MySQL百万级数据大分页查询优化的实现
来源:脚本之家
时间:2022-12-28 19:48:26 350浏览 收藏
在数据库实战开发的过程中,我们经常会遇到一些这样那样的问题,然后要卡好半天,等问题解决了才发现原来一些细节知识点还是没有掌握好。今天golang学习网就整理分享《MySQL百万级数据大分页查询优化的实现》,聊聊优化、MySQL分页查询,希望可以帮助到正在努力赚钱的你。
前言:在数据库开发过程中我们经常会使用分页,核心技术是使用用limit start, count分页语句进行数据的读取。
一、MySQL分页起点越大查询速度越慢
直接用limit start, count分页语句,表示从第start条记录开始选择count条记录 :
select * from product limit start, count
当起始页较小时,查询没有性能问题,我们分别看下从10, 1000, 10000, 100000开始分页的执行时间(每页取20条)。
select * from product limit 10, 20 0.002秒 select * from product limit 1000, 20 0.011秒 select * from product limit 10000, 20 0.027秒 select * from product limit 100000, 20 0.057秒
我们已经看出随着起始记录的增加,时间也随着增大, 这说明分页语句limit跟起始页码是有很大关系的,那么我们把起始记录改为100w看下:
select * from product limit 1000000, 20 0.682秒
我们惊讶的发现MySQL在数据量大的情况下分页起点越大查询速度越慢,300万条起的查询速度已经需要1.368秒钟。这是为什么呢?因为limit 3000000,10的语法实际上是mysql扫描到前3000020条数据,之后丢弃前面的3000000行,这个步骤其实是浪费掉的。
select * from product limit 3000000, 20 1.368秒
从中我们也能总结出两件事情:
- limit语句的查询时间与起始记录的位置成正比
- mysql的limit语句是很方便,但是对记录很多的表并不适合直接使用。
二、 limit大分页问题的性能优化方法
(1)利用表的覆盖索引来加速分页查询
MySQL的查询完全命中索引的时候,称为覆盖索引,是非常快的。因为查询只需要在索引上进行查找,之后可以直接返回,而不用再回表拿数据。在我们的例子中,我们知道id字段是主键,自然就包含了默认的主键索引。现在让我们看看利用覆盖索引的查询效果如何。
select id from product limit 1000000, 20 0.2秒
那么如果我们也要查询所有列,如何优化?
优化的关键是要做到让MySQL每次只扫描20条记录,我们可以使用limit n,这样性能就没有问题,因为MySQL只扫描n行。我们可以先通过子查询先获取起始记录的id,然后根据Id拿数据:
select * from vote_record where id>=(select id from vote_record limit 1000000,1) limit 20;
(2)用上次分页的最大id优化
先找到上次分页的最大ID,然后利用id上的索引来查询,类似于:
select * from user where id>1000000 limit 100
三、MySQL百万数据快速生成
利用mysql内存表插入速度快的特点,先利用函数和存储过程在内存表中生成数据,然后再从内存表插入普通表中
3.1、创建内存表及普通表
//内存表 CREATE TABLE `vote_record_memory` ( `id` INT (11) NOT NULL AUTO_INCREMENT, `user_id` VARCHAR (20) NOT NULL, `vote_id` INT (11) NOT NULL, `group_id` INT (11) NOT NULL, `create_time` datetime NOT NULL, PRIMARY KEY (`id`), KEY `index_id` (`user_id`) ) ENGINE = MEMORY AUTO_INCREMENT = 1 DEFAULT CHARSET = utf8 //普通表 CREATE TABLE `vote_record` ( `id` INT (11) NOT NULL AUTO_INCREMENT, `user_id` VARCHAR (20) NOT NULL, `vote_id` INT (11) NOT NULL, `group_id` INT (11) NOT NULL, `create_time` datetime NOT NULL, PRIMARY KEY (`id`), KEY `index_user_id` (`user_id`) ) ENGINE = INNODB AUTO_INCREMENT = 1 DEFAULT CHARSET = utf8
3.2、创建函数
//创建函数 CREATE FUNCTION `rand_string`(n INT) RETURNS varchar(255) CHARSET latin1 BEGIN DECLARE chars_str varchar(100) DEFAULT 'abcdefghijklmnopqrstuvwxyzABCDEFGHIJKLMNOPQRSTUVWXYZ0123456789'; DECLARE return_str varchar(255) DEFAULT '' ; DECLARE i INT DEFAULT 0; WHILE i3.3、创建插入内存表数据的存储过程
#创建插入内存表数据存储过程,入参n是多少就插入多少条数据 CREATE PROCEDURE `add_vote_memory`(IN n int) BEGIN DECLARE i INT DEFAULT 1; WHILE (i3.4、创建内存表数据插入普通表的存储过程
此处利用对内存表的循环插入和删除来实现批量生成数据,这样可以不需要更改mysql默认的max_heap_table_size值也照样可以生成百万或者千万的数据。
- max_heap_table_size默认值是16M。
- max_heap_table_size的作用是配置用户创建内存临时表的大小,配置的值越大,能存进内存表的数据就越多。
#循环从内存表获取数据插入普通表 #参数描述 n表示循环调用几次;count表示每次插入内存表和普通表的数据量 CREATE PROCEDURE `add_vote_memory_to_common`(IN n int, IN count int) BEGIN DECLARE i INT DEFAULT 1; WHILE (i3.5、运行存储过程插入数据
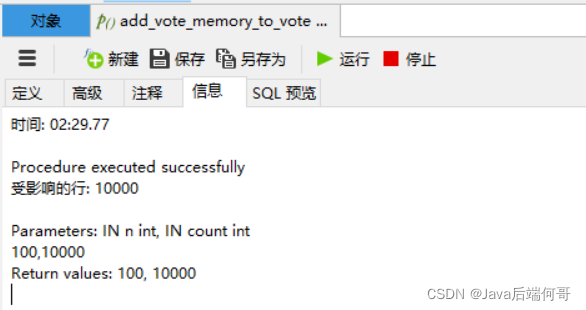
#循环调用100次,每次插入1W条数据 add_vote_memory_to_vote(100,10000);插入一百万条数据,花了2分半钟:
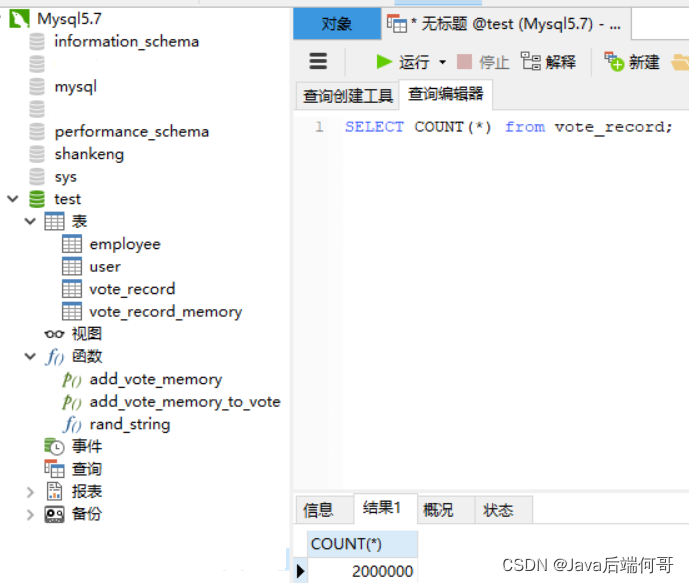
我执行了两次,查询vote_record表的行记录总数为两百万条:
参考链接:
到这里,我们也就讲完了《MySQL百万级数据大分页查询优化的实现》的内容了。个人认为,基础知识的学习和巩固,是为了更好的将其运用到项目中,欢迎关注golang学习网公众号,带你了解更多关于mysql的知识点!
-
101 收藏
-
102 收藏
-
107 收藏
-
126 收藏
-
130 收藏
-

