MySQL的索引系统采用B+树的原因解析
来源:脚本之家
时间:2022-12-29 11:46:38 157浏览 收藏
来到golang学习网的大家,相信都是编程学习爱好者,希望在这里学习数据库相关编程知识。下面本篇文章就来带大家聊聊《MySQL的索引系统采用B+树的原因解析》,介绍一下Mysql索引、B+树,希望对大家的知识积累有所帮助,助力实战开发!
1.什么是索引?
索引是为了加速对表中数据行的检索而创建的一种分散的存储结构。(就好像我们小时候用的字典,有了字典查到对应的字就会变快)
2.为什么需要索引?
首先我们需要了解一些概念和知识
- mysql数据存储在什么地方?----磁盘
- 查询数据比较慢的,一般情况下是卡在哪了? ----IO
- (所以我们要提高IO的效率,那么如何提高呢?---- 次数和量两个层面,例如:搬砖,搬一次和搬十次耗费的力气是不一样的,一次搬一块和一次搬十块耗费的力气(占用IO资源)也是不一样的。所以我们尽可能的在满足自身需求的前提下,减少和IO的交互)
- 去磁盘读取数据的时候,是用多少读取多少嘛? ----磁盘预读
- 磁盘预读:内存跟磁盘在发生数据交互的时候,一般情况下有一个最小的逻辑单元,称为页,datapage,页一般由操作系统决定是多大,一般是4k和8k,而我们在进行数据交互的时候,可以取页的的整数倍来进行读取,innodb存储引擎每次读取数据为16k
- 局部性原理:数据和程序都有聚集成群的倾向,同时之前被访问过的数据和可能再次被查询,涉及空间局部性、时间局部性
通过以上几个概念我们大概知道索引是用来干嘛的了----预先设计好索引系统,等我们查询数据的时候,减少和IO的交互来提高我们的查询效率。
3.如何设计索引系统?
我们还是先明白几个概念
- 索引存储在哪?---- 磁盘,查询数据的时候会优先将索引加载到内存中
- 索引在存储的时候需要什么信息?需要存什么字段值?
—— key:实际数据行中储存的值
—— 文件地址(指针、我们需要找到存储数据文件在哪就得靠文件地址)
—— offset:偏移量(如果我们要取文件中的某一条数据时,就需要用到偏移量)
- 上面说的这种格式的数据要使用什么样的数据结构来储存?
—— 上面可知我们我们的数据格式是 K-V类型的
知道K-V格式数据那我们就知道使用什么数据结构来储存了,有哈希表、树(二叉树、二分查找树、二分平衡树、红黑树、B树、B+树)
综上所述,我们可以上面的数据结构来设计我们的索引系统
4.MYSQL索引系统是什么呢?
为什么不按照上面说的格式储存呢?
众所周知,mysql的索引系统使用的是B+树,为什么是B+树呢?接下来我们逐个分析其他的存储结构为什么不行。在此之前,我们还是需要了解两个前置知识----OLAP和OLTP
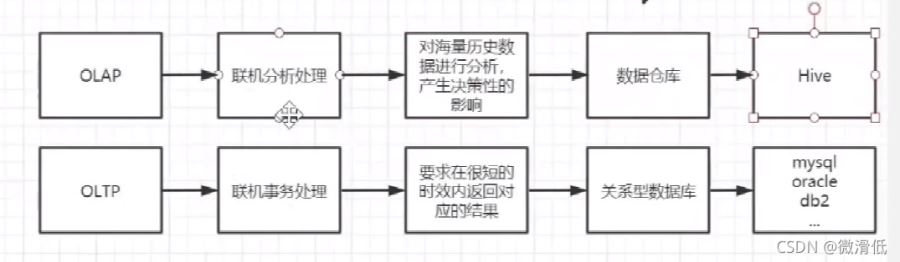
当我们存储的数据量越多时,对应建立的索引也会越大,当我们从磁盘读取到内存时就会产生IO问题,那我们又对索引建立索引嘛?不是的,所以mysql采取的B+树
5.哈希表
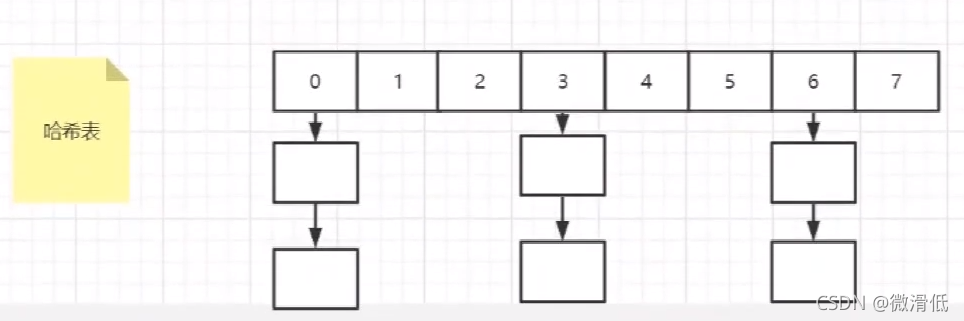
上面是哈希表的存储结构,我们来探讨这类的存储结构的优缺点
缺点:
- 哈希冲突会造成数据散列不均匀,会产生大量的线性查询,比较浪费时间
- 不支持范围查询,当进行范围查询的时候,必须要挨个遍历
- 对于内存空间的要求比较高(要把全部数据加到到内存中)
优点:
如果是等值查询,那么会非常快
那么在mysql中有没有hash索引呢?
