Redis高并发情况下并发扣减库存项目实战
来源:脚本之家
时间:2022-12-31 17:07:50 452浏览 收藏
知识点掌握了,还需要不断练习才能熟练运用。下面golang学习网给大家带来一个数据库开发实战,手把手教大家学习《Redis高并发情况下并发扣减库存项目实战》,在实现功能的过程中也带大家重新温习相关知识点,温故而知新,回头看看说不定又有不一样的感悟!
相信大家从网上学习项目大部分人第一个项目都是电商,生活中时时刻刻也会用到电商APP,例如淘宝,京东等。做技术的人都知道,电商的业务逻辑简单,但是大部分电商都会涉及到高并发高可用,对并发和对数据的处理要求是很高的。这里我今天就讲一下高并发情况下是如何扣减库存的?
我们对扣减库存所需要关注的技术点如下:
- 当前剩余的数量大于等于当前需要扣减的数量,不允许超卖
- 对于同一个数据的数量存在用户并发扣减,需要保证并发的一致性
- 需要保证可用性和性能,性能至少是秒级
- 一次的扣减包含多个目标数量
- 当次扣减有多个数量时,其中一个扣减不成功即不成功,需要回滚
- 必须有扣减才能有归还
- 返还的数量必须要加回,不能丢失
- 一次扣减可以有多次返还
- 返还需要保证幂等性
第一种方案:纯MySQL扣减实现
顾名思义,就是扣减业务完全依赖MySQL等数据库来完成。而不依赖一些其他的中间件或者缓存。纯数据库实现的好处就是逻辑简单,开发以及部署成本低。(适用于中小型电商)。
纯数据库的实现之所以能够满足扣减业务的各项功能要求,主要依赖两点:
- 基于数据库的乐观锁方式保证并发扣减的强一致性
- 基于数据库的事务实现批量扣减失败进行回滚
基于上述方案,它包含一个扣减服务和一个数量数据库
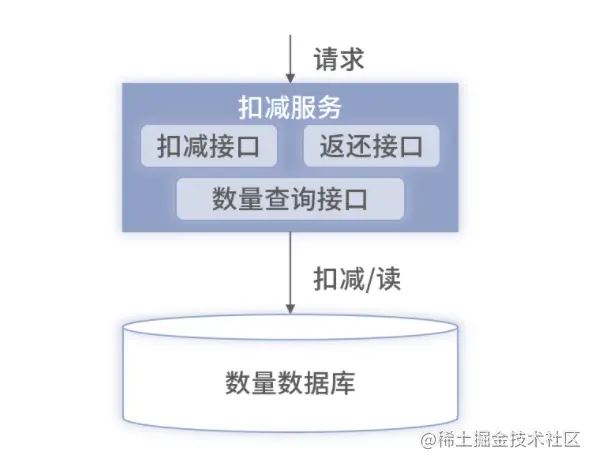
如果数据量单库压力很大,也可以做主从和分库分表,服务可以做集群等。
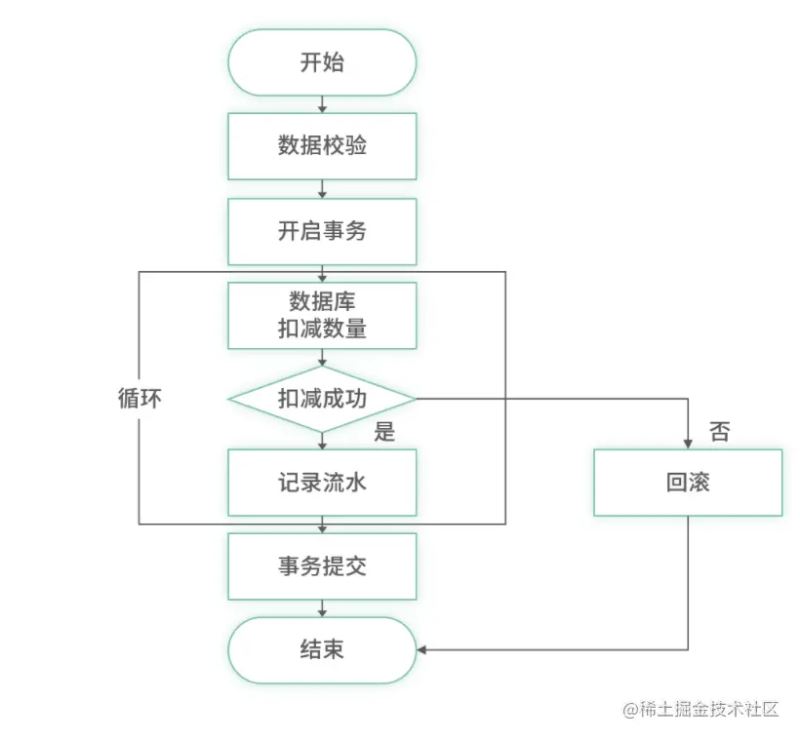
一次完整的流程就是先进行数据校验,在其中做一些参数格式校验,这里做接口开发的时候,要保持一个原则就是不信任原则,一切数据都不要相信,都需要做校验判断。其次,还可以进行库存扣减的前置校验。比如当前库存中的库存只有8个,而用户要购买10个,此时的数据校验中即可前置拦截,减少对于数据库的写操作。纯读不会加锁,性能较高,可以采用此种方式提升并发量。
update xxx set leavedAmount=leavedAmount-currentAmount where skuid='xxx' and leavedAmount>=currentAmount
