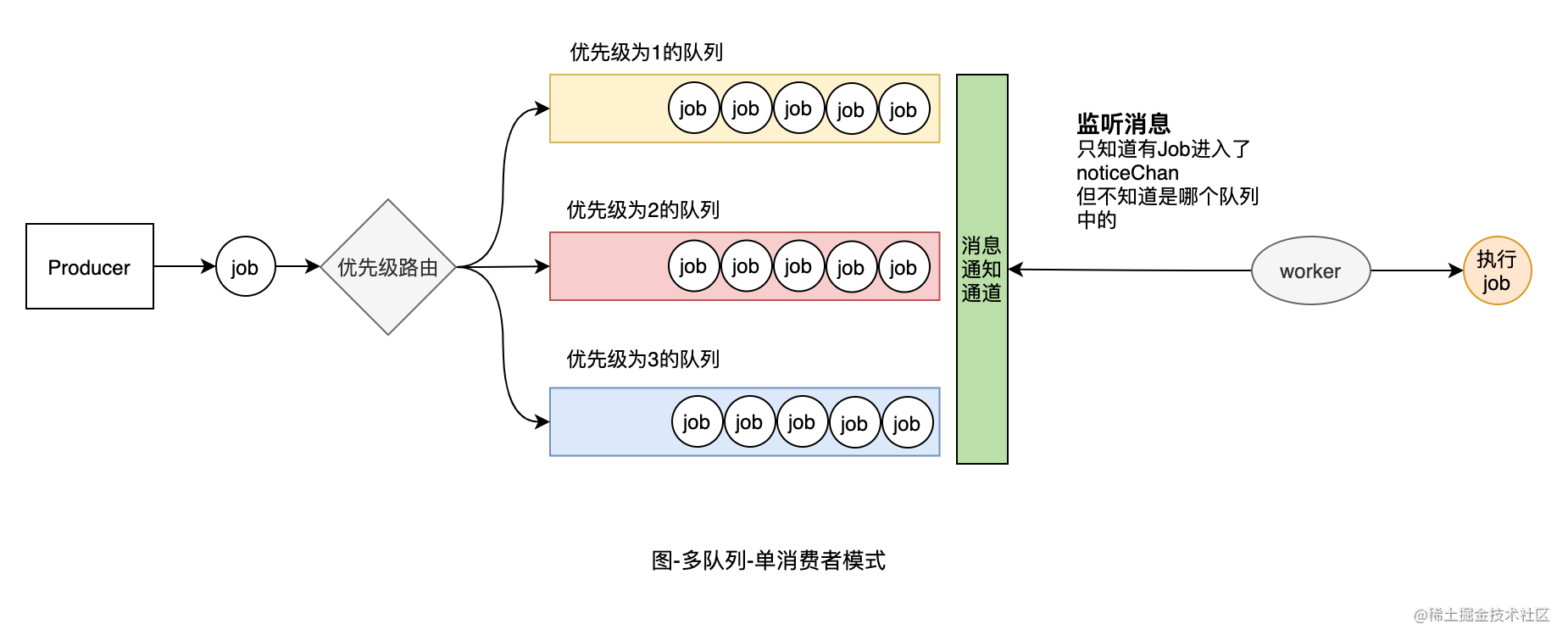
优先级的队列,实质上就是根据工作单元Job的优先级属性,将其放到对应的优先级队列中,以便worker可以根据优先级进行消费。我们要在Job结构体中增加一个Priority属性。因为该属性是所有Job都共有的,因此定义在BaseJob上更合适.
type BaseJob struct {
Err error
DoneChan chan struct{} //当作业完成时,或者作业被取消时,通知调用者
Ctx context.Context
cancelFunc context.CancelFunc
priority int //工作单元的优先级
}
我们再来看看多队列如何实现。实际上就是用一个切片来存储各个队列,切片的每个元素存储一个JobQueue队列元素即可。
var queues = make([]*JobQueue, 10, 100)
那各优先级的队列在切片中是如何存储的呢?切片索引顺序只代表优先级的高于低,不代表具体是哪个优先级。
什么意思呢?假设我们现在对目前的工作单元定义了1、4、7三个优先级。这3个优先级在切片中是按优先级从小到到依次存储在queues切片中的,如下图:
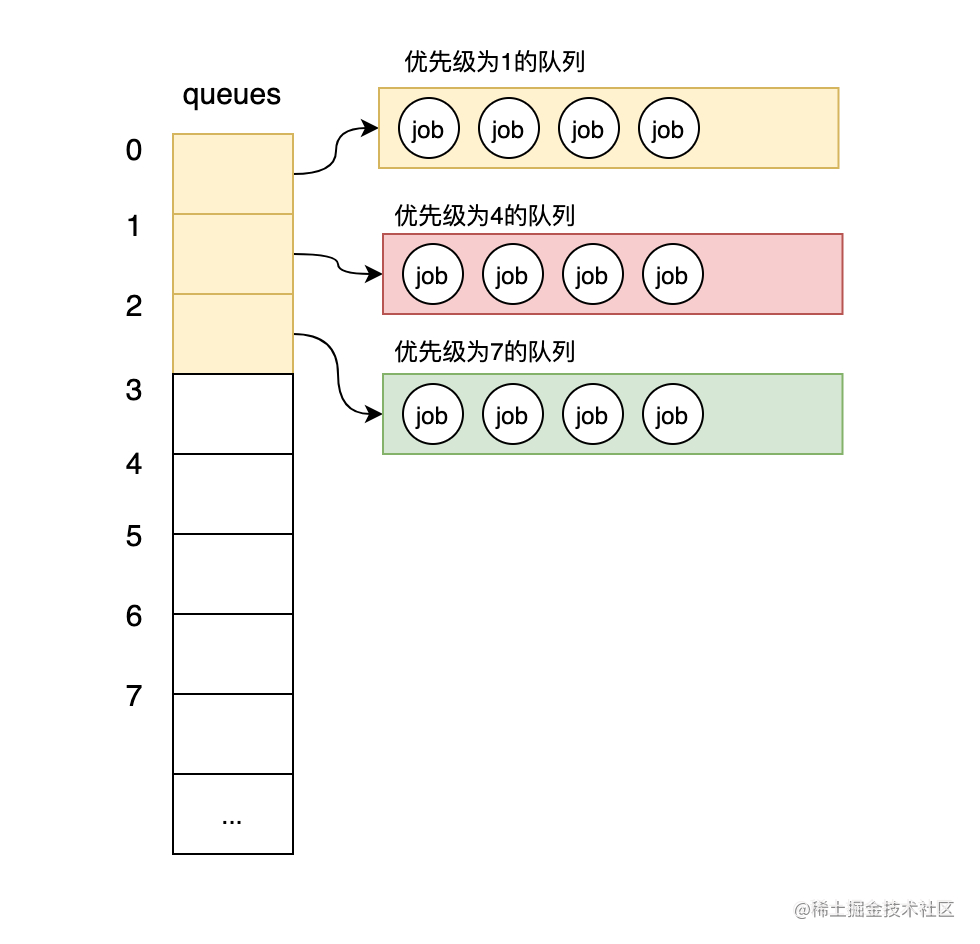
图-正确的切片存储的优先级