- 前端进阶之JavaScript设计模式
- 设计模式是开发人员在软件开发过程中面临一般问题时的解决方案,代表了最佳的实践。本课程的主打内容包括JS常见设计模式以及具体应用场景,打造一站式知识长龙服务,适合有JS基础的同学学习。
- 立即学习 543次学习
-

- GO语言核心编程课程
- 本课程采用真实案例,全面具体可落地,从理论到实践,一步一步将GO核心编程技术、编程思想、底层实现融会贯通,使学习者贴近时代脉搏,做IT互联网时代的弄潮儿。
- 立即学习 516次学习
-

- 简单聊聊mysql8与网络通信
- 如有问题加微信:Le-studyg;在课程中,我们将首先介绍MySQL8的新特性,包括性能优化、安全增强、新数据类型等,帮助学生快速熟悉MySQL8的最新功能。接着,我们将深入解析MySQL的网络通信机制,包括协议、连接管理、数据传输等,让
- 立即学习 500次学习
-

- JavaScript正则表达式基础与实战
- 在任何一门编程语言中,正则表达式,都是一项重要的知识,它提供了高效的字符串匹配与捕获机制,可以极大的简化程序设计。
- 立即学习 487次学习
-

- 从零制作响应式网站—Grid布局
- 本系列教程将展示从零制作一个假想的网络科技公司官网,分为导航,轮播,关于我们,成功案例,服务流程,团队介绍,数据部分,公司动态,底部信息等内容区块。网站整体采用CSSGrid布局,支持响应式,有流畅过渡和展现动画。
- 立即学习 485次学习
-

- 生动的钢笔
- 这篇文章真及时,太全面了,真优秀,已收藏,关注作者大大了!希望作者大大能多写数据库相关的文章。
- 2023-02-11 06:42:45
-
- 专注的羊
- 太细致了,码住,感谢师傅的这篇博文,我会继续支持!
- 2023-01-12 09:33:41
-
- 舒服的小懒猪
- 这篇技术文章真及时,很详细,赞 ??,码住,关注up主了!希望up主能多写数据库相关的文章。
- 2023-01-11 13:56:40
-
- 聪明的眼睛
- 这篇文章内容太及时了,太全面了,写的不错,mark,关注楼主了!希望楼主能多写数据库相关的文章。
- 2023-01-08 18:21:51
-
- 俊逸的钢笔
- 这篇文章真是及时雨啊,up主加油!
- 2023-01-07 20:20:19
-
- 无限的咖啡豆
- 太给力了,一直没懂这个问题,但其实工作中常常有遇到...不过今天到这,看完之后很有帮助,总算是懂了,感谢作者大大分享技术文章!
- 2023-01-04 11:10:25
-
- 可靠的路人
- 受益颇多,一直没懂这个问题,但其实工作中常常有遇到...不过今天到这,帮助很大,总算是懂了,感谢作者分享文章内容!
- 2023-01-04 06:52:27