Go语言网络爬虫概述
来源:云海天教程
时间:2022-12-31 08:55:00 138浏览 收藏
亲爱的编程学习爱好者,如果你点开了这篇文章,说明你对《Go语言网络爬虫概述》很感兴趣。本篇文章就来给大家详细解析一下,主要介绍一下网络爬虫,希望所有认真读完的童鞋们,都有实质性的提高。
简单来说,网络爬虫是互联网终端用户的模仿者。它模仿的主要对象有两个,一个是坐在计算器前使用网络浏览器访问网络内容的人类用户,另一个就是网络浏览器。网络爬虫会模仿人类用户输入某个网站的网络地址,并试图访问该网站上的内容,还会模仿网络浏览器根据给定的网络地址去下载相应的内容。这里所说的内容可以是 HTML 页面、图片文件、音视频数据流,等等。
在下载到对应的内容之后,网络爬虫会根据预设的规则对它进行分析和筛选。这些筛选岀的部分会马上得到特定的处理。与此同时,网络爬虫还会像人类用户点击网页中某个他感兴趣的链接那样,继续访问和下载相关联的其他内容,然后再重复上述步骤,直到满足停止的条件。
如上所述,网络爬虫应该根据使用者的意愿自动下载、分析、筛选、统计以及存储指定的网络内容。注意,这里的关键词是“自动”和“根据意愿”。“自动”的含义是,网络爬虫在启动后自己完成整个爬取过程而无需人工干预,并且还能够在过程结束之后自动停止。而“根据意愿”则是说,网络爬虫最大限度地允许使用者对其爬取过程进行定制。
乍一看,要做到自动爬取貌似并不困难。我们只需让网络爬虫根据相关的网络地址不断地下载对应的内容即可。但是,窥探其中就可以发现,这里有很多细节需要我们进行特别处理,如下所示。
有效网络地址的发现和提取。有效网络地址的边界定义和检查。重复的网络地址的过滤。
在这些细节当中,有的是比较容易处理的,而有的则需要额外的解决方案。例如,我们都知道,基于 HTML 的网页中可以包含代表按钮的 button 标签。
让网络浏览器在终端用户点击按钮的时候加载并显示另一个网页可以有很多种方法,其中,非常常用的一种方法就是为该标签添加 onclick 属性并把一些 JavaScript 语言的代码作为它的值。
虽然这个方法如此常用,但是我们要想让网络爬虫可以从中提取出有效的网络地址却是比较 困难的,因为这涉及对JavaScript程序的理解。JavaScript代码的编写方法繁多,要想让 网络爬虫完全理解它们,恐怕就需要用到某个JavaScript程序解析器的 Go语言实现了。
另一方面,由于互联网对人们生活和工作的全面渗透,我们可以通过各种途径找到各式各样的网络爬虫实现,它们几乎都有着复杂而又独特的逻辑。这些复杂的逻辑主要针对如下几个方面。
在根据网络地址组装 HTTP 请求时,需要为其设定各种各样的头部 (Header) 和主体 (Body)。对网页中的链接和内容进行筛选时需要用到的各种条件,这里所说的条件包括提取条件、过滤条件和分类条件,等等。处理筛选出的内容时涉及的各种方式和步骤。
这些逻辑绝大多数都与网络爬虫使用者当时的意愿有关。换句话说,它们都与具体的使用目的有着紧密的联系。也许它们并不应该是网络爬虫的核心功能,而应该作为扩展功能或可定制的功能存在。
因此,我想我们更应该编写一个容易被定制和扩展的网络爬虫框架,而非一个满足特定爬取目的的网络爬虫,这样才能使这个程序成为一个可适用于不同应用场景的通用工具。