那为什么不让切片的索引就代表优先级,让优先级为1的队列存储在索引1处,优先级4的队列存储在索引4处,优先级7的队列存储在索引7处呢?如果这样存储的话,就会变成如下这样:
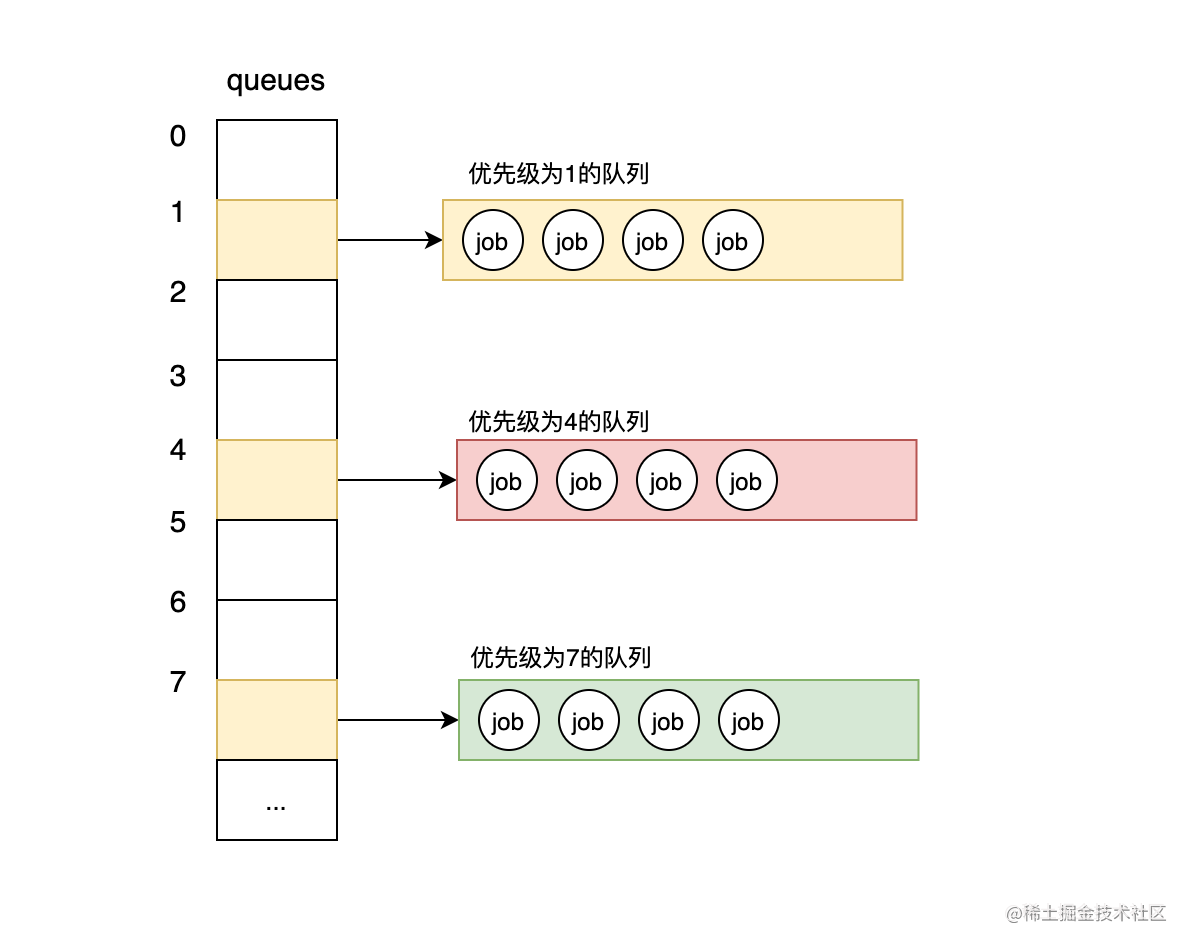
图4-直接使用索引作为优先级缺点
可见如果我们设定的优先级不是连续的,那么就会造成空间的浪费。所以,我们是将队列按优先级高低依次存放到了切片中。
那既然这样,当一个优先级的job来了之后,我该怎么知道该优先级的队列是存储在哪个索引中呢?我们用一个map来映射优先级和切片索引之间的关系。这样当一个工作单元Job入队的时候,以优先级为key,就可以查找到对应优先级的队列存储在切片的哪个位置了。如下图所示:
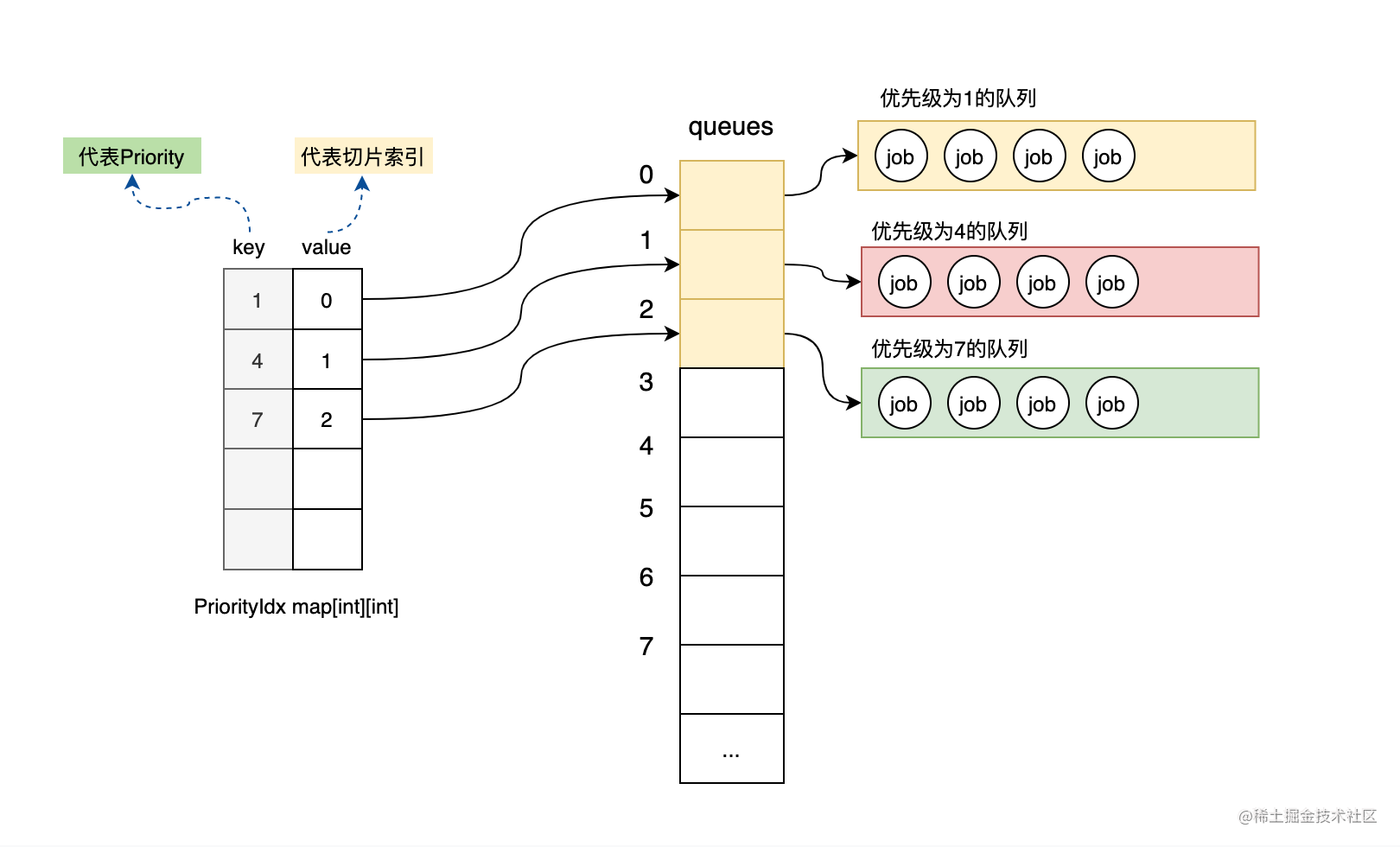
图-优先级和索引映射
代码定义:
var priorityIdx map[int][int]//该map的key是优先级,value代表的是queues切片的索引
好了,我们重新定义一下队列的结构体:
type PriorityQueue struct {
mu sync.Mutex
noticeChan chan struct{}
queues []*JobQueue
priorityIdx map[int]int
}
//原来的JobQueue会变成如下这样:
type JobQueue struct {
priority int //代表该队列是哪种优先级的队列
