MySQL通过showstatus查看、explain分析优化数据库性能
来源:脚本之家
时间:2022-12-29 14:29:48 218浏览 收藏
亲爱的编程学习爱好者,如果你点开了这篇文章,说明你对《MySQL通过showstatus查看、explain分析优化数据库性能》很感兴趣。本篇文章就来给大家详细解析一下,主要介绍一下数据库、优化、explain、MySQLshow、status,希望所有认真读完的童鞋们,都有实质性的提高。
1.概述
在应用系统开发过程中,由于初期数据量小,开发人员写SQL语句时更重视功能上的实现,但是当应用系统正式上线后,随着生产数据量的急剧增长,很多SQL语句开始逐渐显露出性能问题,对生产环境的影响也越来越大,此时这些有问题的SQL语句就成为整个系统性能的瓶颈,因此我们必须要对它们进行优化,该章节将详细介绍在MySQL中优化SQL语句的方法。
2.通过show status命令了解各种SQL的执行频率
MySQL客户端连接成功后,通过show [session|global]status命令可以提供服务器状态信息,也可以在操作系统上使用mysqladmin extended-status命令获得这些消息。show [session|global] status可以根据需要加上参数“session”或者“global”来显示session级(当前连接)的统计结果和global级(自数据库上次启动至今)的统计结果。如果不写,默认使用参数是“session”。
下面的命令显示了当前session中所有统计参数的值:
-- 查看会话所有统计的值 SHOW STATUS LIKE 'Com_%'; Or SHOW SESSION STATUS LIKE 'Com_%';
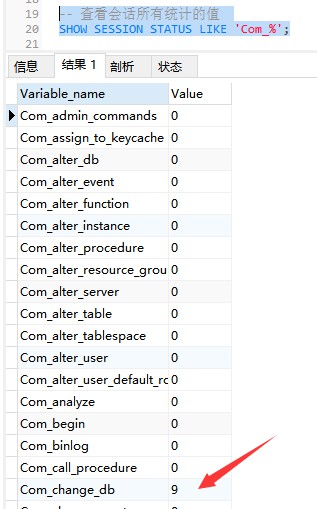
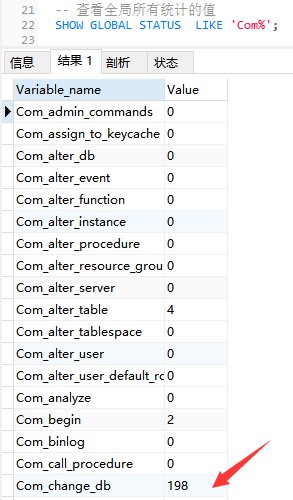
下面的命令显示了当前global中所有统计参数的值:
-- 查看全局所有统计的值
SHOW GLOBAL STATUS LIKE 'Com_%';
Com_xxx表示每个xxx语句执行的次数,我们通常比较关心的是以下几个统计参数:
- Com_select:执行SELECT操作的次数,一次查询只累加1。
- Com_insert:执行INSERT操作的次数,对于批量插入的INSERT操作,只累加一次。
- Com_update:执行UPDATE操作的次数。
- Com_delete:执行DELETE操作的次数。
上面这些参数对于所有存储引擎的表操作都会进行累计。下面这几个参数只是针对InnoDB存储引擎的,累加的算法也略有不同。
- Innodb_rows_read:SELECT查询返回的行数。
- Innodb_rows_inserted:执行INSERT操作插入的行数。
- Innodb_rows_updated:执行UPDATE操作更新的行数。
- Innodb_rows_deleted:执行DELETE操作删除的行数。
通过以上几个参数,可以很容易地了解当前数据库的应用系统是以插入更新为主还是以查询操作为主,以及各种类型的SQL大致的执行比例是多少。对于更新操作的计数,是对执行次数的计数,不论提交还是回滚都会进行累加。
对于事务型的应用,通过Com_commit和Com_rollback可以了解事务提交和回滚的情况,对于回滚操作非常频繁的数据库,可能意味着应用编写存在问题。此外,以下几个参数便于用户了解数据库的基本情况。
- Connections:试图连接MySQL服务器的次数。
- Uptime:服务器工作时间。
- Slow_queries:慢查询的次数。
3.定位执行效率较低的SQL语句
可以通过以下两种方式定位执行效率较低的SQL语句。
- 通过慢查询日志定位那些执行效率较低的SQL语句,用--log-slow-queries[=file_name]选项启动时,mysqld写一个包含所有执行时间超过long_query_time秒的SQL语句的日志文件。
- 慢查询日志在查询结束以后才纪录,所以在应用系统反映执行效率出现问题的时候查询慢查询日志并不能定位问题,可以使用show processlist命令查看当前MySQL在进行的线程,包括线程的状态、是否锁表等,可以实时地查看SQL的执行情况,同时对一些锁表操作进行优化。
4.通过EXPLAIN分析低效SQL的执行计划
通过定位执行效率较低的SQL语句后,可以通过EXPLAIN或者DESC命令获取MySQL如何执行SELECT语句的信息,包括在SELECT语句执行过程中表如何连接和连接的顺序,比如想统计所有库存阶梯数量,需要关联goods_stock表和goods_stock_price表,并且对goods_stock_price.Qty字段做求和(sum)操作,相应 SQL 的执行计划如下:
EXPLAIN SELECT SUM(sp.Qty) FROM goods_stock AS s LEFT JOIN goods_stock_price AS sp ON s.ID=sp.GoodsStockID;

