Golang如何读取单行超长的文本详解
来源:脚本之家
时间:2022-12-31 21:15:54 497浏览 收藏
本篇文章主要是结合我之前面试的各种经历和实战开发中遇到的问题解决经验整理的,希望这篇《Golang如何读取单行超长的文本详解》对你有很大帮助!欢迎收藏,分享给更多的需要的朋友学习~
前言:
最近在探索用Go来读取文件,读取文本时发现,对于单行超长的文本,我的Go代码无法处理。经过查阅才发现,Go提供的Scanner无法读取单行超长文本文件。我这里就来总结一下问题的发现和解决过程。
1.问题复现
首先注释main函数里面的内容,执行 CreateBigText 函数,它会创建一个含有3行内容的文件,第一行是一个长度超过100KB的行。然后解决main函数的注释,尝试执行代码,会发现只有一行错误信息:
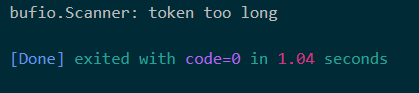
package main
import (
"bufio"
"bytes"
"log"
"os"
"strconv"
)
func main() {
file, err := os.Open("./read/test.txt")
if err != nil {
log.Fatal(err)
}
ReadBigText(file)
}
func ReadBigText(file *os.File) {
defer file.Close()
scanner := bufio.NewScanner(file)
for scanner.Scan() {
println(scanner.Text())
}
// 输出错误
println(scanner.Err().Error())
}
func CreateBigText() {
file, err := os.Create("./read/test.txt")
if err != nil {
log.Fatal(err)
}
defer file.Close()
data := make([]byte, 0, 32*1024)
buffer := bytes.NewBuffer(data)
// 构造一个大的单行数据
for i := 0; i
2.问题探究
让我们来探究一下这个问题的原因,首先看一下Scan()方法的注释,这个方法就是每次扫描到下一个token,然后就可以通过获取字节或者文本的方法来获取扫描过的token。如果它返回值是false,就会返回扫描期间遇到的错误,除了io.EOF.
Scan advances the Scanner to the next token, which will then be available through the Bytes or Text method. It returns false when the scan stops, either by reaching the end of the input or an error. After Scan returns false, the Err method will return any error that occurred during scanning, except that if it was io.EOF, Err will return nil. Scan panics if the split function returns too many empty tokens without advancing the input. This is a common error mode for scanners.
所以Scan()和Text()函数是这样结合起来使用的,首先Scan()会扫描出一个token,然后Text()将其转成文本(或者其它方法转成字节),循环执行这种操作就可以按行读取一个文件。
通过阅读Scan()函数的源码,我们可以发现这样一个判断,如果buf的长度大于了最大token长度,那就会报错,见下图。
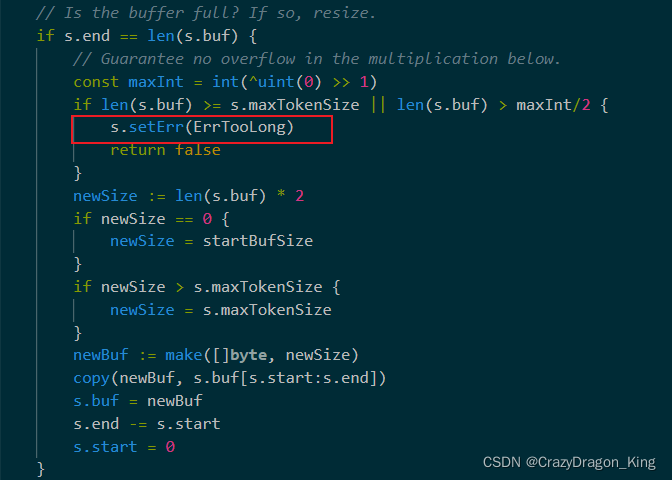
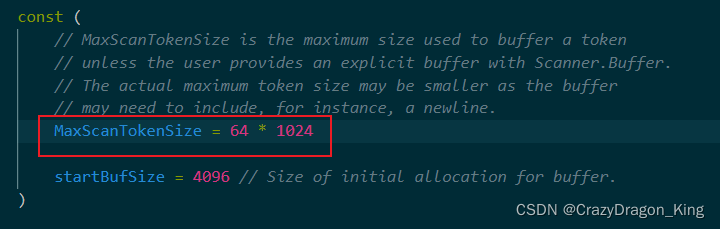
继续查找,可以看到最大长度已经定义好了,它的长度是 64*1024 byte,即64KB,所以一行文本超过了这个最大长度,那么就会报错!
3.问题解决
其实大部分情况下我们都应该使用Scan()函数结合Text()或者Bytes()函数来读取文件的,这个也是官方推荐的,因为它们是 high-level 方法,用起来很方便。但是如果我们有一些极端的情况,例如单行超过64KB,那么怎么办呢?(这种情况是很少的,但是又有可能会遇到这种需求的,例如文件里面存储了一串Base64编码)
这里可以这样来使用,这个方法不会受到64KB的限制,ReaderString方法会按照指定的定界符来读取一个完整的行,返回值是字符串和读取遇到的错误。如果想要读取返回值为字节的话,可以使用 ReadBytes 方法。
func ReadBigText(file *os.File) {
defer file.Close()
reader := bufio.NewReader(file)
for {
line, err := reader.ReadString('\n')
if err != nil {
