MySQL一次性创建表格存储过程实战
来源:脚本之家
时间:2022-12-31 11:34:23 240浏览 收藏
本篇文章向大家介绍《MySQL一次性创建表格存储过程实战》,主要包括存储、表格、MySQL创建、过程,具有一定的参考价值,需要的朋友可以参考一下。
一、创建表格
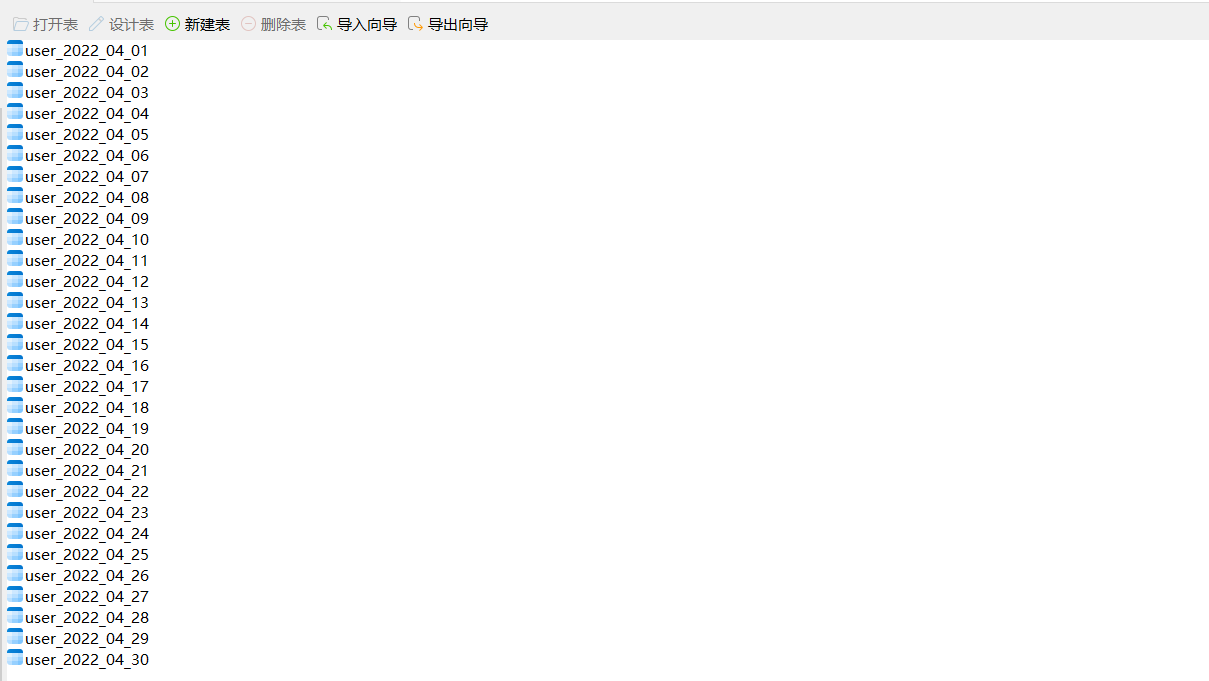
创建下个月的每天对应的表user_2022_01_01、...
需求描述:
我们需要用某个表记录很多数据,比如记录某某用户的搜索、购买行为(注意,此处是假设用数据库保存),当每天记录较多时,如果把所有数据都记录到一张表中太庞大,需要分表,我们的要求是,每天一张表,存当天的统计数据,就要求提前生产这些表——每月月底创建下一个月每天的表!
PREPARE stmt_name FROM preparable_stmt
EXECUTE stmt_name [USING @var_name [, @var_name] ...]
{DEALLOCATE | DROP} PREPARE stmt_name
-- 知识点 时间的处理
-- EXTRACT(unit FROM date)截取时间的指定位置值
-- DATE_ADD(date,INTERVAL expr unit) 日期运算
-- LAST_DAY(date) 获取日期的最后一天
-- YEAR(date) 返回日期中的年
-- MONTH(date) 返回日期的月
-- DAYOFMONTH(date) 返回日
思路:构建循环语句,创建单个表格比较的简单,但是对于很多种表格,而且是下个月的表格,对于表命名有一定的要求,所以就需要用到我们之前的日期函数,和字符串函数的一些知识。
-- 思路:循环构建表名 user_2021_11_01 到 user_2020_11_30;并执行create语句。 use mysql7_procedure; drop procedure if exists proc22_demo; delimiter $$ create procedure proc22_demo() begin declare next_year int; declare next_month int; declare next_month_day int; declare next_month_str char(2); declare next_month_day_str char(2); -- 处理每天的表名 declare table_name_str char(10); declare t_index int default 1; -- declare create_table_sql varchar(200);
首先利用declare 定义需要的一些变量,next_year(下一年),next_month(下一个月),next_month_day(天数),这里为什么要这样去定义,特别是年,月,不应该是提前知道的吗?答案是有时候比如是12月呢,那么下一个月的年份就不一样了,所以需要利用日期函数的一些运算去解决这些问题。
-- 获取下个月的年份 set next_year = year(date_add(now(),INTERVAL 1 month)); -- 获取下个月是几月 set next_month = month(date_add(now(),INTERVAL 1 month)); -- 下个月最后一天是几号 set next_month_day = dayofmonth(LAST_DAY(date_add(now(),INTERVAL 1 month))); if next_month上面都是对表的名字的一些字段和别名进行获取和拼接
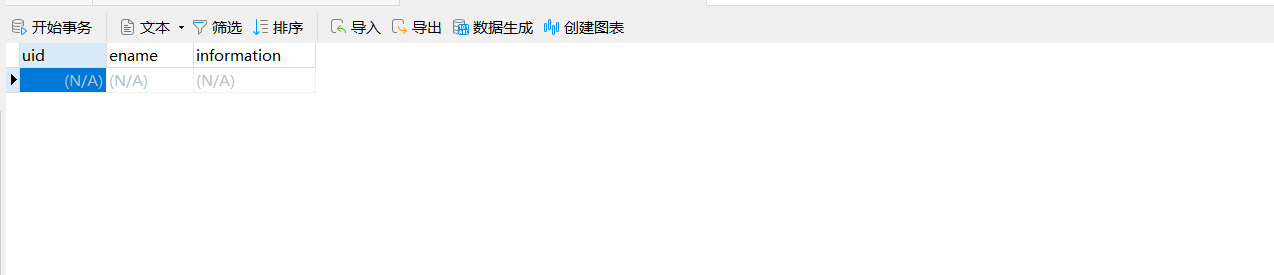
set table_name_str = concat(next_year,'_',next_month_str,'_',next_month_day_str); -- 拼接create sql语句 set @create_table_sql = concat( 'create table user_', table_name_str, '(`uid` INT ,`ename` varchar(50) ,`information` varchar(50)) COLLATE=\'utf8_general_ci\' ENGINE=InnoDB'); -- FROM后面不能使用局部变量! prepare create_table_stmt FROM @create_table_sql; execute create_table_stmt; DEALLOCATE prepare create_table_stmt; set t_index = t_index + 1; end while; end $$ delimiter ; call proc22_demo();
这样就实现了效果
二、补充:MySQL的存储函数与存储过程的区别
MySQL存储函数(自定义函数),函数一般用于计算和返回一个值,可以将经常需要使用的计算或功能写成一个函数。