jobList *list.List //List是golang库的双向队列实现,每个元素都是一个job
}
这里我们注意到有以下几个变化:
JobQueue里多了一个Priority属性,代表该队列是哪个优先级别。noticeChan属性从JobQueue中移动到了PriorityQueue中。因为现在有多个队列,只要任意一个队列里有元素就需要通知消费者worker进行消费,因此消费者worker监听的是PriorityQueue中是否有元素,而在监听阶段不关心具体哪个优先级队列中有元素。
好了,数据结构定义完了,我们看看将工作单元Job推入队列和从队列中弹出Job又有什么变化。
优先级队列的入队操作
优先级队列的入队操作,就需要根据入队Job的优先级属性放到对应的优先级队列中,入队流程图如下:
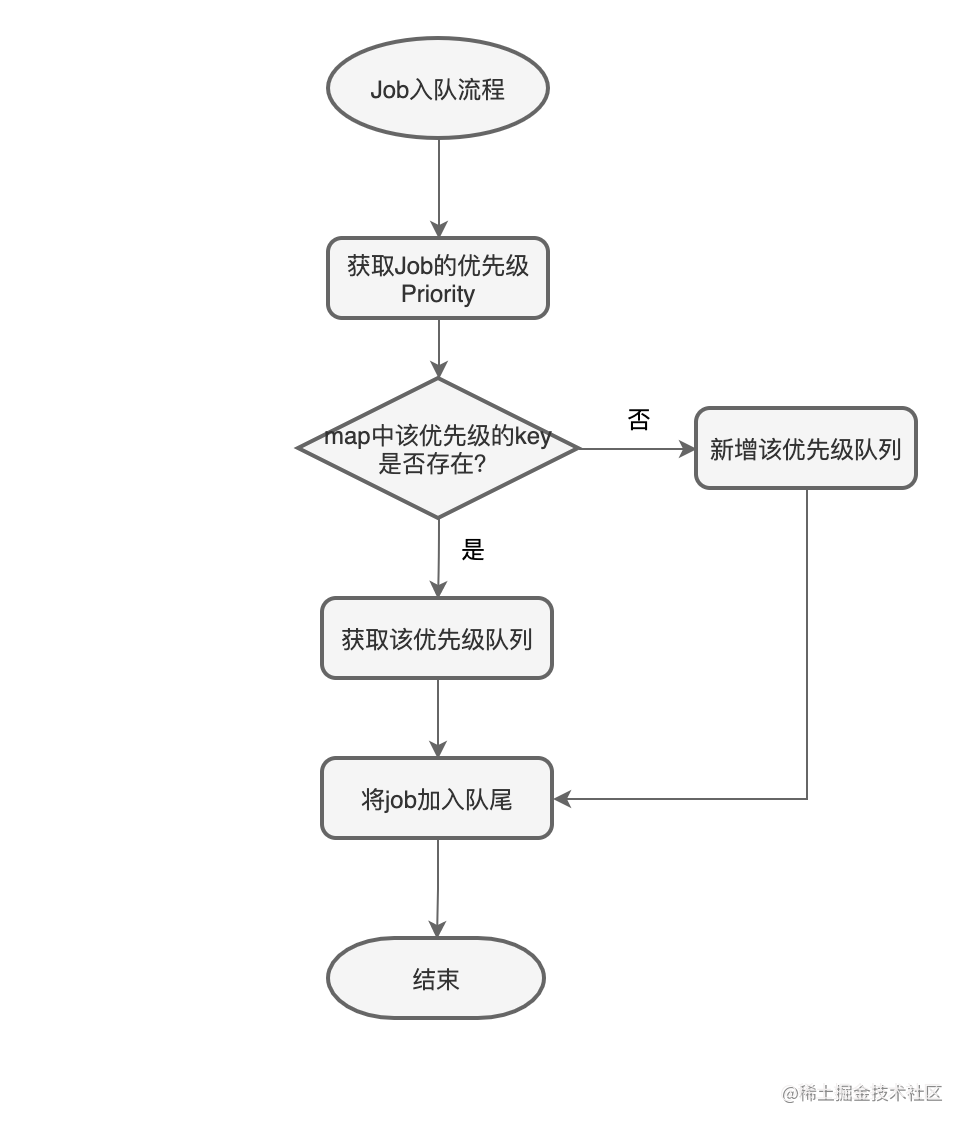
图-优先级队列入队流程
当一个Job加入队列的时候,有两种场景,一种是该优先级的队列已经存在,则直接Push到队尾即可。一种是该优先级的队列还不存在,则需要先创建该优先级的队列,然后再将该工作单元Push到队尾。如下是两种场景。
队列已经存在的场景
这种场景会比较简单。假设我们要插入优先级为7的工作单元,首先从映射表中查找7是否存在,发现对应关系是2,则直接找到切片中索引2的元素,即优先级为7的队列,将job加入即可。如下图。
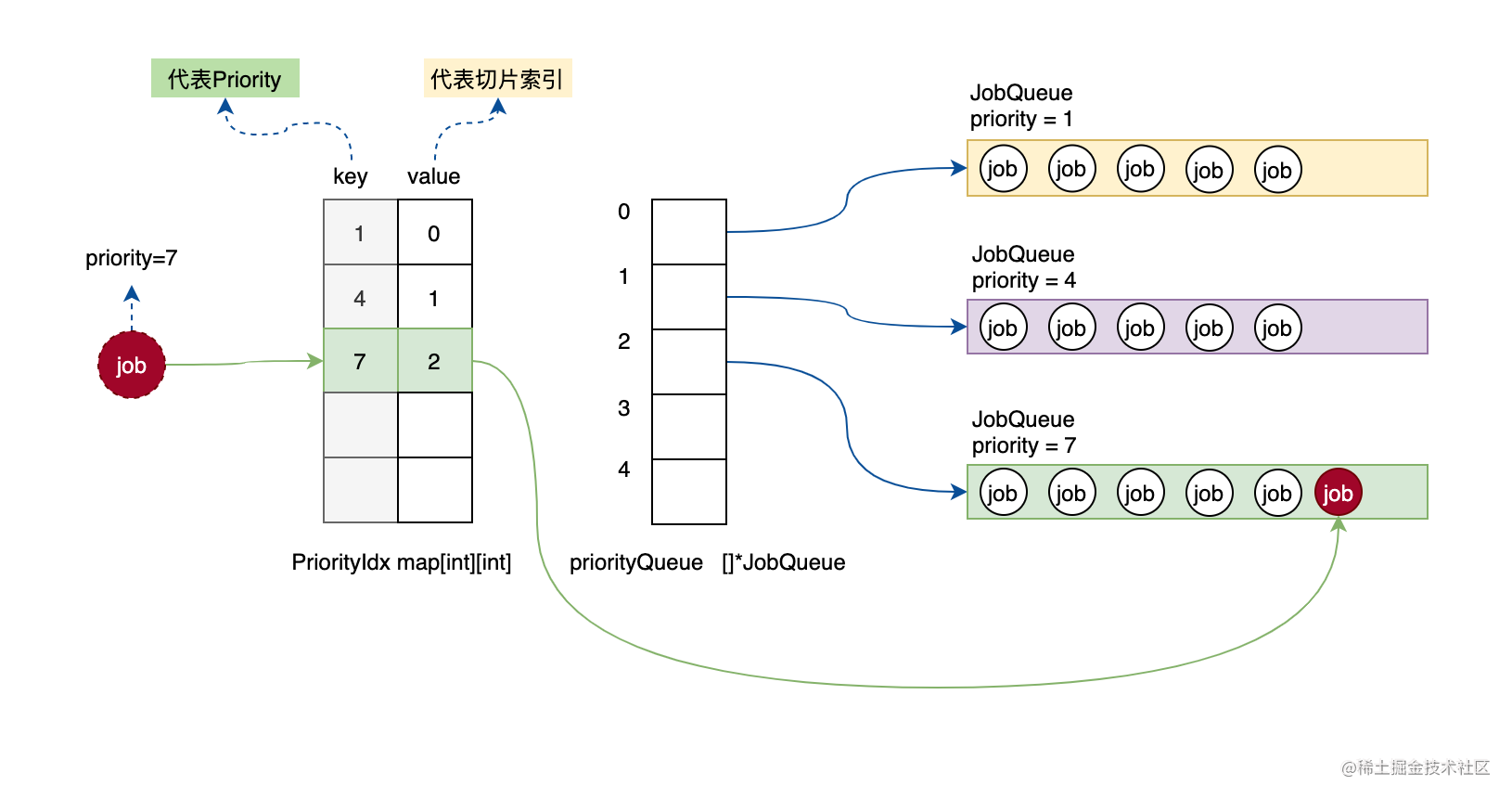
