Redis+Caffeine两级缓存的实现
来源:脚本之家
时间:2022-12-30 07:58:29 203浏览 收藏
本篇文章主要是结合我之前面试的各种经历和实战开发中遇到的问题解决经验整理的,希望这篇《Redis+Caffeine两级缓存的实现》对你有很大帮助!欢迎收藏,分享给更多的需要的朋友学习~
在高性能的服务架构设计中,缓存是一个不可或缺的环节。在实际的项目中,我们通常会将一些热点数据存储到Redis或MemCache这类缓存中间件中,只有当缓存的访问没有命中时再查询数据库。在提升访问速度的同时,也能降低数据库的压力。
随着不断的发展,这一架构也产生了改进,在一些场景下可能单纯使用Redis类的远程缓存已经不够了,还需要进一步配合本地缓存使用,例如Guava cache或Caffeine,从而再次提升程序的响应速度与服务性能。于是,就产生了使用本地缓存作为一级缓存,再加上远程缓存作为二级缓存的两级缓存架构。
在先不考虑并发等复杂问题的情况下,两级缓存的访问流程可以用下面这张图来表示:
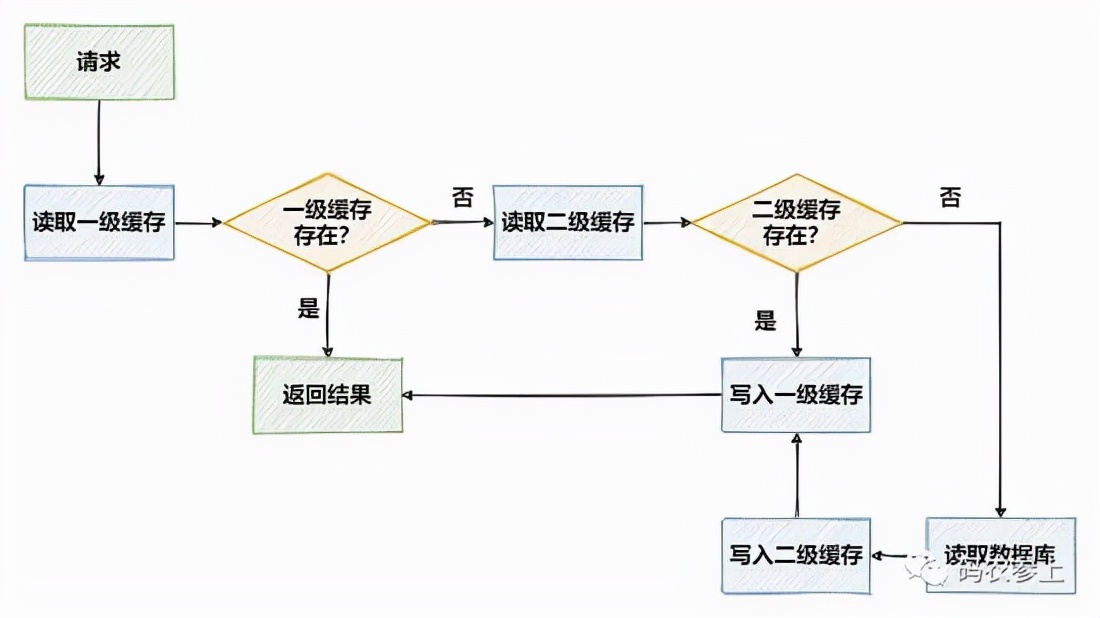
优点与问题
那么,使用两级缓存相比单纯使用远程缓存,具有什么优势呢?