此SQL采用了类似乐观锁的方式实现了原子性。在where后面判断剩余数量大于等于需要的数量,才能成功,否则失败。
扣减完成之后,需要记录流水数据。每一次扣减的时候,都需要外部用户传入一个uuid作为流水编号,此编号是全局唯一的。用户在扣减时传入唯一的编号有两个作用:
- 当用户归还数量时,需要带回此编码,用来标识此次返还属于历史上的哪次扣减。
- 进行幂等性控制。当用户调用扣减接口出现超时时,因为用户不知道是否成功,用户可以采用此编号进行重试或反查。在重试时,使用此编号进行标识防重
当用户只购买某个商品一个的时候,如果校验时剩余库存有8个,此时校验通过。但在后续的实际扣减时,因为其他用户也在并发的扣减,可能会出现幻读,此时用户实际去扣减时不足一个,导致失败。这种场景会导致多一次数据库查询,降低整体的扣减性能。这时候可以对MySQL架构进行升级
MySQL架构升级
多一次查询,就会增加数据库的压力,同时对整体性能也有一定的影响。此外,对外提供的查询库存数量的接口也会对数据库产生压力,同时读的请求要远大于写。
根据业务场景分析,读库存的请求一般是顾客浏览商品时产生,而调用扣减库存的请求基本上是用户购买时才触发。用户购买请求的业务价值比读请求会更大,因此对于写需要重点保障。针对上述的问题,可以对MySQL整体架构进行升级
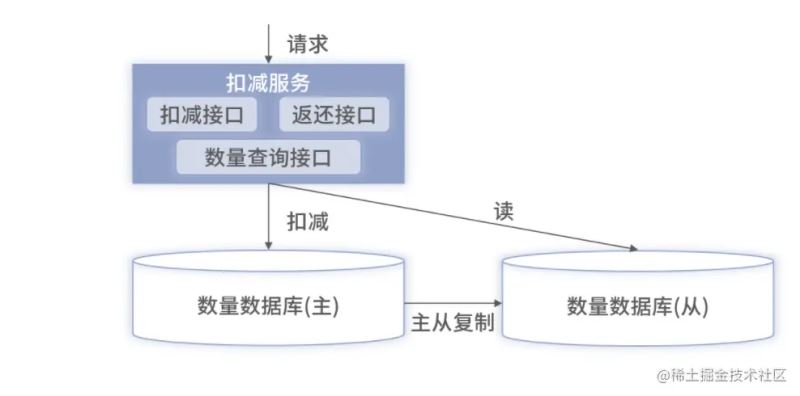
整体的升级策略采用读写分离的方式,另外主从复制直接使用MySQL等数据库已有的功能,改动上非常小,只要在扣减服务里配置两个数据源。当客户查询剩余库存,扣减服务中的前置校验时,读取从数据库即可。而真正的数据扣减还是使用主数据库。
读写分离之后,根据二八原则,80% 的均为读流量,主库的压力降低了 80%。但采用了读写分离也会导致读取的数据不准确的问题,不过库存数量本身就在实时变化,短暂的差异业务上是可以容忍的,最终的实际扣减会保证数据的准确性。
在上面基础上,还可以升级,增加缓存
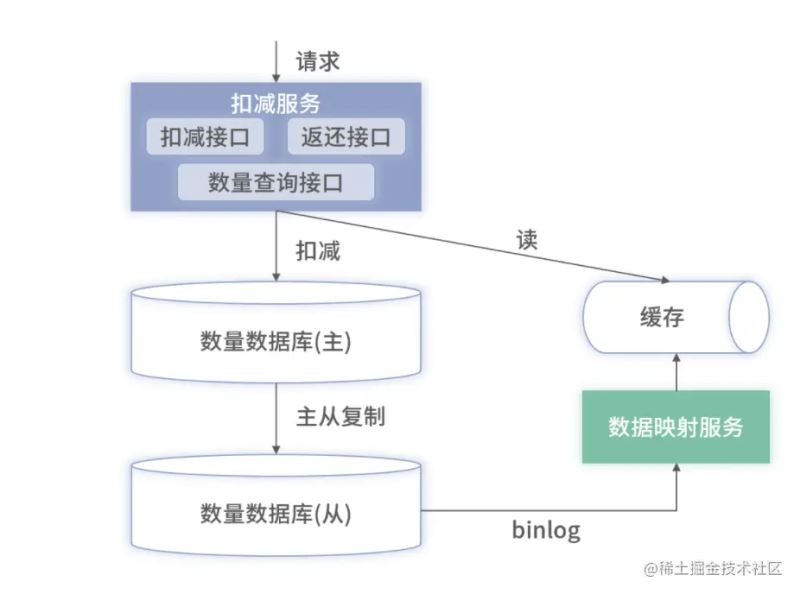
纯数据库的方案虽然可以避免超卖和少卖的情况,但是并发量实在很低,性能不是很乐观。所以这里再进行升级
第二种方案:缓存实现扣减
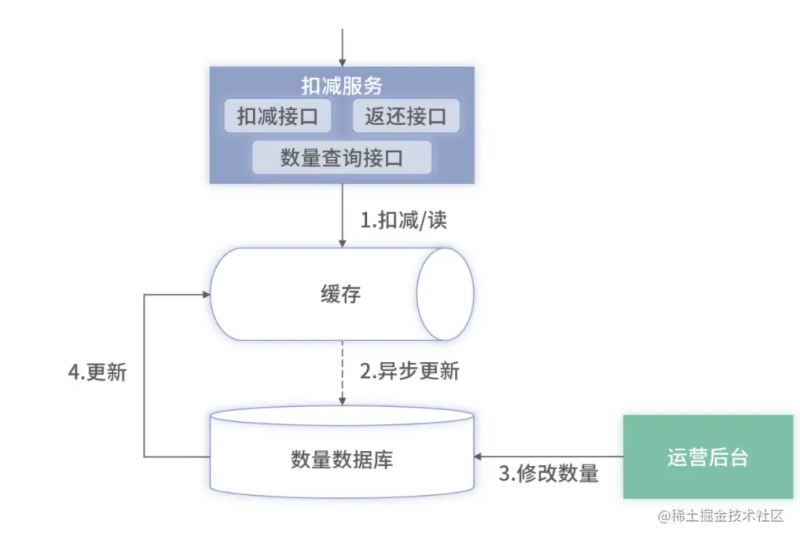
这和前面的扣减库存其实是一样的。但是此时扣减服务依赖的是Redis而不是数据库了。