- memory存储引擎使用的是hash索引
- innodb支持自适应hash
6.树
6.1 二叉树
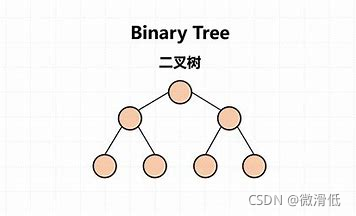
二叉树本身是无序的,当我们在进行数据查找时要挨个去跟每个节点进行数据对比,看是否符合我们的数据要求,效率低下
6.2 二分查找树(Binary Search Tree ,BST)
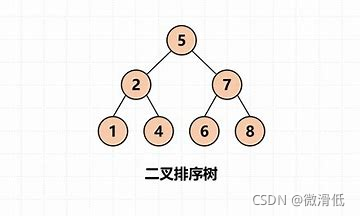
二分查找树的特点:插入数据的时候必须有序,左子树必须小于跟节点,右子树必须保证大于根节点。所以使用二分查找树对比二叉树来显然提高了查询效率。
但是如果数据插入是递增或者递减的顺序的话,二分查找树就会退化成链表,查找效率又降低了
6.3 平衡二叉树(Balanced Binary Tree, AVL树)
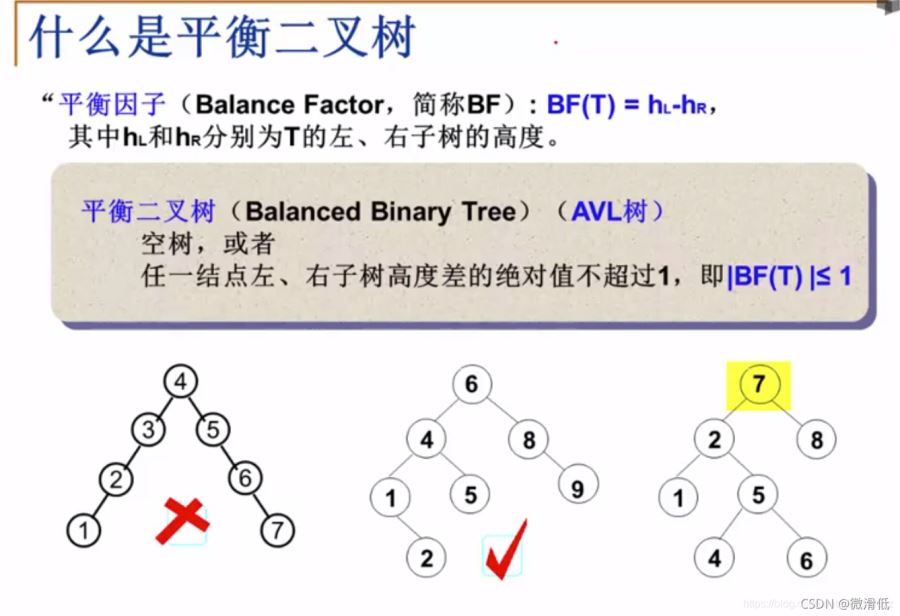
根据二叉查找树的所暴露出的问题,我们通过使用AVL树经过左旋或者右旋让树平衡。但是为了保证平衡,在插入数据的时候必须要旋转,通过插入性能的损失来弥补查询性能的提升。读多写少的情况还好,但是如果我读写请求一样多,那就不合适了。
6.4 红黑树
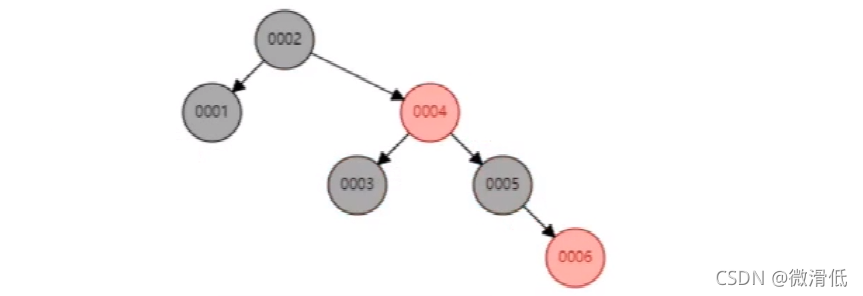