- 本地缓存基于本地环境的内存,访问速度非常快,对于一些变更频率低、实时性要求低的数据,可以放在本地缓存中,提升访问速度;
- 使用本地缓存能够减少和Redis类的远程缓存间的数据交互,减少网络I/O开销,降低这一过程中在网络通信上的耗时 ;
但是在设计中,还是要考虑一些问题的,例如数据一致性问题。首先,两级缓存与数据库的数据要保持一致,一旦数据发生了修改,在修改数据库的同时,本地缓存、远程缓存应该同步更新。
另外,如果是分布式环境下,一级缓存之间也会存在一致性问题,当一个节点下的本地缓存修改后,需要通知其他节点也刷新本地缓存中的数据,否则会出现读取到过期数据的情况,这一问题可以通过类似于Redis中的发布/订阅功能解决。
此外,缓存的过期时间、过期策略以及多线程访问的问题也都需要考虑进去,不过我们今天暂时先不考虑这些问题,先看一下如何简单高效的在代码中实现两级缓存的管理。
准备工作
在简单梳理了一下要面对的问题后,下面开始两级缓存的代码实战,我们整合号称最强本地缓存的Caffeine作为一级缓存、性能之王的Redis作为二级缓存。首先建一个springboot项目,引入缓存要用到的相关的依赖:
com.github.ben-manes.caffeine caffeine 2.9.2 org.springframework.boot spring-boot-starter-data-redis org.springframework.boot spring-boot-starter-cache org.apache.commons commons-pool2 2.8.1
在application.yml中配置Redis的连接信息:
spring:
redis:
host: 127.0.0.1
port: 6379
database: 0
timeout: 10000ms
lettuce:
pool:
max-active: 8
max-wait: -1ms
max-idle: 8
min-idle: 0
在下面的例子中,我们将使用RedisTemplate来对redis进行读写操作,RedisTemplate使用前需要配置一下ConnectionFactory和序列化方式,这一过程比较简单就不贴出代码了。
下面我们在单机环境下,将按照对业务侵入性的不同程度,分三个版本来实现两级缓存的使用。
V1.0版本
我们可以通过手动操作Caffeine中的Cache对象来缓存数据,它是一个类似Map的数据结构,以key作为索引,value存储数据。在使用Cache前,需要先配置一下相关参数:
@Configuration
public class CaffeineConfig {
@Bean
public Cache caffeineCache(){
return Caffeine.newBuilder()
.initialCapacity(128)//初始大小
.maximumSize(1024)//最大数量
.expireAfterWrite(60, TimeUnit.SECONDS)//过期时间
.build();
}
}
简单解释一下Cache相关的几个参数的意义:
- initialCapacity:初始缓存空大小;
- maximumSize:缓存的最大数量,设置这个值可以避免出现内存溢出;
- expireAfterWrite:指定缓存的过期时间,是最后一次写操作后的一个时间,这里;
此外,缓存的过期策略也可以通过expireAfterAccess或refreshAfterWrite指定。
在创建完成Cache后,我们就可以在业务代码中注入并使用它了。在没有使用任何缓存前,一个只有简单的Service层代码是下面这样的,只有crud操作:
@Service
@AllArgsConstructor
public class OrderServiceImpl implements OrderService {
private final OrderMapper orderMapper;
@Override
public Order getOrderById(Long id) {
Order order = orderMapper.selectOne(new LambdaQueryWrapper()
.eq(Order::getId, id));
return order;
}
@Override
public void updateOrder(Order order) {
orderMapper.updateById(order);
}
@Override
public void deleteOrder(Long id) {
orderMapper.deleteById(id);
}
}
接下来,对上面的OrderService进行改造,在执行正常业务外再加上操作两级缓存的代码,先看改造后的查询操作:
public Order getOrderById(Long id) {