这里针对Redis的hash结构不支持多个key的批量操作问题,我们可以采用Redis+lua脚本来实现批量扣减单线程请求。
升级成纯Redis实现扣减也会有问题
- Redis挂了,如果还没有执行到扣减Redis里面库存的操作挂了,只需要返回给客户端失败即可。如果已经执行到Redis扣减库存之后挂了。那这时候就需要有一个对账程序。通过对比Redis与数据库中的数据是否一致,并结合扣减服务的日志。当发现数据不一致同时日志记录扣减失败时,可以将数据库比Redis多的库存数据在Redis进行加回。
- Redis扣减完成,异步刷新数据库失败了。此时Redis里面的数据是准的,数据库的库存是多的。在结合扣减服务的日志确定是Redis扣减成功到但异步记录数据失败后,可以将数据库比Redis多的库存数据在数据库中进行扣减。
虽然使用纯Redis方案可以提高并发量,但是因为Redis不具备事务特性,极端情况下会存在Redis的数据无法回滚,导致出现少卖的情况。也可能发生异步写库失败,导致多扣的数据再也无法找回的情况。
第三种方案:数据库+缓存 顺序写的性能更好
在向磁盘进行数据操作时,向文件末尾不断追加写入的性能要远大于随机修改的性能。因为对于传统的机械硬盘来说,每一次的随机更新都需要机械键盘的磁头在硬盘的盘面上进行寻址,再去更新目标数据,这种方式十分消耗性能。而向文件末尾追加写入,每一次的写入只需要磁头一次寻址,将磁头定位到文件末尾即可,后续的顺序写入不断追加即可。
对于固态硬盘来说,虽然避免了磁头移动,但依然存在一定的寻址过程。此外,对文件内容的随机更新和数据库的表更新比较类似,都存在加锁带来的性能消耗。
数据库同样是插入要比更新的性能好。对于数据库的更新,为了保证对同一条数据并发更新的一致性,会在更新时增加锁,但加锁是十分消耗性能的。此外,对于没有索引的更新条件,要想找到需要更新的那条数据,需要遍历整张表,时间复杂度为 O(N)。而插入只在末尾进行追加,性能非常好。
顺序写的架构
通过上面的理论就可以得出一个兼具性能和高可靠的扣减架构
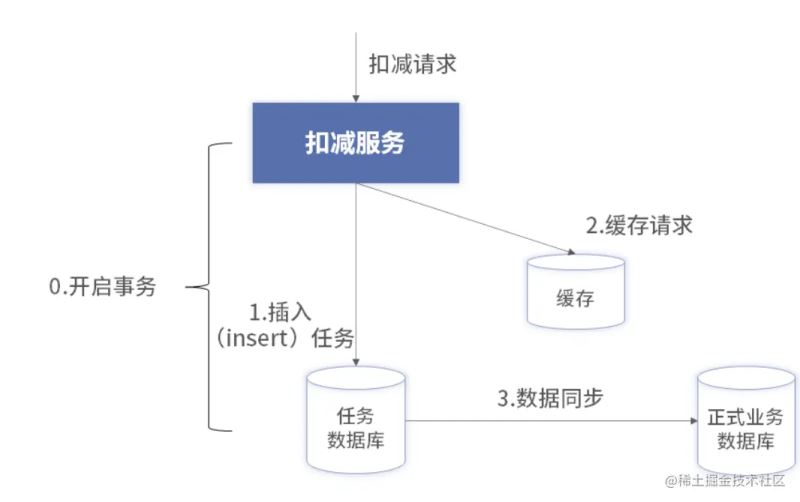
上述的架构和纯缓存的架构区别在于,写入数据库不是异步写入,而是在扣减的时候同步写入。同步写入数据库使用的是insert操作,就是顺序写,而不是update做数据库数量的修改,所以,性能会更好。
insert 的数据库称为任务库,它只存储每次扣减的原始数据,而不做真实扣减(即不进行 update)。它的表结构大致如下:
