使用 Streamlit 将机器学习模型部署为 Web 应用程序
来源:dev.to
时间:2024-08-28 19:24:56 392浏览 收藏
在IT行业这个发展更新速度很快的行业,只有不停止的学习,才不会被行业所淘汰。如果你是文章学习者,那么本文《使用 Streamlit 将机器学习模型部署为 Web 应用程序》就很适合你!本篇内容主要包括##content_title##,希望对大家的知识积累有所帮助,助力实战开发!
介绍
机器学习模型本质上是一组用于进行预测或查找数据模式的规则或机制。简单地说(不用担心过于简单化),在 Excel 中使用最小二乘法计算的趋势线也是一个模型。然而,实际应用中使用的模型并不那么简单——它们常常涉及更复杂的方程和算法,而不仅仅是简单的方程。
在这篇文章中,我将首先构建一个非常简单的机器学习模型,并将其作为一个非常简单的 Web 应用程序发布,以了解该过程。
在这里,我将只关注流程,而不是 ML 模型本身。 Alsom 我将使用 Streamlit 和 Streamlit Community Cloud 轻松发布 Python Web 应用程序。
长话短说:
使用 scikit-learn(一种流行的机器学习 Python 库),您可以快速训练数据并创建模型,只需几行代码即可完成简单任务。然后可以使用 joblib 将模型保存为可重用文件。这个保存的模型可以像 Web 应用程序中的常规 Python 库一样导入/加载,从而允许应用程序使用经过训练的模型进行预测!
应用网址:https://yh-machine-learning.streamlit.app/
GitHub:https://github.com/yoshan0921/yh-machine-learning.git
技术栈
- Python
- Streamlit:用于创建 Web 应用程序界面。
- scikit-learn:用于加载和使用预先训练的随机森林模型。
- NumPy 和 Pandas:用于数据操作和处理。
- Matplotlib 和 Seaborn:用于生成可视化。
我做了什么
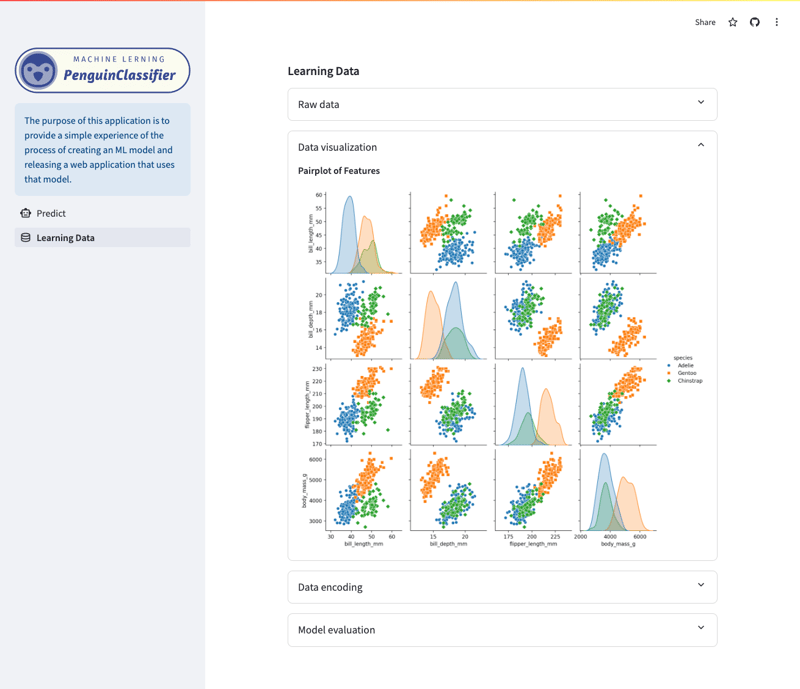
此应用程序允许您检查在帕尔默企鹅数据集上训练的随机森林模型所做的预测。 (有关训练数据的更多详细信息,请参阅本文末尾。)
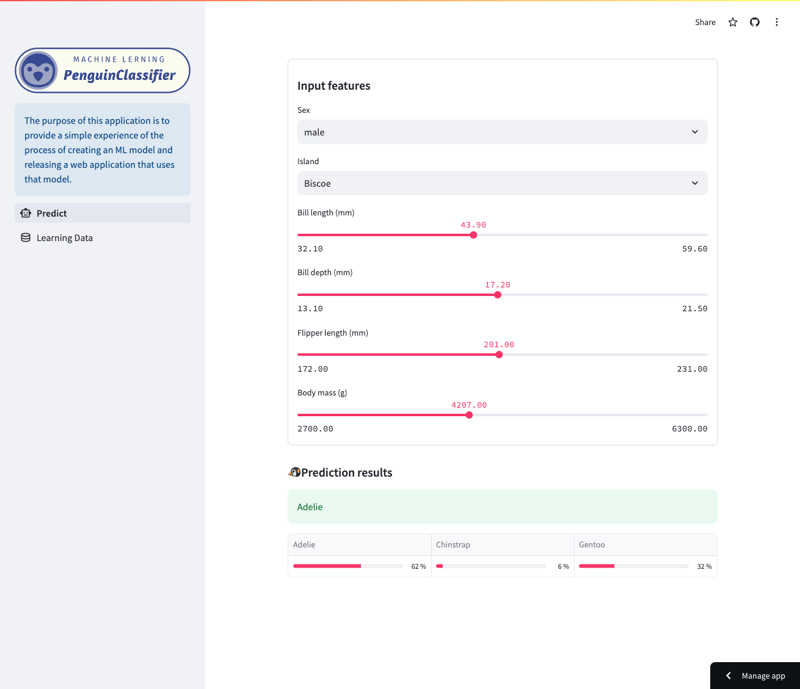
具体来说,该模型根据各种特征来预测企鹅物种,包括物种、岛屿、喙长、鳍状肢长度、体型和性别。用户可以导航应用程序以查看不同的特征如何影响模型的预测。
预测屏幕
学习数据/可视化屏幕
开发步骤
步骤1.创建模型
- Feature and Target Definition: Features (X_raw) are separated from the target variable (y_raw).
- One-hot Encoding: Categorical variables island and sex are converted into numerical format using one-hot encoding (X_encoded). The target variable species is mapped to numerical values (y_encoded).
- Data Splitting: The dataset is split into training (70%) and testing (30%) sets using train_test_split.
- Model Training: A RandomForestClassifier is trained on the training data (x_train, y_train).
- Model Evaluation: The accuracy of the model is calculated and displayed for both the training and testing sets.
- Model Saving: The trained model is saved to a file named penguin_classifier_model.pkl using joblib.
Step2. Building the Web App and Integrating the Model
-
特征和目标定义:特征(X_raw)与目标变量(y_raw)分离。
- One-hot 编码:分类变量 island 和 sex 使用 one-hot 编码 (X_encoded) 转换为数字格式。目标变量物种映射为数值(y_encoded)。
- 数据分割:使用train_test_split将数据集分割成训练集(70%)和测试集(30%)。
- 模型训练:随机森林分类器在训练数据(x_train,y_train)上进行训练。
- 模型评估:计算并显示训练集和测试集的模型准确性。
- 模型保存:训练好的模型使用 joblib 保存到名为 penguin_classifier_model.pkl 的文件中。
步骤2。构建 Web 应用程序并集成模型