String key = CacheConstant.ORDER + id;
Order order = (Order) cache.get(key,
k -> {
//先查询 Redis
Object obj = redisTemplate.opsForValue().get(k);
if (Objects.nonNull(obj)) {
log.info("get data from redis");
return obj;
}
// Redis没有则查询 DB
log.info("get data from database");
Order myOrder = orderMapper.selectOne(new LambdaQueryWrapper()
.eq(Order::getId, id));
redisTemplate.opsForValue().set(k, myOrder, 120, TimeUnit.SECONDS);
return myOrder;
});
return order;
}
在Cache的get方法中,会先从缓存中进行查找,如果找到缓存的值那么直接返回。如果没有找到则执行后面的方法,并把结果加入到缓存中。
因此上面的逻辑就是先查找Caffeine中的缓存,没有的话查找Redis,Redis再不命中则查询数据库,写入Redis缓存的操作需要手动写入,而Caffeine的写入由get方法自己完成。
在上面的例子中,设置Caffeine的过期时间为60秒,而Redis的过期时间为120秒,下面进行测试,首先看第一次接口调用时,进行了数据库的查询:
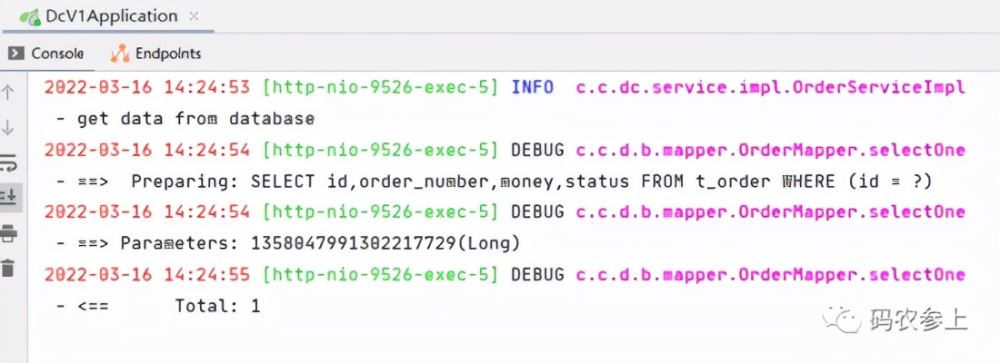
而在之后60秒内访问接口时,都没有打印打任何sql或自定义的日志内容,说明接口没有查询Redis或数据库,直接从Caffeine中读取了缓存。
等到距离第一次调用接口进行缓存的60秒后,再次调用接口:
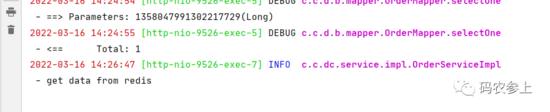
可以看到这时从Redis中读取了数据,因为这时Caffeine中的缓存已经过期了,但是Redis中的缓存没有过期仍然可用。
下面再来看一下修改操作,代码在原先的基础上添加了手动修改Redis和Caffeine缓存的逻辑:
public void updateOrder(Order order) {
log.info("update order data");
String key=CacheConstant.ORDER + order.getId();
orderMapper.updateById(order);
//修改 Redis
redisTemplate.opsForValue().set(key,order,120, TimeUnit.SECONDS);
// 修改本地缓存
cache.put(key,order);
}
看一下下面图中接口的调用、以及缓存的刷新过程。可以看到在更新数据后,同步刷新了缓存中的内容,在之后的访问接口时不查询数据库,也可以拿到正确的结果:

最后再来看一下删除操作,在删除数据的同时,手动移除Reids和Caffeine中的缓存:
public void deleteOrder(Long id) {
log.info("delete order");
orderMapper.deleteById(id);
String key= CacheConstant.ORDER + id;
redisTemplate.delete(key);
cache.invalidate(key);
}
我们在删除某个缓存后,再次调用之前的查询接口时,又会出现重新查询数据库的情况:
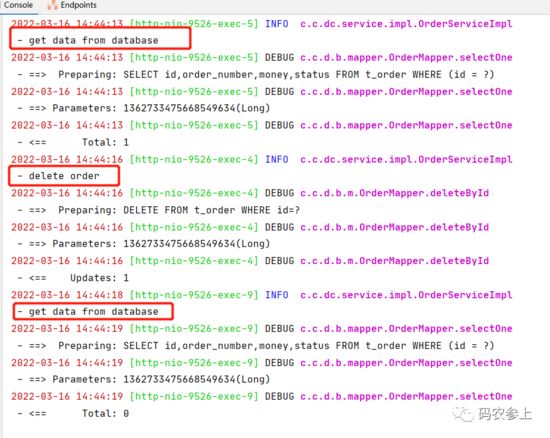
简单地演示到此为止,可以看到上面这种使用缓存的方式,虽然看起来没什么大问题,但是对代码的入侵性比较强。在业务处理的过程中要由我们频繁地操作两级缓存,会给开发人员带来很大的负担。那么,有什么方法能够简化这一过程呢?我们看看下一个版本。
V2.0版本
在spring项目中,提供了CacheManager接口和一些注解,允许让我们通过注解的方式来操作缓存。先来看一下常用的几个注解说明:
- @Cacheable:根据键从缓存中取值,如果缓存存在,那么获取缓存成功之后,直接返回这个缓存的结果。如果缓存不存在,那么执行方法,并将结果放入缓存中。
- @CachePut:不管之前的键对应的缓存是否存在,都执行方法,并将结果强制放入缓存。
- @CacheEvict:执行完方法后,会移除掉缓存中的数据。
如果要使用上面这几个注解管理缓存的话,我们就不需要配置V1版本中的那个类型为Cache的Bean了,而是需要配置spring中的CacheManager的相关参数,具体参数的配置和之前一样:
@Configuration
public class CacheManagerConfig {
