MySQL性能之count*count1count列对比示例
来源:脚本之家
时间:2022-12-30 12:25:29 151浏览 收藏
在数据库实战开发的过程中,我们经常会遇到一些这样那样的问题,然后要卡好半天,等问题解决了才发现原来一些细节知识点还是没有掌握好。今天golang学习网就整理分享《MySQL性能之count*count1count列对比示例》,聊聊MySQLcount、性能对比,希望可以帮助到正在努力赚钱的你。
正文
最近的工作中,我听到组内两名研发同学在交流数据统计性能的时候,聊到了以下内容:
数据统计你怎么能用 count(*) 统计数据呢,count(*) 太慢了,要是把数据库搞垮了那不就完了么,赶紧改用 count(1),这样比较快......
有点儿好奇,难道 count(1) 的性能真的就比 count(*) 要好吗?
印象中网上有很多的文章都有过类似问题的讨论,那 MySQL 统计数据总数 count(*) 、count(1)和count(列名) 哪个性能更优呢?今天我们就来聊一聊这个问题。
count() 性能与啥相关?
在讨论问题之前,我们需要先搞明白一件事:MySQL 中 count() 的性能到底与什么相关呢?
一件东西,我们知道如何取,必定需要提前知道如何存放才行,那我们可以初步判定,count() 性能应该与存储引擎相关!
我们都知道,MySQL 常见的存储引擎有两种:MyISAM 和 InnoDB。
在这两种存储引擎下,MySQL 对于使用 count() 返回结果的流程是不一样的:
- **MyISAM引擎:**每张表的总行数是存储在磁盘上,所以当执行 count() 时,是直接从磁盘拿到这个值返回,能够快速返回。
但要是在后面加了where查询条件时,统计总数也没有像想象中那么快了。
- **InnoDB 引擎:**执行 count(),需要将数据一行一行地读,再统计总数。
看到这里,可能你会有这样的疑问:
Q:为什么 InnoDB 引擎不像 MyISAM 引擎一样,把表总记录存储起来呢?
这个问题非常好,在回答这个问题之前,我们先来了解一下 MVCC 是个什么东东。
MVCC 简介
所谓MVCC,全称:Multi-Version Concurrency Control,即多版本并发控制。
MVCC 是一种并发控制的方法,一般在数据库管理系统中,实现对数据库的并发访问,在编程语言中实现事务内存。
MVCC 在 MySQL InnoDB 中的实现主要是为了提高数据库并发性能,用更好的方式去处理读-写冲突,做到即使有读写冲突时,也能做到不加锁,非阻塞并发读。
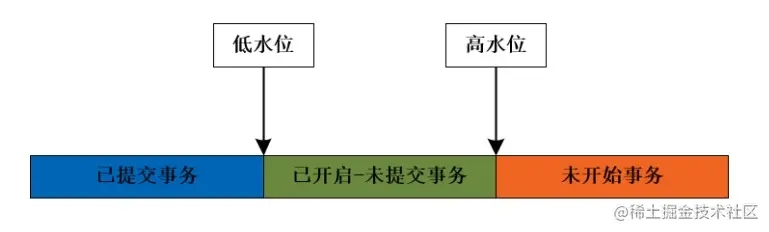
就是因为要实现多版本并发控制,所以才导致 InnoDB 引擎不能直接存储表总记录数。因为每个事务获取到的一致性视图都是不一样的,所以返回的数据总记录也是不一致的。
到这里,相信你已经知道 InnoDB 引擎为什么不像 MyISAM 引擎一样把表总记录存储起来了,简单理解原因就是:InnoDB 支持事务,MyISAM 不支持事务。
MySQL 对 count() 的优化
我们知道了count() 性能与存储引擎相关,那 MySQL 在执行 count() 操作的时候有没有对其性能做些优化呢?
答案是肯定有的!
InnoDB 是索引组织表,主键索引树的叶子节点是数据,而普通索引树的叶子节点是主键值。因此,普通索引树比主键索引树小很多。对于count(*)这样的操作,遍历哪个索引树得到的结果逻辑上都是一样的。因此,MySQL优化器会找到最小的那棵树来遍历。
如果你使用过 show table status 命令的话,就会发现这个命令的输出结果里面也有一个 rows 值用于显示这个表当前有多少行。
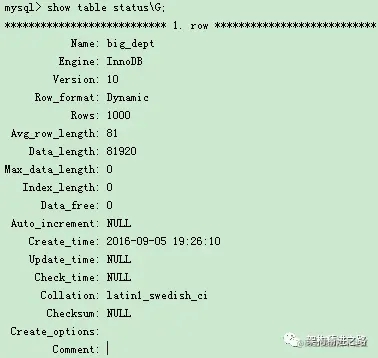
相信有人肯定会问,是不是这个 rows 值就能代替 count() 了吗?
其实不能,rows 这个是从从采样估算得来的,因此它也是不是准确。
官方文档说是在40%到50%,所以此行数 rows 是不能直接使用的,如下所示:

查询性能 PK 大起底
基于 MySQL 的 Innodb 存储引擎,统计表的总记录数下面这几种做法,到底哪种效率最高?
count(主键id)
InnoDB引擎会遍历整张表,把每一行的 id 值都取出来,返回给 server 层。server 层拿到 id 后,判断是不可能为空的,就按行累加。
count(1)
会统计表中的所有的记录数,包含字段为 null 的记录。
同样遍历整张表,但不取值,server 层对返回的每一行,放一个数字1进去,判断是不可能为空的,按行累加。
count(字段)
分为两种情况,字段定义为 not null 和 null:
1)为 not null 时:逐行从记录里面读出这个字段,判断不为 null,累加;
2)为 null 时:执行时,判断到有可能是 null,还要把值取出来再判断一下,不是 null 才累加。
count(*)
需要注意的是,并不是带了 * 就把所有值取出来,而是 MySQL 做了专门的优化,count(*) 肯定不是null,按行累加。
count(1) 和 count(*) 对比
当表的数据量大些时,对表作分析之后,使用 count(1)还要比使用 count(*)用时多了!
从执行计划来看, count(1) 和 count(*)的效果是一样的。但是在表做过分析之后, count(1) 会比 count(*)的用时少些(1w以内数据量),不过差不了多少。
如果 count(1)是聚索引,那肯定是 count(1)快,但是差的很小。因为 count(*)自动会优化指定到那一个字段,所以没必要去 count(1),用 count(*) sql会帮你完成优化的,因此:count(1) 和 count(*)基本没有差别!
总结
基于 MySQL 的 InnoDB 存储引擎,统计表的总记录数按照效率排序:
count(字段)
效率最高是 count(*),并不是count(1),所以建议尽量使用 count(*)。
执行效果上:
count(*)包括了所有的列,相当于行数,在统计结果的时候,不会忽略列值为null
count(1)包括了忽略所有列,用1代表代码行,在统计结果的时候,不会忽略列值为null
count(列名)只包括列名那一列,在统计结果的时候,会忽略列值为空(这里的空不是只空字符串或者0,而是表示null 的计数,即某个字段值为null 时,不统计。
执行效率上:
- 列名为主键,
count(列名)会比count(1)快 - 列名不为主键,
count(1)会比count(列名)快 - 如果表多个列并且没有主键,则
count(1)的执行效率优于count(*) - 如果有主键,则
select count(主键)的执行效率是最优的 - 如果表只有一个字段,则
select count(*)最优。
希望今天的讲解对大家有所帮助,谢谢!
更多关于MySQL count性能对比的资料请关注golang学习网!
本篇关于《MySQL性能之count*count1count列对比示例》的介绍就到此结束啦,但是学无止境,想要了解学习更多关于数据库的相关知识,请关注golang学习网公众号!
-
368 收藏
-
303 收藏
-
421 收藏
-
269 收藏
-
419 收藏
-

- 前端进阶之JavaScript设计模式
- 设计模式是开发人员在软件开发过程中面临一般问题时的解决方案,代表了最佳的实践。本课程的主打内容包括JS常见设计模式以及具体应用场景,打造一站式知识长龙服务,适合有JS基础的同学学习。
- 立即学习 543次学习
-

- GO语言核心编程课程
- 本课程采用真实案例,全面具体可落地,从理论到实践,一步一步将GO核心编程技术、编程思想、底层实现融会贯通,使学习者贴近时代脉搏,做IT互联网时代的弄潮儿。
- 立即学习 516次学习
-

- 简单聊聊mysql8与网络通信
- 如有问题加微信:Le-studyg;在课程中,我们将首先介绍MySQL8的新特性,包括性能优化、安全增强、新数据类型等,帮助学生快速熟悉MySQL8的最新功能。接着,我们将深入解析MySQL的网络通信机制,包括协议、连接管理、数据传输等,让
- 立即学习 500次学习
-

- JavaScript正则表达式基础与实战
- 在任何一门编程语言中,正则表达式,都是一项重要的知识,它提供了高效的字符串匹配与捕获机制,可以极大的简化程序设计。
- 立即学习 487次学习
-

- 从零制作响应式网站—Grid布局
- 本系列教程将展示从零制作一个假想的网络科技公司官网,分为导航,轮播,关于我们,成功案例,服务流程,团队介绍,数据部分,公司动态,底部信息等内容区块。网站整体采用CSSGrid布局,支持响应式,有流畅过渡和展现动画。
- 立即学习 485次学习
-

- 瘦瘦的火龙果
- 这篇文章真及时,细节满满,感谢大佬分享,mark,关注up主了!希望up主能多写数据库相关的文章。
- 2023-06-02 17:56:16
-
- 重要的鲜花
- 赞 ??,一直没懂这个问题,但其实工作中常常有遇到...不过今天到这,看完之后很有帮助,总算是懂了,感谢大佬分享文章内容!
- 2023-01-12 08:43:11
-
- 优美的金鱼
- 这篇文章出现的刚刚好,好细啊,受益颇多,码住,关注老哥了!希望老哥能多写数据库相关的文章。
- 2023-01-10 10:47:14