用于输入特征的 Streamlit 接口:代码使用 Streamlit 创建一个交互式界面,用户可以在其中输入性别、岛屿、bill_length_mm、bill_depth_mm、flipper_length_mm 和 body_mass_g 等特征以用于预测。
数据编码和准备:用户输入被转换为 DataFrame,并对分类变量(岛屿、性别)进行 one-hot 编码。该代码通过添加模型训练期间存在的任何缺失列来确保输入数据与预期格式匹配。
- 模型加载:使用 joblib 从名为 penguin_classifier_model.pkl 的文件加载预训练的机器学习模型。这使模型准备好根据用户输入进行预测。
- 预测执行:模型根据编码的输入特征预测企鹅种类,计算每次预测的概率并转换为百分比。
- 结果展示:预测结果,包括预测的物种和每个物种的概率,都显示在Streamlit界面上,用进度条直观地表示预测的置信度。
- 关于数据集
- @allison_horst 的艺术作品 (https://github.com/allisonhorst)
种类:企鹅的种类(阿德利企鹅、帽带企鹅、巴布亚企鹅)。 ?岛屿:观察到企鹅的特定岛屿(Biscoe、Dream、Torgersen)。? ?Bill Length:企鹅的嘴的长度(毫米)。? ?Bill Depth:企鹅喙的深度(毫米)。? ?鳍状肢长度:企鹅鳍状肢的长度(毫米)。? ?体重:企鹅的质量(克)。? ?性别:企鹅的性别(雄性或雌性)。? ? ?该数据集源自 Kaggle,可以在此处访问。特征的多样性使其成为构建分类模型和了解每个特征在物种预测中的重要性的绝佳选择。? ? ?
以上就是《使用 Streamlit 将机器学习模型部署为 Web 应用程序》的详细内容,更多关于的资料请关注golang学习网公众号!
-
501 收藏
-
501 收藏
-
501 收藏
-
501 收藏
-
501 收藏
-
文章 · python教程 | 6天前 | 异步编程 · 后端工程 · Python教程 · asyncio · 超时排查 · Python 超时控制 asyncio 任务取消 wait_for 异步清理320 收藏
-
321 收藏
-
365 收藏
-
文章 · python教程 | 1星期前 | 默认值 · python · 数据建模 · dataclass · default_factory · field · Python 数据类 Field 可变默认值 dataclass default_factory228 收藏
-
文章 · python教程 | 1星期前 | 重试机制 · timeout · requests · Python教程 · 接口调试 · Python Http请求 Requests timeout retry 接口排查330 收藏
-
299 收藏
-
308 收藏
-
209 收藏
-
329 收藏
-
437 收藏
-
299 收藏
-
241 收藏
-