create table task{
id bigint not null comment "任务顺序编号",
task_id bigint not null
}
任务表里存储的内容格式可以为 JSON、XML 等结构化的数据。以 JSON 为例,数据内容大致可以如下:
{
"扣减号":uuid,
"skuid1":"数量",
"skuid2":"数量",
"xxxx":"xxxx"
}
这里我们肯定是还有一个记录业务数据的库,这里存储的是真正的扣减名企和SKU的汇总数据。对于另一个库里面的数据,只需要通过这个表进行异步同步就好了。
扣减流程
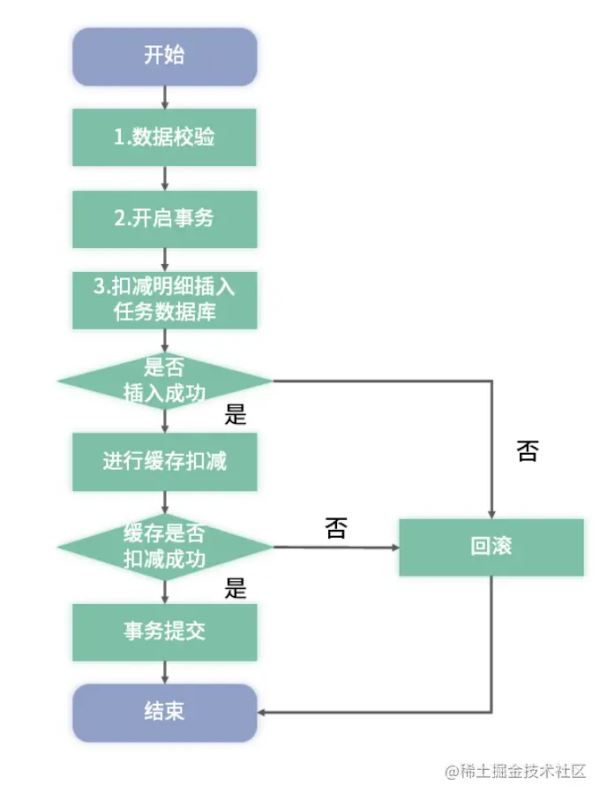
这里和纯缓存的区别在于增加了事务开启与回滚的步骤,以及同步的数据库写入流程
任务库里存储的是纯文本的 JSON 数据,无法被直接使用。需要将其中的数据转储至实际的业务库里。业务库里会存储两类数据,一类是每次扣减的流水数据,它与任务表里的数据区别在于它是结构化,而不是 JSON 文本的大字段内容。另外一类是汇总数据,即每一个 SKU 当前总共有多少量,当前还剩余多少量(即从任务库同步时需要进行扣减的),表结构大致如下:
create table 流水表{
id bigint not null,
uuid bigint not null comment '扣减编号',
sku_id bigint not null comment '商品编号',
num int not null comment '当次扣减的数量'
}comment '扣减流水表'
商品的实时数据汇总表,结构如下:
create table 汇总表{
id bitint not null,
sku_id unsigned bigint not null comment '商品编号',
total_num unsigned int not null comment '总数量',
leaved_num unsigned int not null comment '当前剩余的商品数量'
}comment '记录表'
在整体的流程上,还是复用了上一讲纯缓存的架构流程。当新加入一个商品,或者对已有商品进行补货时,对应的新增商品数量都会通过 Binlog 同步至缓存里。在扣减时,依然以缓存中的数量为准
以上就是《Redis高并发情况下并发扣减库存项目实战》的详细内容,更多关于redis的资料请关注golang学习网公众号!
