redis专属链表ziplist的使用
来源:脚本之家
时间:2023-01-01 13:16:22 359浏览 收藏
知识点掌握了,还需要不断练习才能熟练运用。下面golang学习网给大家带来一个数据库开发实战,手把手教大家学习《redis专属链表ziplist的使用》,在实现功能的过程中也带大家重新温习相关知识点,温故而知新,回头看看说不定又有不一样的感悟!
问题抛出
用过 Python 的列表吗?就是那种可以存储任意类型数据的,支持随机读取的数据结构。
没有用过的话那就没办法了。
本质上这种列表可以使用数组、链表作为其底层结构,不知道Python中的列表是以什么作为底层结构的。
但是redis的列表既不是用链表,也不是用数组作为其底层实现的,原因也显而易见:数组不方便,弄个二维的?柔性的?怎么写?链表可以实现,通用链表嘛,数据域放 void* 就可以实现列表功能。但是,链表的缺点也很明显,容易造成内存碎片。
在这个大环境下,秉承着“能省就省”的指导思想,请你设计一款数据结构。
结构设计
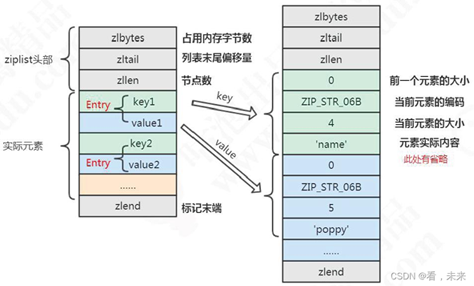
这个图里要注意,右侧是没有记录“当前元素的大小”的
这个图挺详细哈,都省得我对每一个字段释义了,整挺好。
其他话,文件开头的注释也讲的很清楚了。(ziplist.c)
/* The ziplist is a specially encoded dually linked list that is designed * to be very memory efficient. It stores both strings and integer values, * where integers are encoded as actual integers instead of a series of * characters. It allows push and pop operations on either side of the list * in O(1) time. However, because every operation requires a reallocation of * the memory used by the ziplist, the actual complexity is related to the * amount of memory used by the ziplist. * * ---------------------------------------------------------------------------- * * ZIPLIST OVERALL LAYOUT * ====================== * * The general layout of the ziplist is as follows: * *... * * NOTE: all fields are stored in little endian, if not specified otherwise. * * is an unsigned integer to hold the number of bytes that * the ziplist occupies, including the four bytes of the zlbytes field itself. * This value needs to be stored to be able to resize the entire structure * without the need to traverse it first. * * is the offset to the last entry in the list. This allows * a pop operation on the far side of the list without the need for full * traversal. * * is the number of entries. When there are more than * 2^16-2 entries, this value is set to 2^16-1 and we need to traverse the * entire list to know how many items it holds. * * is a special entry representing the end of the ziplist. * Is encoded as a single byte equal to 255. No other normal entry starts * with a byte set to the value of 255. * * ZIPLIST ENTRIES * =============== * * Every entry in the ziplist is prefixed by metadata that contains two pieces * of information. First, the length of the previous entry is stored to be * able to traverse the list from back to front. Second, the entry encoding is * provided. It represents the entry type, integer or string, and in the case * of strings it also represents the length of the string payload. * So a complete entry is stored like this: * * * * Sometimes the encoding represents the entry itself, like for small integers * as we'll see later. In such a case the part is missing, and we * could have just: * * * * The length of the previous entry, , is encoded in the following way: * If this length is smaller than 254 bytes, it will only consume a single * byte representing the length as an unsinged 8 bit integer. When the length * is greater than or equal to 254, it will consume 5 bytes. The first byte is * set to 254 (FE) to indicate a larger value is following. The remaining 4 * bytes take the length of the previous entry as value. * * So practically an entry is encoded in the following way: * * * * Or alternatively if the previous entry length is greater than 253 bytes * the following encoding is used: * * 0xFE * * The encoding field of the entry depends on the content of the * entry. When the entry is a string, the first 2 bits of the encoding first * byte will hold the type of encoding used to store the length of the string, * followed by the actual length of the string. When the entry is an integer * the first 2 bits are both set to 1. The following 2 bits are used to specify * what kind of integer will be stored after this header. An overview of the * different types and encodings is as follows. The first byte is always enough * to determine the kind of entry. * * |00pppppp| - 1 byte * String value with length less than or equal to 63 bytes (6 bits). * "pppppp" represents the unsigned 6 bit length. * |01pppppp|qqqqqqqq| - 2 bytes * String value with length less than or equal to 16383 bytes (14 bits). * IMPORTANT: The 14 bit number is stored in big endian. * |10000000|qqqqqqqq|rrrrrrrr|ssssssss|tttttttt| - 5 bytes * String value with length greater than or equal to 16384 bytes. * Only the 4 bytes following the first byte represents the length * up to 2^32-1. The 6 lower bits of the first byte are not used and * are set to zero. * IMPORTANT: The 32 bit number is stored in big endian. * |11000000| - 3 bytes * Integer encoded as int16_t (2 bytes). * |11010000| - 5 bytes * Integer encoded as int32_t (4 bytes). * |11100000| - 9 bytes * Integer encoded as int64_t (8 bytes). * |11110000| - 4 bytes * Integer encoded as 24 bit signed (3 bytes). * |11111110| - 2 bytes * Integer encoded as 8 bit signed (1 byte). * |1111xxxx| - (with xxxx between 0000 and 1101) immediate 4 bit integer. * Unsigned integer from 0 to 12. The encoded value is actually from * 1 to 13 because 0000 and 1111 can not be used, so 1 should be * subtracted from the encoded 4 bit value to obtain the right