图-已存在队列插入
队列不存在的场景
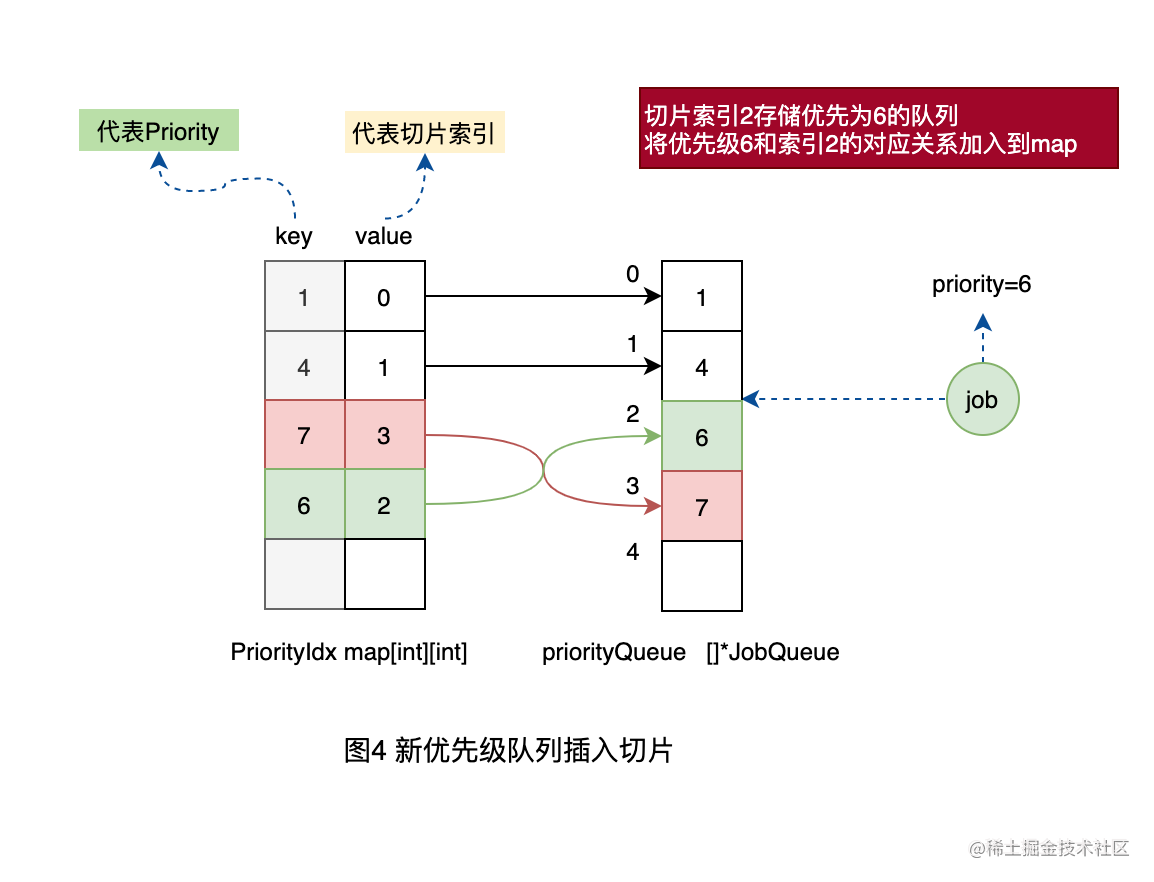
这种场景稍微复杂些,在映射表中找不到要插入优先级的队列的话,则需要在切片中插入一个优先级队列,而为了优先级队列在切片中也保持有序(保持有序就可以知道队列的优先级的高低了),则需要移动相关的元素。我们以插入优先级为6的工作单元为例来讲解。
1、首先,我们的队列有一个初始化的状态,存储了优先级1、4、7的队列。如下图。
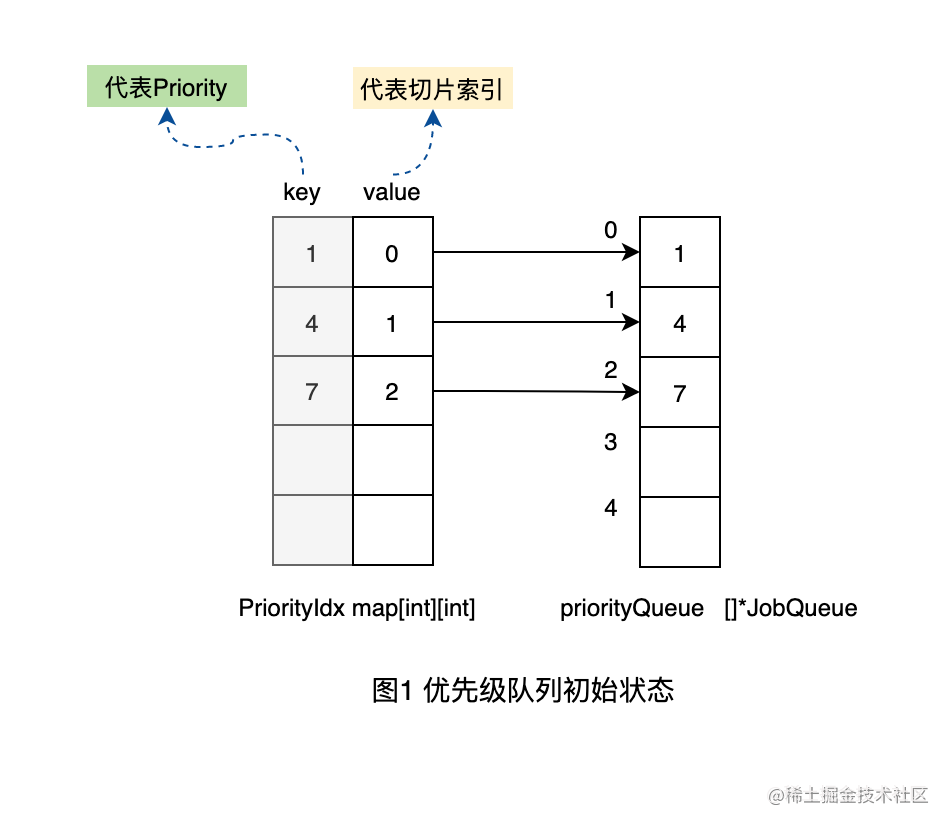
2、当插入优先级为6的工作单元时,发现在映射表中没有优先级6的映射关系,说明在切片中还没有优先级为6的队列的元素。所以需要在切片中依次查找到优先级6应该插入的位置在4和7之间,也就是需要存储在切片2的位置。
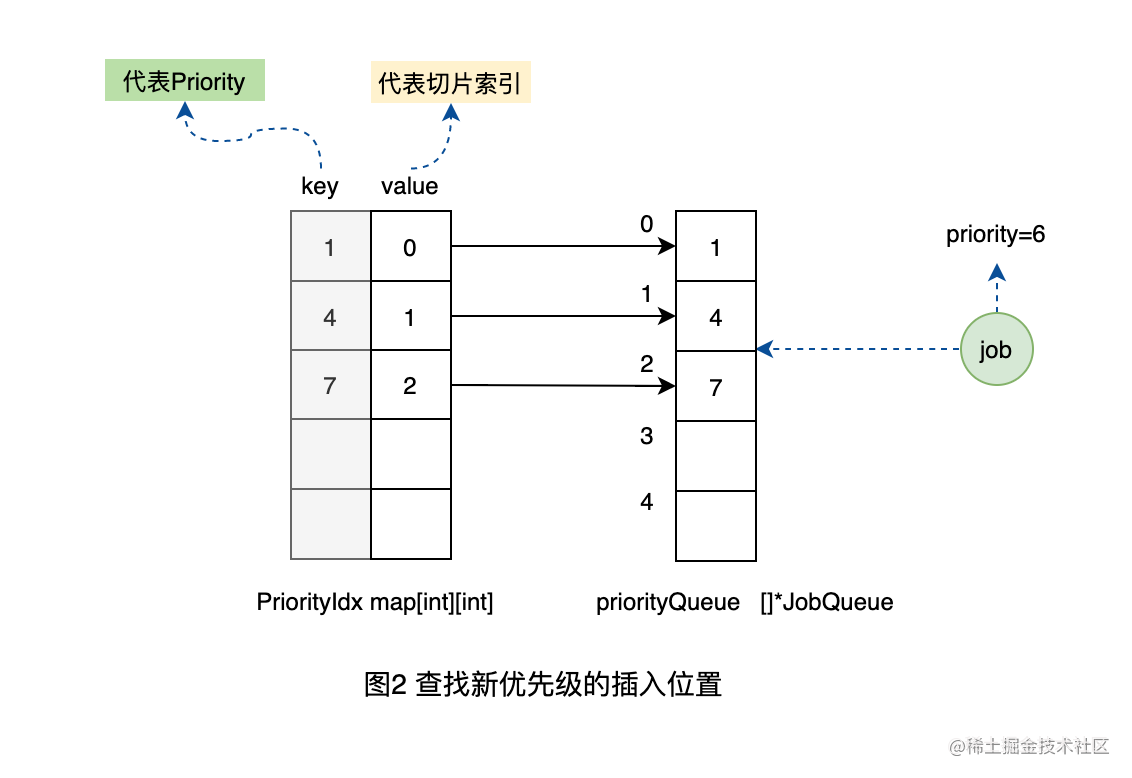
3、将原来索引2位置的优先级为7的队列往后移动到3,同时更新映射表中的对应关系。
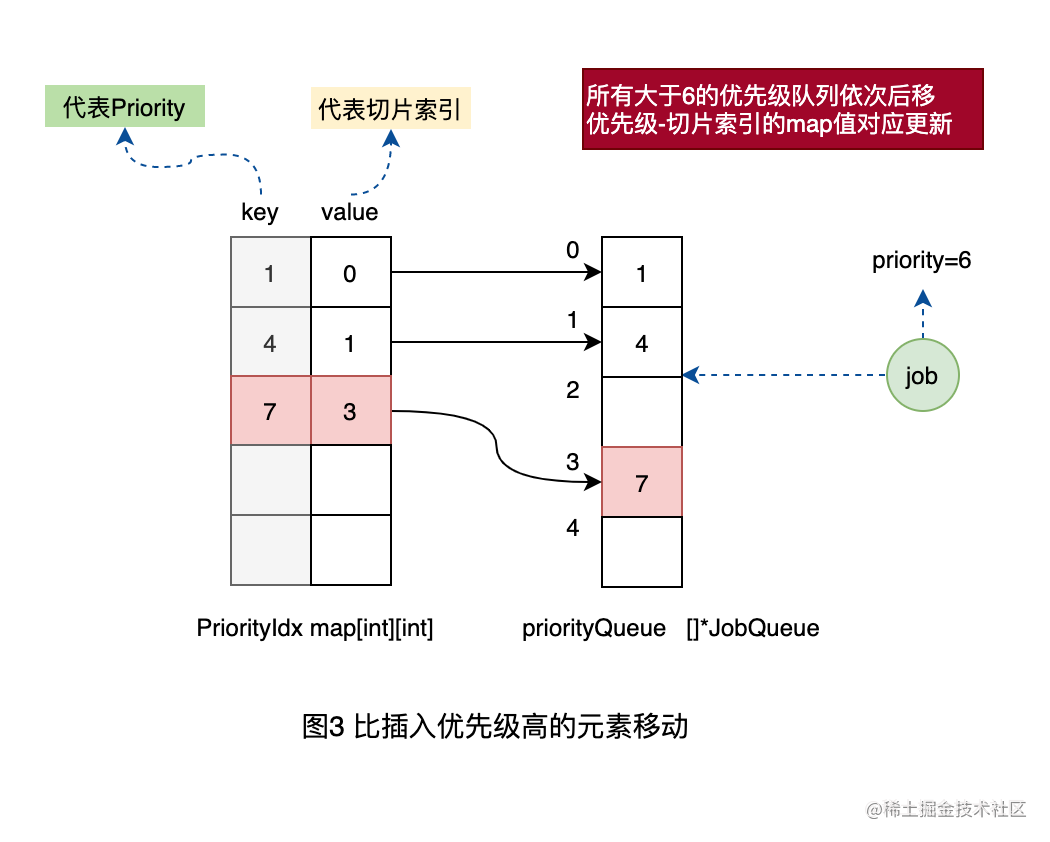
4、将优先级为6的工作单元插入到索引2的队列中,同时更新映射表中的优先级和索引的关系。
我们看下代码实现:
func (priorityQueue *PriorityQueue) Push(job Job) {
priorityQueue.mu.Lock()