既然如此,接下来我们就要搞清楚该程序应该或可以做哪些事,这也能够让我们进一步明确它的功能、用途和意义。
功能需求和分析
概括来讲,网络爬虫框架会反复执行如下步骤直至触碰到停止条件。1) “下载器”
下载与给定网络地址相对应的内容。其中,在下载“请求”的组装方面,网络爬虫框架为使用者尽量预留出定制接口。使用者可以使用这些接口自定义“请求”的组装方法。2) “分析器”
分析下载到的内容,并从中筛选出可用的部分(以下称为“条目”)和需要访问的新网络地址。其中,在用于分析和筛选内容的规则和策略方面,应该由网络爬虫框架提供灵活的定制接口。换句话说,由于只有使用者自己才知道他们真正想要的是什么,所以应该允许他们对这些规则和策略进行深入的定制。网络爬虫框架仅需要规定好定制的方式即可。
3) “分析器”
把筛选出的“条目”发送给“条目处理管道”。同时,它会把发现的新网络地址和其他一些信息组装成新的下载“请求”,然后把这些请求发送给“下载器”。在此步骤中,我们会过滤掉一些不符合要求的网络地址,比如忽略超出有效边界的网络地址。你可能已经注意到,在这几个步骤中,我使用引号突出展示了几个名词,即下载器、请求、分析器、条目和条目处理管道,其中,请求和条目都代表了某类数据,而其他 3 个名词则代表了处理数据的子程序(可称为处理模块或组件)。
它们与前面已经提到过的网络内容(或称对请求的响应)共同描述了数据在网络爬虫程序中的流转方式。下图演示了起始于首次请求的数据流程图。
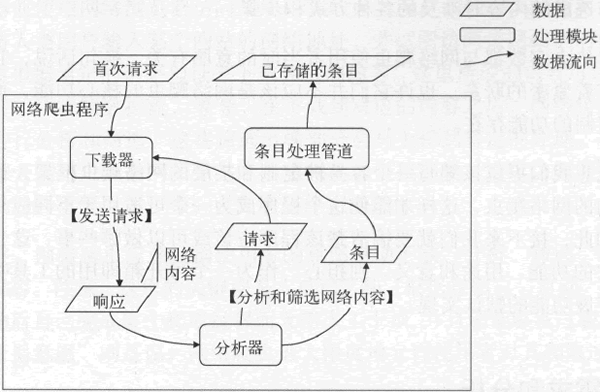
图:起始于首次请求的数据流程图
从上图中,我们可以清晰地看到每一个处理模块能够接受的输入和可以产生的输出。实际上,我们将要编写的网络爬虫框架就会以此为依据形成几个相对独立的子程序。
当然,为了维护它们的运行和协作的有效性,框架中还会存在其他一些子程序。关于它们,我会在后面陆续予以说明。
这里,我再次强调一下网络爬虫框架与网络爬虫实现的区别。作为一个框架,该程序在每个处理模块中给予使用者尽量多的定制方法,而不去涉及各个处理步骤的实现细节。
另外,框架更多地考虑使用者自定义的处理步骤在执行期间可能发生的各种情况和问题,并注意对这些问题的处理方式,这样才能在易于扩展的同时保证框架的稳定性。这方面的思考和策略会体现在该网络爬虫框架的各阶段设计和编码实现之中。
下面我就根据上述分析对这一程序进行总体设计。
总体设计
通过上图可知,网络爬虫框架的处理模块有 3 个:下载器、分析器和条目处理管道。再加上调度和协调这些处理模块运行的控制模块,我们就可以明晰该框架的模块划分了。我把这里提到的控制模块称为调度器。下面是这 4 个模块各自承担的职责。1) 下载器
接受请求类型的数据,并依据该请求获得 HTTP 请求;将 HTTP 请求发送至与指定的网络地址对应的远程服务器;在 HTTP 请求发送完毕之后,立即等待相应的 HTTP 响应的到来;在收到 HTTP 响应之后,将其封装成响应并作为输出返回给下载器的调用方。其中,HTTP 客户端程序可以由网络爬虫框架的使用方自行定义。另外,若在该子流程执行期间发生了错误,应该立即以适当的方式告知使用方。对于其他模块来讲,也是这样。
2) 分析器