- 前端进阶之JavaScript设计模式
- 设计模式是开发人员在软件开发过程中面临一般问题时的解决方案,代表了最佳的实践。本课程的主打内容包括JS常见设计模式以及具体应用场景,打造一站式知识长龙服务,适合有JS基础的同学学习。
- 立即学习 543次学习
-

- GO语言核心编程课程
- 本课程采用真实案例,全面具体可落地,从理论到实践,一步一步将GO核心编程技术、编程思想、底层实现融会贯通,使学习者贴近时代脉搏,做IT互联网时代的弄潮儿。
- 立即学习 516次学习
-

- 简单聊聊mysql8与网络通信
- 如有问题加微信:Le-studyg;在课程中,我们将首先介绍MySQL8的新特性,包括性能优化、安全增强、新数据类型等,帮助学生快速熟悉MySQL8的最新功能。接着,我们将深入解析MySQL的网络通信机制,包括协议、连接管理、数据传输等,让
- 立即学习 500次学习
-

- JavaScript正则表达式基础与实战
- 在任何一门编程语言中,正则表达式,都是一项重要的知识,它提供了高效的字符串匹配与捕获机制,可以极大的简化程序设计。
- 立即学习 487次学习
-

- 从零制作响应式网站—Grid布局
- 本系列教程将展示从零制作一个假想的网络科技公司官网,分为导航,轮播,关于我们,成功案例,服务流程,团队介绍,数据部分,公司动态,底部信息等内容区块。网站整体采用CSSGrid布局,支持响应式,有流畅过渡和展现动画。
- 立即学习 485次学习