defer priorityQueue.mu.Unlock()
//先根据job的优先级找要入队的队列
var idx int
var ok bool
//从优先级-切片索引的map中查找该优先级的队列是否存在
if idx, ok = priorityQueue.priorityIdx[job.Priority()]; !ok {
//如果不存在该优先级的队列,则需要初始化一个队列,并返回该队列在切片中的索引位置
idx = priorityQueue.addPriorityQueue(job.Priority)
}
//根据获取到的切片索引idx,找到具体的队列
queue := priority.queues[idx]
//将job推送到队列的队尾
queue.JobList.PushBack(job)
//队列job个数+1
priorityQueue.Size++
//如果队列job个数超过队列的最大容量,则从优先级最低的队列中移除工作单元
if priorityQueue.size > priorityQueue.capacity {
priorityQueue.RemoveLeastPriorityJob()
}else {
//通知新进来一个job
priorityQueue.noticeChan
代码中大部分也都做了注释,不难理解。这里我们来看下addPriorityQueue的具体实现:
func (priorityQueue *PriorityQueue) addPriorityQueue(priority int) int {
n := len(priorityQueue.queues)
//通过二分查找找到priority应插入的切片索引
pos := sort.Search(n, func(i int) bool {
return priority
最后,我们再来看一个实际的调用例子:
func main() {
//初始化一个队列
queue := &PriorityQueue{
noticeChan: make(chan struct{}, cap),
capacity: cap,
priorityIdx: make(map[int]int),
size: 0,
}
//初始化一个消费worker
workerManger := NewWorkerManager(queue)
// worker开始监听队列
go workerManger.StartWork()
// 构造SquareJob
job := &SquareJob{
BaseJob: &BaseJob{
DoneChan: make(chan struct{}, 1),
},
x: 5,
priority: 10,
}
//压入队列尾部
queue.PushJob(job)
//等待job执行完成
job.WaitDone()
print("The End")
}
05 多队列-多消费者模式