接受响应类型的数据,并依据该响应获得 HTTP 响应;对该 HTTP 响应的内容进行检查,并根据给定的规则进行分析、筛选以及生成新的请求或条目;将生成的请求或条目作为输出返回给分析器的调用方。在分析器的职责中,我可以想到的能够留给网络爬虫框架的使用方自定义的部分并不少。例如,对 HTTP 响应的前期检查、对内容的筛选,以及生成请求和条目的方式,等等。不过,我在后面会对这些可以自定义的部分进行一些取舍。
3) 条目处理管道
接受条目类型的数据,并对其执行若干步骤的处理;条目处理管道中可以产出最终的数据;这个最终的数据可以在其中的某个处理步骤中被持久化(不论是本地存储还是发送给远程的存储服务器)以备后用。我们可以把这些处理步骤的具体实现留给网络爬虫框架的使用方自行定义。这样,网络爬虫框架就可以真正地与条目处理的细节脱离开来。网络爬虫框架丝毫不关心这些条目怎样被处理和持久化,它仅仅负责控制整体的处理流程。我把负责单个处理步骤的程序称为条目处理器。
条目处理器接受条目类型的数据,并把处理完成的条目返回给条目处理管道。条目处理管道会紧接着把该条目传递给下一个条目处理器,直至给定的条目处理器列表中的每个条目处理器都处理过该条目为止。
4) 调度器
调度器在启动时仅接受首次请求,并且不会产生任何输出。调度器的主要职责是调度各个处理模块的运行。其中包括维护各个处理模块的实例、在不同的处理模块实例之间传递数据(包括请求、响应和条目),以及监控所有这些被调度者的状态,等等。有了调度器的维护,各个处理模块得以保持其职责的简洁和专一。由于调度器是网络爬虫框架中最重要的一个模块,所以还需要再编写出一些工具来支撑起它的功能。
在弄清楚网络爬虫框架中各个模块的职责之后,你知道它是以调度器为核心的。此外,为了并发执行的需要,除调度器之外的其他模块都可以是多实例的,它们由调度器持有、维护和调用。反过来讲,这些处理模块的实例会从调度器那里接受输入,并在进行相应的处理后将输出返回给调度器。
最后,与另外两个处理模块相比,条目处理管道是比较特殊的。顾名思义,它是以流式处理为基础的,其设计灵感来自于我之前讲过的 Linux 系统中的管道。
我们可以不断地向该管道发送条目,而该管道则会让其中的若干个条目处理器依次处理每一个条目。我们可以很轻易地使用一些同步方法来保证条目处理管道的并发安全性,因此即使调度器只持有该管道的一个实例,也不会有任何问题。
下图展示了调度器与各个处理模块之间的关系,图中加入了一个新的元素——工具箱,之前所说的用于支撑调度器功能的那些工具就是工具箱的一部分。顾名思义,工具箱不是一个完整的模块,而是一些工具的集合,这些工具是调度器与所有处理模块之间的桥梁。
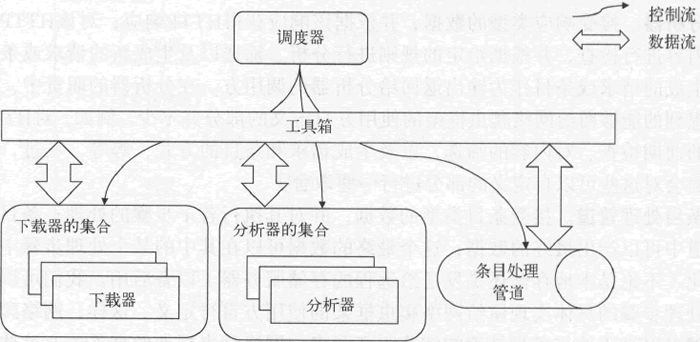
图:调度器与各处理模块的关系
至此,大家对网络爬虫框架的设计有了一个宏观上的认识。不过,我还未提及在这个总体设计之下包含的大量设计技巧和决策。这些技巧和决策不但与一些通用的程序设计原则有关,还涉及很多依赖于 Go语言的编程风格和方式方法。
这也从侧面说明,由于几乎所有语言都有着非常鲜明的特点和比较擅长的领域,所以在设计一个需要由特定语言实现的软件或程序时,多多少少会考虑到这门语言自身的特性。也就是说,软件设计不是与具体的语言毫不相关的。反过来讲,总会有一门或几门语言非常适合实现某一类软件或程序。
理论要掌握,实操不能落!以上关于《Go语言网络爬虫概述》的详细介绍,大家都掌握了吧!如果想要继续提升自己的能力,那么就来关注golang学习网公众号吧!