log.Fatal(err)
}
fmt.Printf("%d %s", len(line), line)
}
}
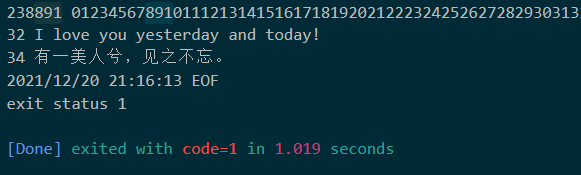
通过阅读源码可知,其实这个方法也是会遇到行太长的问题,只不过它忽略了这种情况。
ErrBufferFull就是这个缓冲区溢出错误。
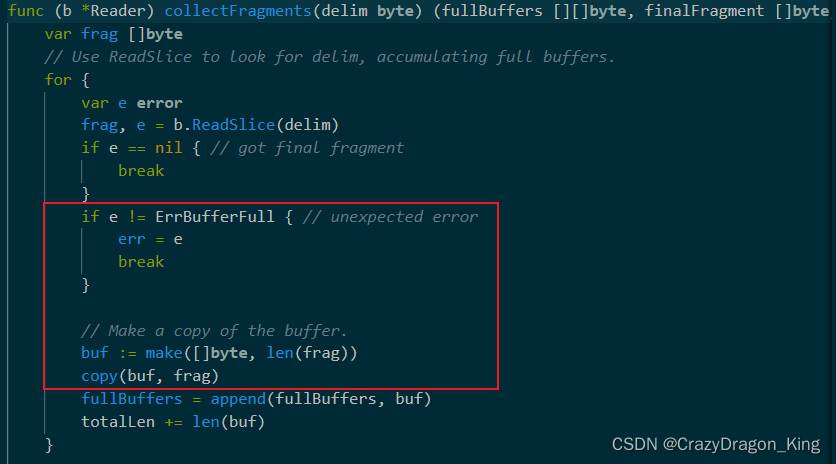
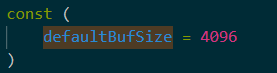
我们继续进入内容其实也可以知道,它默认的缓冲区大小是4KB。
4.扩展
上面都说相对高层的方法,我们来看一下相对底层的方法。
ReadLine is a low-level line-reading primitive. Most callers should use ReadBytes('\n') or ReadString('\n') instead or use a Scanner.
ReadLine是读取一行,但是它是一个 low-level 方法,它会返回三个值:[]byte、isPrefix bool和err error。
其中最令人好奇的是第二个参数,它如果是true,则表示当前行没有读取完毕,但是缓冲区满了,可以看下面这段注释。
If the line was too long for the buffer then isPrefix is set and the beginning of the line is returned. The rest of the line will be returned from future calls.
func ReadBigText(file *os.File) {
defer file.Close()
reader := bufio.NewReader(file)
for {
bline, isPrefix, err := reader.ReadLine()
if err == io.EOF {
break // 读取到文件结束才退出
}
// 读取到超长行,即单行超过4k字节,直接写入文件,不对此行做处理
if isPrefix {
fmt.Print(string(bline))
continue
}
fmt.Println(string(bline))
}
}
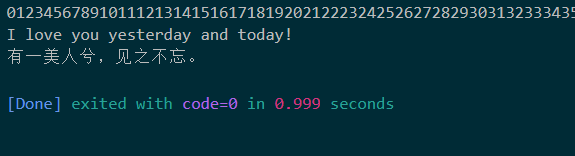
不过需要注意这个方法读取出来的数据是不包括换行符的,所以我是用的println打印输出的。
如果你也去看了 ReadString、ReadBytes 和 ReadLine 方法,会发现两种都依赖于一个底层的方法——ReadSlice方法。这个方法很原始,一般不会直接使用它。如果它遇到了超长行,它就会直接返回读取到的字节和一个ErrBufferFull,那这样我们就可以根据这个错误来继续读取数据了。这种方式还是相对麻烦了一些,不过如果你可以理解的话,对于上面的方法也就不是问题了。学习嘛,还是有必要一探究竟的。不过阅读源码感觉有些还是理解起来很困难,特别是这些英语注释,不过也能看一个七七八八了。还不行的话,那就再借助一些翻译软件,不过我个人觉得提高自己的英语能力还是非常必要的。
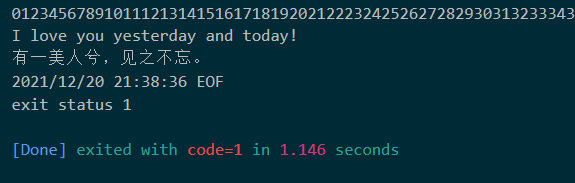
func ReadBigText(file *os.File) {
defer file.Close()
reader := bufio.NewReader(file)
for {
byt, err := reader.ReadSlice('\n')
if err != nil {
if err == bufio.ErrBufferFull {
fmt.Print(string(byt))
continue
}
log.Fatal(err)
}
fmt.Print(string(byt))
}
}
总结
终于介绍完啦!小伙伴们,这篇关于《Golang如何读取单行超长的文本详解》的介绍应该让你收获多多了吧!欢迎大家收藏或分享给更多需要学习的朋友吧~golang学习网公众号也会发布Golang相关知识,快来关注吧!
-
133 收藏
-
184 收藏
-
465 收藏
-
435 收藏
-
339 收藏
-
Golang · Go教程 | 4小时前 | go · net/url · url · HTTP客户端 · 路径转义 · Go教程 url.JoinPath PathEscape RawPath URL拼接354 收藏
-
261 收藏
-
334 收藏
-
469 收藏
-
395 收藏
-
270 收藏
-
Golang · Go教程 | 1天前 | JSON · 基准测试 · go · 性能优化 · 内存分配 encoding/json json.RawMessage json.Decoder Go JSON206 收藏
-
151 收藏
-
351 收藏
-
427 收藏
-
Golang · Go教程 | 2天前 | golang · HTTP · 安全 · Go教程 · net/http · 接口防护 · net/http 请求超时 MaxBytesReader Go HTTP 请求体限制 内存防护173 收藏
-
405 收藏
-