@Bean
public CacheManager cacheManager(){
CaffeineCacheManager cacheManager=new CaffeineCacheManager();
cacheManager.setCaffeine(Caffeine.newBuilder()
.initialCapacity(128)
.maximumSize(1024)
.expireAfterWrite(60, TimeUnit.SECONDS));
return cacheManager;
}
}
然后在启动类上再添加上@EnableCaching注解,就可以在项目中基于注解来使用Caffeine的缓存支持了。下面,再次对Service层代码进行改造。
首先,还是改造查询方法,在方法上添加@Cacheable注解:
@Cacheable(value = "order",key = "#id")
//@Cacheable(cacheNames = "order",key = "#p0")
public Order getOrderById(Long id) {
String key= CacheConstant.ORDER + id;
//先查询 Redis
Object obj = redisTemplate.opsForValue().get(key);
if (Objects.nonNull(obj)){
log.info("get data from redis");
return (Order) obj;
}
// Redis没有则查询 DB
log.info("get data from database");
Order myOrder = orderMapper.selectOne(new LambdaQueryWrapper()
.eq(Order::getId, id));
redisTemplate.opsForValue().set(key,myOrder,120, TimeUnit.SECONDS);
return myOrder;
}
@Cacheable注解的属性多达9个,好在我们日常使用时只需要配置两个常用的就可以了。其中value和cacheNames互为别名关系,表示当前方法的结果会被缓存在哪个Cache上,应用中通过cacheName来对Cache进行隔离,每个cacheName对应一个Cache实现。value和cacheNames可以是一个数组,绑定多个Cache。
而另一个重要属性key,用来指定缓存方法的返回结果时对应的key,这个属性支持使用SpringEL表达式。通常情况下,我们可以使用下面几种方式作为key:
#参数名 #参数对象.属性名 #p参数对应下标
在上面的代码中,我们看到添加了@Cacheable注解后,在代码中只需要保留原有的业务处理逻辑和操作Redis部分的代码即可,Caffeine部分的缓存就交给spring处理了。
下面,我们再来改造一下更新方法,同样,使用@CachePut注解后移除掉手动更新Cache的操作:
@CachePut(cacheNames = "order",key = "#order.id")
public Order updateOrder(Order order) {
log.info("update order data");
orderMapper.updateById(order);
//修改 Redis
redisTemplate.opsForValue().set(CacheConstant.ORDER + order.getId(),
order, 120, TimeUnit.SECONDS);
return order;
}
注意,这里和V1版本的代码有一点区别,在之前的更新操作方法中,是没有返回值的void类型,但是这里需要修改返回值的类型,否则会缓存一个空对象到缓存中对应的key上。当下次执行查询操作时,会直接返回空对象给调用方,而不会执行方法中查询数据库或Redis的操作。
最后,删除方法的改造就很简单了,使用@CacheEvict注解,方法中只需要删除Redis中的缓存即可:
@CacheEvict(cacheNames = "order",key = "#id")
public void deleteOrder(Long id) {
log.info("delete order");
orderMapper.deleteById(id);
redisTemplate.delete(CacheConstant.ORDER + id);
}
可以看到,借助spring中的CacheManager和Cache相关的注解,对V1版本的代码经过改进后,可以把全手动操作两级缓存的强入侵代码方式,改进为本地缓存交给spring管理,Redis缓存手动修改的半入侵方式。那么,还能进一步改造,使之成为对业务代码完全无入侵的方式吗?