红黑树也是经过左旋和右旋让树平衡起来,还有变色的行为,最长子树只要不超过最短子树的两倍即可…所以就能让查询性能和插入性能近似取得一个平衡,但是随着数据的插入,发现树的深度会变深,深的深度越深,意味着IO次数越多,影响数据读取的效率。
6.5 B树
针对红黑树暴露的问题,那么我们应该如何提高读取的效率呢?我们能不能从有序的二叉树,变成有序的多叉树呢,这样我们就可以储存更多的数据
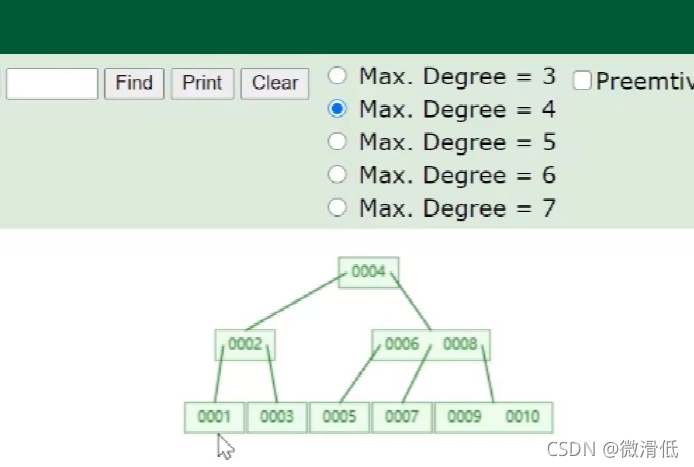
Degree为4表示的是一个节点存储三个数据值,超过就要变换。那么实际的数据是怎么存储的呢?我们需要Key和完整的数据行
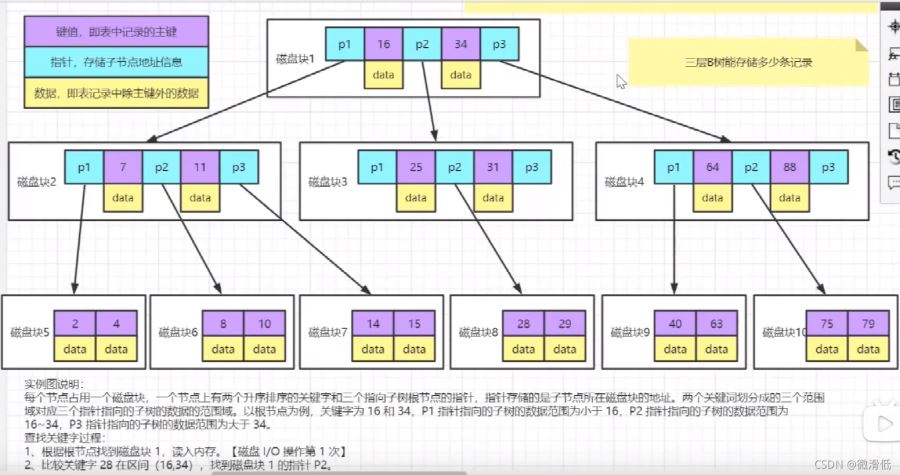
上图是B树实际存储数据的图,每个节点有三个元素key、指针、数据。
查找实例,如果我想找28这个数据,先从磁盘块1开始发现读取不到,经对比范围在p2指针指向的磁盘块3,还是没找到,再根据磁盘块3的p2指针指向磁盘块8找到28。我们来分析一下,每个磁盘块大小为16kb,我们查找了三个磁盘块只需读取48kb,那么三层B树能存储多少条记录呢?
我们理想化一下,假设key和指针不占用大小,一条数据占用1k的大小,那么磁盘1数据可以存储16条,磁盘3也是16条,磁盘8也是16条,那么我们只能存储161616=4096条记录,这明显有点少了,而且我们是理想化的,实际key和指针也是占用大小的。
于是乎我们不禁思考,为什么存储的数据量那么少?