存储函数和存储过程一样,都是在数据库中定义一些 SQL 语句的集合。
存储函数与存储过程的区别;
- 1.存储函数有且只有一个返回值,而存储过程可以有多个返回值,也可以没有返回值。
- 2.存储函数只能有输入参数,而且不能带in, 而存储过程可以有多个in,out,inout参数。
- 3.存储过程中的语句功能更强大,存储过程可以实现很复杂的业务逻辑,而函数有很多限制,如不能在函数中使用insert,update,delete,create等语句;
- 4.存储函数只完成查询的工作,可接受输入参数并返回一个结果,也就是函数实现的功能针对性比较强。
- 5.存储过程可以调用存储函数、但函数不能调用存储过程。
- 6.存储过程一般是作为一个独立的部分来执行(call调用)。而函数可以作为查询语句的一个部分来调用.
create function func_name ([param_name type[,...]]) returns type [characteristic ...] begin routine_body end;
参数说明:
- (1)func_name :存储函数的名称。
- (2)param_name type:可选项,指定存储函数的参数。type参数用于指定存储函数的参数类型,该类型可以是MySQL数据库中所有支持的类型。
- (3)RETURNS type:指定返回值的类型。
- (4)characteristic:可选项,指定存储函数的特性。
- (5)routine_body:SQL代码内容。
create database mydb9_function; -- 导入测试数据 use mydb9_function; set global log_bin_trust_function_creators=TRUE; -- 信任子程序的创建者 -- 创建存储函数-没有输输入参数 drop function if exists myfunc1_emp; delimiter $$ create function myfunc1_emp() returns int begin declare cnt int default 0; select count(*) into cnt from emp; return cnt; end $$ delimiter ; -- 调用存储函数 select myfunc1_emp();
create database mydb9_function; -- 导入测试数据 use mydb9_function; set global log_bin_trust_function_creators=TRUE; -- 信任子程序的创建者 -- 创建存储函数-没有输输入参数 drop function if exists myfunc1_emp; delimiter $$ create function myfunc1_emp() returns int begin declare cnt int default 0; select count(*) into cnt from emp; return cnt; end $$ delimiter ; -- 调用存储函数 select myfunc1_emp();
今天带大家了解了存储、表格、MySQL创建、过程的相关知识,希望对你有所帮助;关于数据库的技术知识我们会一点点深入介绍,欢迎大家关注golang学习网公众号,一起学习编程~
-
279 收藏
-
189 收藏
-
344 收藏
-
228 收藏
-
327 收藏
-
数据库 · MySQL | 12小时前 | MySQL · JSON · 索引 · 数据库 · 查询优化 · 生成列 · json_extract 索引优化 列表筛选 生成列 MySQL JSON JSON索引351 收藏
-
数据库 · MySQL | 1天前 | MySQL · 认证 · MySQL 8.4 · 数据库升级 · caching_sha2_password mysql_native_password 账号认证 MySQL 8.4 升级迁移236 收藏
-
471 收藏
-
数据库 · MySQL | 3天前 | MySQL · 数据库 · SQL · ON DUPLICATE KEY UPDATE · VALUES · 行别名 · MySQL VALUES() 弃用 ON DUPLICATE KEY UPDATE MySQL 行别名 INSERT AS new MySQL upsert INSERT SELECT117 收藏
-
数据库 · MySQL | 4天前 | MySQL · 索引 · limit · explain · sql优化 · ORDER BY · mysql order by explain limit 复合索引 filesort279 收藏
-
数据库 · MySQL | 5天前 | 并发 · MySQL · InnoDB · update · 库存扣减 · innodb MySQL 库存扣减 条件 UPDATE 防超卖 affected rows470 收藏
-
421 收藏
-
189 收藏
-
412 收藏
-
378 收藏
-
334 收藏
-
259 收藏
-