声明:本文转载于:云海天教程 如有侵犯,请联系study_golang@163.com删除
相关阅读
更多>
-
440 收藏
-
149 收藏
-
296 收藏
-
140 收藏
-
154 收藏
最新阅读
更多>
-
399 收藏
-
386 收藏
-
234 收藏
-
476 收藏
-
176 收藏
-
194 收藏
-
471 收藏
-
392 收藏
-
418 收藏
-
Golang · Go教程 | 1星期前 | goroutine · Context · 超时控制 · Go教程 · 后端开发 · Go Goroutine context 超时控制 WithTimeout Done QueryContext166 收藏
-
Golang · Go教程 | 2星期前 | WaitGroup · channel · 并发编程 · 优雅关闭 · Go教程 · WaitGroup Channel关闭 Go channel 并发收尾 done信号165 收藏
-
332 收藏
课程推荐
更多>
-

- 前端进阶之JavaScript设计模式
- 设计模式是开发人员在软件开发过程中面临一般问题时的解决方案,代表了最佳的实践。本课程的主打内容包括JS常见设计模式以及具体应用场景,打造一站式知识长龙服务,适合有JS基础的同学学习。
- 立即学习 543次学习
-

- GO语言核心编程课程
- 本课程采用真实案例,全面具体可落地,从理论到实践,一步一步将GO核心编程技术、编程思想、底层实现融会贯通,使学习者贴近时代脉搏,做IT互联网时代的弄潮儿。
- 立即学习 516次学习
-

- 简单聊聊mysql8与网络通信
- 如有问题加微信:Le-studyg;在课程中,我们将首先介绍MySQL8的新特性,包括性能优化、安全增强、新数据类型等,帮助学生快速熟悉MySQL8的最新功能。接着,我们将深入解析MySQL的网络通信机制,包括协议、连接管理、数据传输等,让
- 立即学习 500次学习
-

- JavaScript正则表达式基础与实战
- 在任何一门编程语言中,正则表达式,都是一项重要的知识,它提供了高效的字符串匹配与捕获机制,可以极大的简化程序设计。
- 立即学习 487次学习
-

- 从零制作响应式网站—Grid布局
- 本系列教程将展示从零制作一个假想的网络科技公司官网,分为导航,轮播,关于我们,成功案例,服务流程,团队介绍,数据部分,公司动态,底部信息等内容区块。网站整体采用CSSGrid布局,支持响应式,有流畅过渡和展现动画。
- 立即学习 485次学习
评论列表
-

- 洁净的灯泡
- 这篇技术贴真是及时雨啊,细节满满,受益颇多,已收藏,关注博主了!希望博主能多写Golang相关的文章。
- 2023-02-17 09:32:18
-
- 危机的猫咪
- 赞 ??,一直没懂这个问题,但其实工作中常常有遇到...不过今天到这,帮助很大,总算是懂了,感谢师傅分享博文!
- 2023-01-11 15:04:24
-
- 难过的牛排
- 细节满满,码住,感谢大佬的这篇文章,我会继续支持!
- 2023-01-06 12:15:23
-
- 寂寞的外套
- 这篇博文真及时,好细啊,很有用,已加入收藏夹了,关注up主了!希望up主能多写Golang相关的文章。
- 2023-01-04 11:54:29
-
- 潇洒的铅笔
- 这篇文章太及时了,细节满满,很好,已收藏,关注up主了!希望up主能多写Golang相关的文章。
- 2023-01-01 09:58:06