我们发现每层存储的大小都被data给占用了,那么我们能不能只存储key跟指针呢?为此就引出了B+树
6.6 B+树
B树到B+树的演变:非叶子节点不存储数据,叶子节点才存储数据
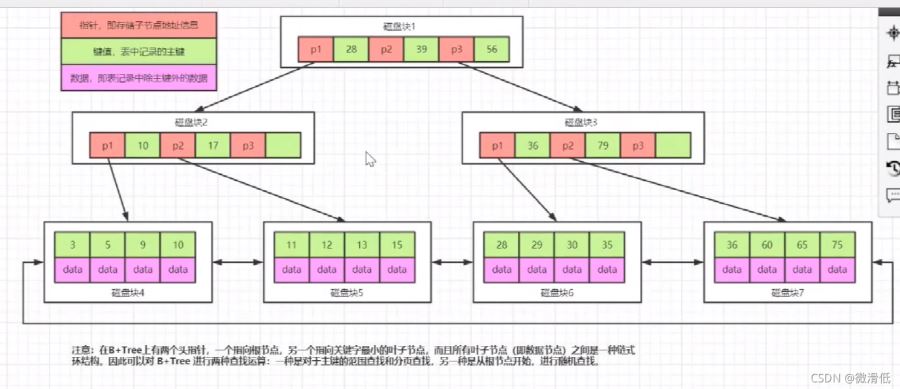
上图我们可以假设p1和28为一组占用10字节大小,那么第一层可以存储16000/10=1600个这样的大小,第二层也是1600,第三层data占用1kb,那就是16条,所以总的存储1600160016=40960000(4096万)条记录
mysql索引结构一般3~4层,但是还要注意一个问题。假设我们就是3层存储结构,如何存储更多的数据?
刚刚我们假设的是p1和28为10字节大小,那如果它们是1字节呢,那么存储总量是160001600010=4096000000。所以就引申出面试一直被提到的建立索引用int还是var好?
答:保证key的长度越小也好,varchar小于4字节用varcahr,大于4字节用int
根据B+树的特点,存储量大,查询快,所以mysql使用的就是B+树
总结
至此mysql索引系统为什么使用的是B+树就讲述完了,如果有什么讲错的地方希望能提醒我改正过来。
以上就是《MySQL的索引系统采用B+树的原因解析》的详细内容,更多关于mysql的资料请关注golang学习网公众号!
-
105 收藏
-
108 收藏
-
111 收藏
-
115 收藏
-
115 收藏
-

- 前端进阶之JavaScript设计模式
- 设计模式是开发人员在软件开发过程中面临一般问题时的解决方案,代表了最佳的实践。本课程的主打内容包括JS常见设计模式以及具体应用场景,打造一站式知识长龙服务,适合有JS基础的同学学习。
- 立即学习 543次学习
-

- GO语言核心编程课程
- 本课程采用真实案例,全面具体可落地,从理论到实践,一步一步将GO核心编程技术、编程思想、底层实现融会贯通,使学习者贴近时代脉搏,做IT互联网时代的弄潮儿。
- 立即学习 516次学习
-

- 简单聊聊mysql8与网络通信
- 如有问题加微信:Le-studyg;在课程中,我们将首先介绍MySQL8的新特性,包括性能优化、安全增强、新数据类型等,帮助学生快速熟悉MySQL8的最新功能。接着,我们将深入解析MySQL的网络通信机制,包括协议、连接管理、数据传输等,让
- 立即学习 500次学习
-

- JavaScript正则表达式基础与实战
- 在任何一门编程语言中,正则表达式,都是一项重要的知识,它提供了高效的字符串匹配与捕获机制,可以极大的简化程序设计。
- 立即学习 487次学习
-

- 从零制作响应式网站—Grid布局
- 本系列教程将展示从零制作一个假想的网络科技公司官网,分为导航,轮播,关于我们,成功案例,服务流程,团队介绍,数据部分,公司动态,底部信息等内容区块。网站整体采用CSSGrid布局,支持响应式,有流畅过渡和展现动画。
- 立即学习 485次学习
-

- 儒雅的月饼
- 感谢大佬分享,一直没懂这个问题,但其实工作中常常有遇到...不过今天到这,看完之后很有帮助,总算是懂了,感谢师傅分享技术文章!
- 2023-04-03 01:11:45
-
- 悦耳的小猫咪
- 这篇文章内容太及时了,很详细,真优秀,已收藏,关注博主了!希望博主能多写数据库相关的文章。
- 2023-03-14 20:54:55