- 前端进阶之JavaScript设计模式
- 设计模式是开发人员在软件开发过程中面临一般问题时的解决方案,代表了最佳的实践。本课程的主打内容包括JS常见设计模式以及具体应用场景,打造一站式知识长龙服务,适合有JS基础的同学学习。
- 立即学习 543次学习
-

- GO语言核心编程课程
- 本课程采用真实案例,全面具体可落地,从理论到实践,一步一步将GO核心编程技术、编程思想、底层实现融会贯通,使学习者贴近时代脉搏,做IT互联网时代的弄潮儿。
- 立即学习 516次学习
-

- 简单聊聊mysql8与网络通信
- 如有问题加微信:Le-studyg;在课程中,我们将首先介绍MySQL8的新特性,包括性能优化、安全增强、新数据类型等,帮助学生快速熟悉MySQL8的最新功能。接着,我们将深入解析MySQL的网络通信机制,包括协议、连接管理、数据传输等,让
- 立即学习 500次学习
-

- JavaScript正则表达式基础与实战
- 在任何一门编程语言中,正则表达式,都是一项重要的知识,它提供了高效的字符串匹配与捕获机制,可以极大的简化程序设计。
- 立即学习 487次学习
-

- 从零制作响应式网站—Grid布局
- 本系列教程将展示从零制作一个假想的网络科技公司官网,分为导航,轮播,关于我们,成功案例,服务流程,团队介绍,数据部分,公司动态,底部信息等内容区块。网站整体采用CSSGrid布局,支持响应式,有流畅过渡和展现动画。
- 立即学习 485次学习