- 前端进阶之JavaScript设计模式
- 设计模式是开发人员在软件开发过程中面临一般问题时的解决方案,代表了最佳的实践。本课程的主打内容包括JS常见设计模式以及具体应用场景,打造一站式知识长龙服务,适合有JS基础的同学学习。
- 立即学习 543次学习
-

- GO语言核心编程课程
- 本课程采用真实案例,全面具体可落地,从理论到实践,一步一步将GO核心编程技术、编程思想、底层实现融会贯通,使学习者贴近时代脉搏,做IT互联网时代的弄潮儿。
- 立即学习 516次学习
-

- 简单聊聊mysql8与网络通信
- 如有问题加微信:Le-studyg;在课程中,我们将首先介绍MySQL8的新特性,包括性能优化、安全增强、新数据类型等,帮助学生快速熟悉MySQL8的最新功能。接着,我们将深入解析MySQL的网络通信机制,包括协议、连接管理、数据传输等,让
- 立即学习 500次学习
-

- JavaScript正则表达式基础与实战
- 在任何一门编程语言中,正则表达式,都是一项重要的知识,它提供了高效的字符串匹配与捕获机制,可以极大的简化程序设计。
- 立即学习 487次学习
-

- 从零制作响应式网站—Grid布局
- 本系列教程将展示从零制作一个假想的网络科技公司官网,分为导航,轮播,关于我们,成功案例,服务流程,团队介绍,数据部分,公司动态,底部信息等内容区块。网站整体采用CSSGrid布局,支持响应式,有流畅过渡和展现动画。
- 立即学习 485次学习