V3.0版本
模仿spring通过注解管理缓存的方式,我们也可以选择自定义注解,然后在切面中处理缓存,从而将对业务代码的入侵降到最低。
首先定义一个注解,用于添加在需要操作缓存的方法上:
@Target(ElementType.METHOD)
@Retention(RetentionPolicy.RUNTIME)
@Documented
public @interface DoubleCache {
String cacheName();
String key(); //支持springEl表达式
long l2TimeOut() default 120;
CacheType type() default CacheType.FULL;
}
我们使用cacheName + key作为缓存的真正key(仅存在一个Cache中,不做CacheName隔离),l2TimeOut为可以设置的二级缓存Redis的过期时间,type是一个枚举类型的变量,表示操作缓存的类型,枚举类型定义如下:
public enum CacheType {
FULL, //存取
PUT, //只存
DELETE //删除
}
因为要使key支持springEl表达式,所以需要写一个方法,使用表达式解析器解析参数:
public static String parse(String elString, TreeMapmap){ elString=String.format("#{%s}",elString); //创建表达式解析器 ExpressionParser parser = new SpelExpressionParser(); //通过evaluationContext.setVariable可以在上下文中设定变量。 EvaluationContext context = new StandardEvaluationContext(); map.entrySet().forEach(entry-> context.setVariable(entry.getKey(),entry.getValue()) ); //解析表达式 Expression expression = parser.parseExpression(elString, new TemplateParserContext()); //使用Expression.getValue()获取表达式的值,这里传入了Evaluation上下文 String value = expression.getValue(context, String.class); return value; }
参数中的elString对应的就是注解中key的值,map是将原方法的参数封装后的结果。简单进行一下测试:
public void test() {
String elString="#order.money";
String elString2="#user";
String elString3="#p0";
TreeMap map=new TreeMap();
Order order = new Order();
order.setId(111L);
order.setMoney(123D);
map.put("order",order);
map.put("user","Hydra");
String val = parse(elString, map);
String val2 = parse(elString2, map);
String val3 = parse(elString3, map);
System.out.println(val);
System.out.println(val2);
System.out.println(val3);
}
执行结果如下,可以看到支持按照参数名称、参数对象的属性名称读取,但是不支持按照参数下标读取,暂时留个小坑以后再处理。
123.0
Hydra
null
至于Cache相关参数的配置,我们沿用V1版本中的配置即可。准备工作做完了,下面我们定义切面,在切面中操作Cache来读写Caffeine的缓存,操作RedisTemplate读写Redis缓存。
@Slf4j @Component @Aspect
@AllArgsConstructor
public class CacheAspect {
private final Cache cache;
private final RedisTemplate redisTemplate;
@Pointcut("@annotation(com.cn.dc.annotation.DoubleCache)")
public void cacheAspect() {
}
@Around("cacheAspect()")
public Object doAround(ProceedingJoinPoint point) throws Throwable {
MethodSignature signature = (MethodSignature) point.getSignature();
Method method = signature.getMethod();
//拼接解析springEl表达式的map
String[] paramNames = signature.getParameterNames();
Object[] args = point.getArgs();
TreeMap treeMap = new TreeMap();
for (int i = 0; i
切面中主要做了下面几件工作:
- 通过方法的参数,解析注解中key的springEl表达式,组装真正缓存的key。
- 根据操作缓存的类型,分别处理存取、只存、删除缓存操作。
- 删除和强制更新缓存的操作,都需要执行原方法,并进行相应的缓存删除或更新操作。
- 存取操作前,先检查缓存中是否有数据,如果有则直接返回,没有则执行原方法,并将结果存入缓存。
修改Service层代码,代码中只保留原有业务代码,再添加上我们自定义的注解就可以了:
@DoubleCache(cacheName = "order", key = "#id",
type = CacheType.FULL)
public Order getOrderById(Long id) {
Order myOrder = orderMapper.selectOne(new LambdaQueryWrapper()
.eq(Order::getId, id));
return myOrder;
}
@DoubleCache(cacheName = "order",key = "#order.id",
type = CacheType.PUT)
public Order updateOrder(Order order) {
orderMapper.updateById(order);
return order;
}
@DoubleCache(cacheName = "order",key = "#id",
type = CacheType.DELETE)
public void deleteOrder(Long id) {
orderMapper.deleteById(id);
}
到这里,基于切面操作缓存的改造就完成了,Service的代码也瞬间清爽了很多,让我们可以继续专注于业务逻辑处理,而不用费心去操作两级缓存了。
总结本文按照对业务入侵的递减程度,依次介绍了三种管理两级缓存的方法。至于在项目中是否需要使用二级缓存,需要考虑自身业务情况,如果Redis这种远程缓存已经能够满足你的业务需求,那么就没有必要再使用本地缓存了。毕竟实际使用起来远没有那么简单,本文中只是介绍了最基础的使用,实际中的并发问题、事务的回滚问题都需要考虑,还需要思考什么数据适合放在一级缓存、什么数据适合放在二级缓存等等的其他问题。
理论要掌握,实操不能落!以上关于《Redis+Caffeine两级缓存的实现》的详细介绍,大家都掌握了吧!如果想要继续提升自己的能力,那么就来关注golang学习网公众号吧!