-
136 收藏
-
458 收藏
-
422 收藏
-
326 收藏
-
494 收藏
-
数据库 · Redis | 1天前 | Redis · 缓存 · 限流 · Redis 8.8 · INCREX · Redis 8.8 INCREX Redis窗口限流 Redis计数器 ENX UBOUND123 收藏
-
数据库 · Redis | 3天前 | Redis · 缓存 · go · Redis Cluster · 排错 · Redis Cluster CROSSSLOT Hash Tag MGET CLUSTER KEYSLOT259 收藏
-
183 收藏
-
413 收藏
-
数据库 · Redis | 5天前 | Redis · 安全配置 · 数据库运维 · ACL · 网络隔离 · Redis公网暴露 Redis protected-mode Redis ACL Redis安全配置 Redis审计364 收藏
-
250 收藏
-
110 收藏
-
366 收藏
-
449 收藏
-

- 前端进阶之JavaScript设计模式
- 设计模式是开发人员在软件开发过程中面临一般问题时的解决方案,代表了最佳的实践。本课程的主打内容包括JS常见设计模式以及具体应用场景,打造一站式知识长龙服务,适合有JS基础的同学学习。
- 立即学习 543次学习
-

- GO语言核心编程课程
- 本课程采用真实案例,全面具体可落地,从理论到实践,一步一步将GO核心编程技术、编程思想、底层实现融会贯通,使学习者贴近时代脉搏,做IT互联网时代的弄潮儿。
- 立即学习 516次学习
-

- 简单聊聊mysql8与网络通信
- 如有问题加微信:Le-studyg;在课程中,我们将首先介绍MySQL8的新特性,包括性能优化、安全增强、新数据类型等,帮助学生快速熟悉MySQL8的最新功能。接着,我们将深入解析MySQL的网络通信机制,包括协议、连接管理、数据传输等,让
- 立即学习 500次学习
-

- JavaScript正则表达式基础与实战
- 在任何一门编程语言中,正则表达式,都是一项重要的知识,它提供了高效的字符串匹配与捕获机制,可以极大的简化程序设计。
- 立即学习 487次学习
-

- 从零制作响应式网站—Grid布局
- 本系列教程将展示从零制作一个假想的网络科技公司官网,分为导航,轮播,关于我们,成功案例,服务流程,团队介绍,数据部分,公司动态,底部信息等内容区块。网站整体采用CSSGrid布局,支持响应式,有流畅过渡和展现动画。
- 立即学习 485次学习
-

- 爱撒娇的草莓
- 很详细,已加入收藏夹了,感谢师傅的这篇文章,我会继续支持!
- 2023-01-14 08:17:24
-
- 热情的跳跳糖
- 这篇技术文章真是及时雨啊,太全面了,真优秀,已加入收藏夹了,关注楼主了!希望楼主能多写数据库相关的文章。
- 2023-01-13 17:44:03
-
- 懦弱的帽子
- 写的不错,一直没懂这个问题,但其实工作中常常有遇到...不过今天到这,看完之后很有帮助,总算是懂了,感谢老哥分享博文!
- 2023-01-06 20:18:54
-
- 动听的唇彩
- 这篇技术贴太及时了,太详细了,受益颇多,已收藏,关注大佬了!希望大佬能多写数据库相关的文章。
- 2023-01-01 08:29:46