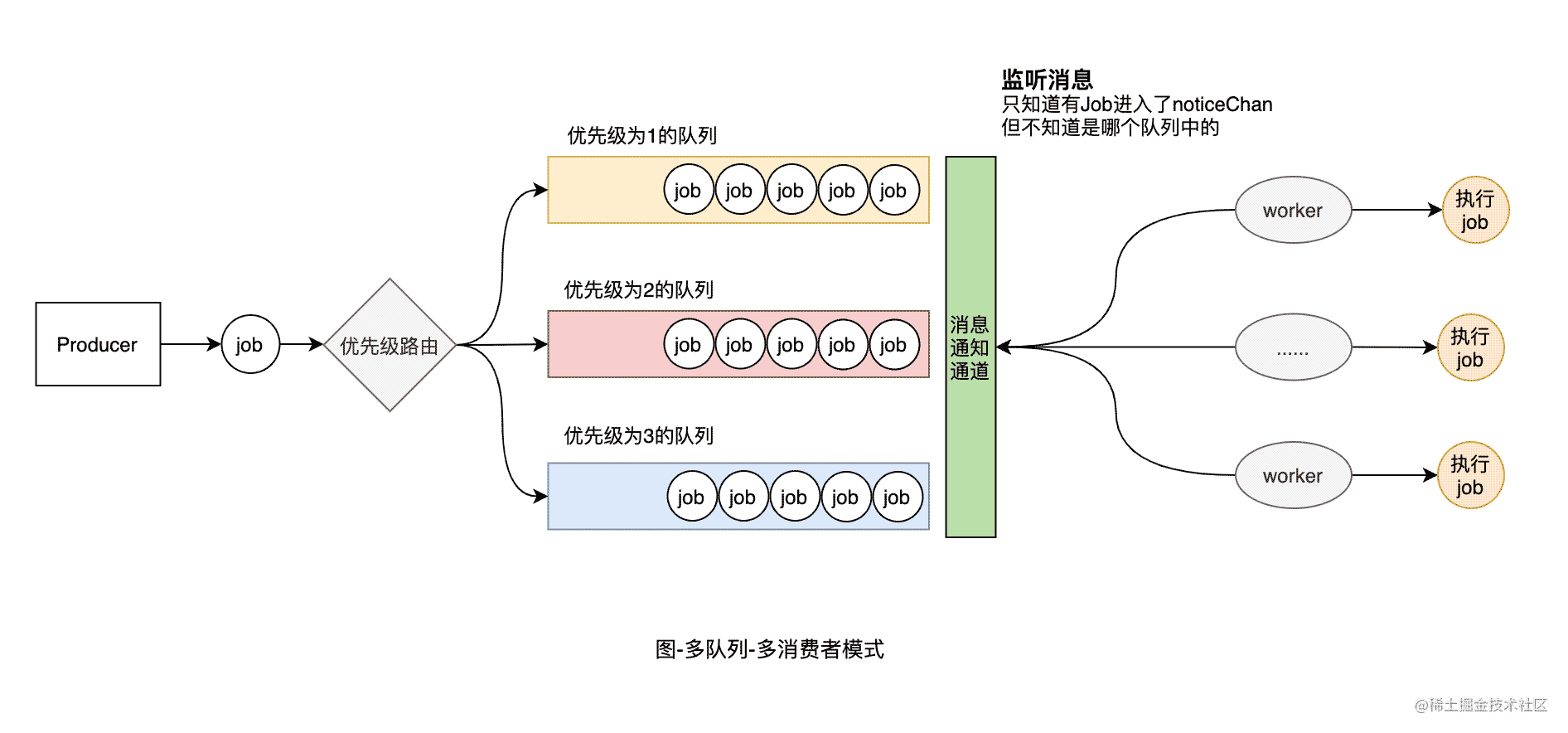
我们在多队列-单消费者的基础上,再来看看多消费者模式。也就是增加worker的数量,提高Job的处理速度。
我们再来看下worker的定义:
type WorkerManager struct {
queue *PriorityQueue
closeChans []chan struct{}
}
这里需要注意,closeChans变成了切片数组。因为我们每启动一个worker,就需要有一个关闭通道。
然后看StartWorker函数的实现:
func (m *WorkerManager) StartWork(n int) error {
fmt.Println("Start to Work")
for i := 0; i
这里需要注意的是,所有的worker都需要监听队列的noticeChan通道。测试的例子就留给读者自己了。
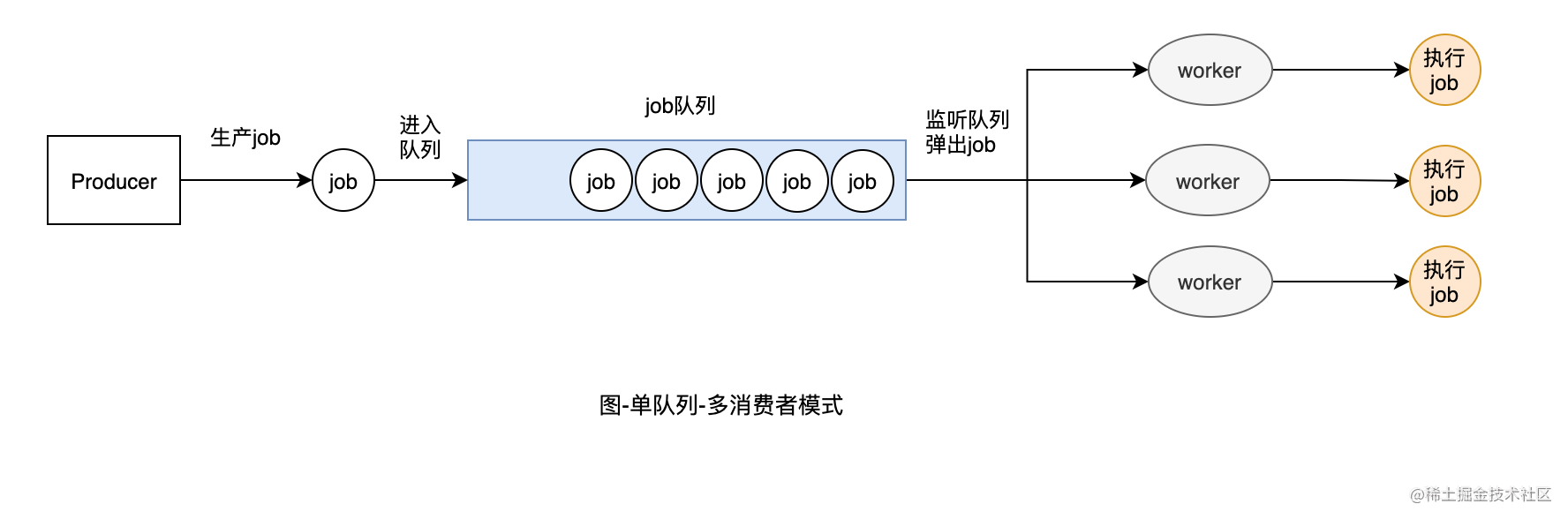
另外如下图的单队列-多消费者模式是多队列-多消费者模式的一个特例,这里就不再进行实现了。
总结
队列的作用可以用来控制流量,而优先级队列在兼顾流量控制的同时,还能将流量按优先级高低来进行处理。 本文中一些细节的并发加锁操作做了忽略,大家在实际应用中根据需要进行完善即可,更多关于Go 单队列优先级队列的资料请关注golang学习网其它相关文章!