-
数据库 · Redis | 9小时前 | Redis · go · Pipeline · 批处理 · 重试 · 幂等性 · 重试 go-redis 幂等键 批量写入 Redis Pipeline 逐条结果391 收藏
-
154 收藏
-
386 收藏
-
127 收藏
-
422 收藏
-
326 收藏
-
494 收藏
-
数据库 · Redis | 3天前 | Redis · 缓存 · 限流 · Redis 8.8 · INCREX · Redis 8.8 INCREX Redis窗口限流 Redis计数器 ENX UBOUND123 收藏
-
数据库 · Redis | 5天前 | Redis · 缓存 · go · Redis Cluster · 排错 · Redis Cluster CROSSSLOT Hash Tag MGET CLUSTER KEYSLOT259 收藏
-
183 收藏
-
413 收藏
-
数据库 · Redis | 1星期前 | Redis · 安全配置 · 数据库运维 · ACL · 网络隔离 · Redis公网暴露 Redis protected-mode Redis ACL Redis安全配置 Redis审计364 收藏
-

- 前端进阶之JavaScript设计模式
- 设计模式是开发人员在软件开发过程中面临一般问题时的解决方案,代表了最佳的实践。本课程的主打内容包括JS常见设计模式以及具体应用场景,打造一站式知识长龙服务,适合有JS基础的同学学习。
- 立即学习 543次学习
-

- GO语言核心编程课程
- 本课程采用真实案例,全面具体可落地,从理论到实践,一步一步将GO核心编程技术、编程思想、底层实现融会贯通,使学习者贴近时代脉搏,做IT互联网时代的弄潮儿。
- 立即学习 516次学习
-

- 简单聊聊mysql8与网络通信
- 如有问题加微信:Le-studyg;在课程中,我们将首先介绍MySQL8的新特性,包括性能优化、安全增强、新数据类型等,帮助学生快速熟悉MySQL8的最新功能。接着,我们将深入解析MySQL的网络通信机制,包括协议、连接管理、数据传输等,让
- 立即学习 500次学习
-

- JavaScript正则表达式基础与实战
- 在任何一门编程语言中,正则表达式,都是一项重要的知识,它提供了高效的字符串匹配与捕获机制,可以极大的简化程序设计。
- 立即学习 487次学习
-

- 从零制作响应式网站—Grid布局
- 本系列教程将展示从零制作一个假想的网络科技公司官网,分为导航,轮播,关于我们,成功案例,服务流程,团队介绍,数据部分,公司动态,底部信息等内容区块。网站整体采用CSSGrid布局,支持响应式,有流畅过渡和展现动画。
- 立即学习 485次学习
-

- 阳光的玫瑰
- 细节满满,已收藏,感谢作者大大的这篇技术贴,我会继续支持!
- 2023-01-17 23:16:58
-
- 如意的蜗牛
- 这篇文章内容出现的刚刚好,老哥加油!
- 2023-01-09 20:03:43
-
- 酷炫的西牛
- 这篇技术贴太及时了,太全面了,很好,已加入收藏夹了,关注博主了!希望博主能多写数据库相关的文章。
- 2023-01-07 18:36:04
-
- 要减肥的老虎
- 很好,一直没懂这个问题,但其实工作中常常有遇到...不过今天到这,看完之后很有帮助,总算是懂了,感谢作者大大分享博文!
- 2022-12-31 11:00:06