如上图所示每个列的简单解释如下:
- select_type:表示 SELECT 的类型,常见的取值有:
- SIMPLE(简单表,即不使用表连接 或者子查询)。
- PRIMARY(主查询,即外层的查询)、UNION(UNION 中的第二个或 者后面的查询语句)、◎SUBQUERY(子查询中的第一个SELECT)等。
- table:输出结果集的表。
- type:表示表的连接类型,性能由好到差的连接类型为:
- system(表中仅有一行,即常量表)。
- const(单表中最多有一个匹配行,例如primary key或者unique index)。
- eq_ref(对于前面的每一行,在此表中只查询一条记录,简单来说,就是多表连接中使用primary key或者unique index)。
- ref(与eq_ref类似,区别在于不是使用primary key或者unique index,而是使用普通的索引)。
- ref_or_null(与ref类似,区别在于条件中包含对NULL的查询)。
- index_merge(索引合并优化)。
- unique_subquery(in的后面是一个查询主键字段的子查询)。
- index_subquery(与unique_subquery类似,区别在于in的后面是查询非唯一索引字段的子查询)。
- range(单表中的范围查询)。
- index(对于前面的每一行,都通过查询索引来得到数据)。
- all(对于前面的每一行,都通过全表扫描来得到数据)。
- possible_keys:表示查询时,可能使用的索引。
- key:表示实际使用的索引。
- key_len:索引字段的长度。
- rows:扫描行的数量。
- filtered:返回结果的行占需要读到的行(rows列的值)的百分比。
- Extra:执行情况的说明和描述。
- Using index(此值表示mysql将使用覆盖索引,以避免访问表)。
- Using where(mysql 将在存储引擎检索行后再进行过滤,许多where条件里涉及索引中的列,当(并且如果)它读取索引时,就能被存储引擎检验,因此不是所有带where子句的查询都会显示“Using where”。有时“Using where”的出现就是一个暗示:查询可受益于不同的索引)。
- Using temporary(mysql 对查询结果排序时会使用临时表)。
- Using filesort(mysql会对结果使用一个外部索引排序,而不是按索引次序从表里读取行。mysql有两种文件排序算法,这两种排序方式都可以在内存或者磁盘上完成,explain不会告诉你mysql将使用哪一种文件排序,也不会告诉你排序会在内存里还是磁盘上完成)。
- Range checked for each record(index map: N) (没有好用的索引,新的索引将在联接的每一行上重新估算,N是显示在possible_keys列中索引的位图,并且是冗余的)。
5.确定问题并采取相应的优化措施
经过以上定位步骤,我们基本就可以分析到问题出现的原因。此时我们可以根据情况采取相应的改进措施,进行优化提高语句执行效率。
在上面的例子中,已经可以确认是goods_stock是走主键索引的,但是对goods_stock_price子表的进行了全表扫描导致效率的不理想,那么应该对goods_stock_price表的GoodsStockID字段创建索引,具体命令如下:
-- 创建索引 CREATE INDEX idx_stock_price_1 ON goods_stock_price (GoodsStockID); -- 附加删除跟查询索引语句 ALTER TABLE goods_stock_price DROP INDEX idx_stock_price_1; SHOW INDEX FROM goods_stock_price;
创建索引后,我们再看一下这条语句的执行计划,具体如下:
EXPLAIN SELECT SUM(sp.Qty) FROM goods_stock AS s LEFT JOIN goods_stock_price AS sp ON s.ID=sp.GoodsStockID;