以上就是《Go 实战单队列到优先级队列实现图文示例》的详细内容,更多关于golang的资料请关注golang学习网公众号!
-
321 收藏
-
426 收藏
-
311 收藏
-
497 收藏
-
425 收藏
-
Golang · Go教程 | 3天前 | 并发 · 闭包 · for range · 迁移 · Go教程 · Go 1.22 · Goroutine 闭包 循环变量 Go教程 Go 1.22 for range113 收藏
-
331 收藏
-
Golang · Go教程 | 3天前 | 单元测试 · 错误处理 · Go教程 · errors.Join · errors.Is · errors.Is Go错误处理 Go教程 errors.Join 多错误返回 批量校验352 收藏
-
Golang · Go教程 | 3天前 | Context · 超时控制 · Go教程 · http.Client · Transport · Go context 请求超时 Transport http.Client Client.Timeout ResponseHeaderTimeout218 收藏
-
Golang · Go教程 | 3天前 | 文件下载 · Go教程 · 审计日志 · 接口安全 · 路径穿越 · Go 文件下载 审计日志 HTTP接口 filepath.Clean 安全下载 路径穿越362 收藏
-
273 收藏
-
Golang · Go教程 | 3天前 | CI/CD · gitHub actions · Go教程 · 自托管 Runner · 持续集成 · Go 持续集成 CI Go test GitHub Actions self-hosted runner 自托管 runner340 收藏
-
124 收藏
-
Golang · Go教程 | 4天前 | HTTP · 文件下载 · Go教程 · Range请求 · ServeContent · 断点续传 Content-Range Go教程 HTTP Range ServeContent 206 Partial Content 视频拖动250 收藏
-
Golang · Go教程 | 4天前 | csv · Go教程 · 后端架构 · 流式响应 · 大文件导出 · 大文件下载 FLUSH CSV导出 Go教程 流式写出 csv.Writer rows.Next251 收藏
-
Golang · Go教程 | 4天前 | HTTP服务 · Go教程 · 后端开发 · 超时配置 · 服务稳定性 · net/http WriteTimeout HTTP超时 Go教程 ReadHeaderTimeout IdleTimeout140 收藏
-
Golang · Go教程 | 4天前 | 错误处理 · Context · 并发控制 · Go教程 · 并发控制 Go教程 context取消 context.WithCancelCause context.Cause342 收藏
-

- 前端进阶之JavaScript设计模式
- 设计模式是开发人员在软件开发过程中面临一般问题时的解决方案,代表了最佳的实践。本课程的主打内容包括JS常见设计模式以及具体应用场景,打造一站式知识长龙服务,适合有JS基础的同学学习。
- 立即学习 543次学习
-

- GO语言核心编程课程
- 本课程采用真实案例,全面具体可落地,从理论到实践,一步一步将GO核心编程技术、编程思想、底层实现融会贯通,使学习者贴近时代脉搏,做IT互联网时代的弄潮儿。
- 立即学习 516次学习
-

- 简单聊聊mysql8与网络通信
- 如有问题加微信:Le-studyg;在课程中,我们将首先介绍MySQL8的新特性,包括性能优化、安全增强、新数据类型等,帮助学生快速熟悉MySQL8的最新功能。接着,我们将深入解析MySQL的网络通信机制,包括协议、连接管理、数据传输等,让
- 立即学习 500次学习
-

- JavaScript正则表达式基础与实战
- 在任何一门编程语言中,正则表达式,都是一项重要的知识,它提供了高效的字符串匹配与捕获机制,可以极大的简化程序设计。
- 立即学习 487次学习
-

- 从零制作响应式网站—Grid布局
- 本系列教程将展示从零制作一个假想的网络科技公司官网,分为导航,轮播,关于我们,成功案例,服务流程,团队介绍,数据部分,公司动态,底部信息等内容区块。网站整体采用CSSGrid布局,支持响应式,有流畅过渡和展现动画。
- 立即学习 485次学习
-

- 俊逸的钢笔
- 这篇技术文章真是及时雨啊,太详细了,很有用,码住,关注博主了!希望博主能多写Golang相关的文章。
- 2023-04-10 14:34:04
-
- 爱笑的过客
- 很好,一直没懂这个问题,但其实工作中常常有遇到...不过今天到这,看完之后很有帮助,总算是懂了,感谢博主分享博文!
- 2023-02-27 22:58:24
-
- 坚定的故事
- 这篇博文真及时,太详细了,很有用,码起来,关注大佬了!希望大佬能多写Golang相关的文章。
- 2023-01-17 03:03:31
-
- 暴躁的含羞草
- 这篇技术文章出现的刚刚好,太详细了,很棒,码住,关注博主了!希望博主能多写Golang相关的文章。
- 2023-01-16 04:54:31
-
- 冷静的电源
- 很有用,一直没懂这个问题,但其实工作中常常有遇到...不过今天到这,看完之后很有帮助,总算是懂了,感谢博主分享博文!
- 2023-01-02 10:50:51