可以发现建立索引后对goods_stock_price子表需要扫描的行数明显减少(从 3 行减少到1行),可见索引的使用可以大大提高数据库的访问速度,尤其在表很庞大的时候这种优势更为明显。
理论要掌握,实操不能落!以上关于《MySQL通过showstatus查看、explain分析优化数据库性能》的详细介绍,大家都掌握了吧!如果想要继续提升自己的能力,那么就来关注golang学习网公众号吧!
-
374 收藏
-
398 收藏
-
214 收藏
-
483 收藏
-
268 收藏
-

- 前端进阶之JavaScript设计模式
- 设计模式是开发人员在软件开发过程中面临一般问题时的解决方案,代表了最佳的实践。本课程的主打内容包括JS常见设计模式以及具体应用场景,打造一站式知识长龙服务,适合有JS基础的同学学习。
- 立即学习 543次学习
-

- GO语言核心编程课程
- 本课程采用真实案例,全面具体可落地,从理论到实践,一步一步将GO核心编程技术、编程思想、底层实现融会贯通,使学习者贴近时代脉搏,做IT互联网时代的弄潮儿。
- 立即学习 516次学习
-

- 简单聊聊mysql8与网络通信
- 如有问题加微信:Le-studyg;在课程中,我们将首先介绍MySQL8的新特性,包括性能优化、安全增强、新数据类型等,帮助学生快速熟悉MySQL8的最新功能。接着,我们将深入解析MySQL的网络通信机制,包括协议、连接管理、数据传输等,让
- 立即学习 500次学习
-

- JavaScript正则表达式基础与实战
- 在任何一门编程语言中,正则表达式,都是一项重要的知识,它提供了高效的字符串匹配与捕获机制,可以极大的简化程序设计。
- 立即学习 487次学习
-

- 从零制作响应式网站—Grid布局
- 本系列教程将展示从零制作一个假想的网络科技公司官网,分为导航,轮播,关于我们,成功案例,服务流程,团队介绍,数据部分,公司动态,底部信息等内容区块。网站整体采用CSSGrid布局,支持响应式,有流畅过渡和展现动画。
- 立即学习 485次学习
-

- 现实的睫毛膏
- 受益颇多,一直没懂这个问题,但其实工作中常常有遇到...不过今天到这,看完之后很有帮助,总算是懂了,感谢作者大大分享博文!
- 2023-05-12 06:54:58
-
- 激情的项链
- 这篇博文太及时了,太细致了,感谢大佬分享,已收藏,关注楼主了!希望楼主能多写数据库相关的文章。
- 2023-05-01 11:05:14
-
- 柔弱的凉面
- 太细致了,mark,感谢作者的这篇技术文章,我会继续支持!
- 2023-02-19 21:01:53
-
- 顺利的板凳
- 这篇文章内容真是及时雨啊,很详细,受益颇多,码住,关注作者大大了!希望作者大大能多写数据库相关的文章。
- 2023-02-10 12:24:16
-
- 精明的狗
- 这篇文章出现的刚刚好,好细啊,太给力了,已收藏,关注老哥了!希望老哥能多写数据库相关的文章。
- 2023-01-06 14:58:06
-
- 开放的宝马
- 赞 ??,一直没懂这个问题,但其实工作中常常有遇到...不过今天到这,帮助很大,总算是懂了,感谢楼主分享技术贴!
- 2023-01-01 23:46:55
-
- 殷勤的羊
- 这篇技术贴太及时了,作者大大加油!
- 2022-12-31 00:12:49
-
- 要减肥的金鱼
- 这篇博文出现的刚刚好,很详细,真优秀,已收藏,关注作者大大了!希望作者大大能多写数据库相关的文章。
- 2022-12-30 05:30:55