value. * |11111111| - End of ziplist special entry. * * Like for the ziplist header, all the integers are represented in little * endian byte order, even when this code is compiled in big endian systems. * * EXAMPLES OF ACTUAL ZIPLISTS * =========================== * * The following is a ziplist containing the two elements representing * the strings "2" and "5". It is composed of 15 bytes, that we visually * split into sections: * * [0f 00 00 00] [0c 00 00 00] [02 00] [00 f3] [02 f6] [ff] * | | | | | | * zlbytes zltail entries "2" "5" end * * The first 4 bytes represent the number 15, that is the number of bytes * the whole ziplist is composed of. The second 4 bytes are the offset * at which the last ziplist entry is found, that is 12, in fact the * last entry, that is "5", is at offset 12 inside the ziplist. * The next 16 bit integer represents the number of elements inside the * ziplist, its value is 2 since there are just two elements inside. * Finally "00 f3" is the first entry representing the number 2. It is * composed of the previous entry length, which is zero because this is * our first entry, and the byte F3 which corresponds to the encoding * |1111xxxx| with xxxx between 0001 and 1101. We need to remove the "F" * higher order bits 1111, and subtract 1 from the "3", so the entry value * is "2". The next entry has a prevlen of 02, since the first entry is * composed of exactly two bytes. The entry itself, F6, is encoded exactly * like the first entry, and 6-1 = 5, so the value of the entry is 5. * Finally the special entry FF signals the end of the ziplist. * * Adding another element to the above string with the value "Hello World" * allows us to show how the ziplist encodes small strings. We'll just show * the hex dump of the entry itself. Imagine the bytes as following the * entry that stores "5" in the ziplist above: * * [02] [0b] [48 65 6c 6c 6f 20 57 6f 72 6c 64] * * The first byte, 02, is the length of the previous entry. The next * byte represents the encoding in the pattern |00pppppp| that means * that the entry is a string of length , so 0B means that * an 11 bytes string follows. From the third byte (48) to the last (64) * there are just the ASCII characters for "Hello World". * * ---------------------------------------------------------------------------- * * Copyright (c) 2009-2012, Pieter Noordhuis * Copyright (c) 2009-2017, Salvatore Sanfilippo * All rights reserved. */
看完了么?接下来就是基操阶段了,对于任何一种数据结构,基操无非增删查改。
实际节点
typedef struct zlentry {
unsigned int prevrawlensize; /* Bytes used to encode the previous entry len*/
unsigned int prevrawlen; /* Previous entry len. */
unsigned int lensize; /* Bytes used to encode this entry type/len.
For example strings have a 1, 2 or 5 bytes
header. Integers always use a single byte.*/
unsigned int len; /* Bytes used to represent the actual entry.
For strings this is just the string length
while for integers it is 1, 2, 3, 4, 8 or
0 (for 4 bit immediate) depending on the
number range. */
unsigned int headersize; /* prevrawlensize + lensize. */
unsigned char encoding; /* Set to ZIP_STR_* or ZIP_INT_* depending on
the entry encoding. However for 4 bits
immediate integers this can assume a range
of values and must be range-checked. */
unsigned char *p; /* Pointer to the very start of the entry, that
is, this points to prev-entry-len field. */
} zlentry;
基本操作
我觉得这张图还是要再摆一下:
这个图里要注意,右侧是没有记录“当前元素的大小”的
增
真实插入的是这个函数:
讲真,头皮有点发麻。那么我们等下还是用老套路,按步骤拆开来看。
/* Insert item at "p". */
unsigned char *__ziplistInsert(unsigned char *zl, unsigned char *p, unsigned char *s, unsigned int slen) {
size_t curlen = intrev32ifbe(ZIPLIST_BYTES(zl)), reqlen;
unsigned int prevlensize, prevlen = 0;
size_t offset;
int nextdiff = 0;
unsigned char encoding = 0;
long long value = 123456789; /* initialized to avoid warning. Using a value
that is easy to see if for some reason
we use it uninitialized. */
zlentry tail;
/* Find out prevlen for the entry that is inserted. */
if (p[0] != ZIP_END) {
ZIP_DECODE_PREVLEN(p, prevlensize, prevlen);
} else {
unsigned char *ptail = ZIPLIST_ENTRY_TAIL(zl);
if (ptail[0] != ZIP_END) {
prevlen = zipRawEntryLength(ptail);
}
}
/* See if the entry can be encoded */
if (zipTryEncoding(s,slen,&value,&encoding)) {
/* 'encoding' is set to the appropriate integer encoding */
reqlen = zipIntSize(encoding);
} else {
/* 'encoding' is untouched, however zipStoreEntryEncoding will use the
* string length to figure out how to encode it. */
reqlen = slen;
}
/* We need space for both the length of the previous entry and
* the length of the payload. */
reqlen += zipStorePrevEntryLength(NULL,prevlen);
reqlen += zipStoreEntryEncoding(NULL,encoding,slen);
/* When the insert position is not equal to the tail, we need to
* make sure that the next entry can hold this entry's length in
* its prevlen field. */
int forcelarge = 0;
nextdiff = (p[0] != ZIP_END) ? zipPrevLenByteDiff(p,reqlen) : 0;
if (nextdiff == -4 && reqlen
对“链表”插入数据有几个步骤?
1、偏移
2、插进去
3、缝合
那这个“列表”,比较特殊一点,特殊在哪里?特殊在它比较紧凑,而且数据类型,其实也就两种,要么integer,要么string。所以它的步骤是?
1、数据重新编码
2、解析数据并分配空间
3、接入数据
重新编码
什么是重新编码?插入一个元素,是不是需要对:“前一个元素的大小、本身大小、当前元素编码” 这些数据进行一个统计,然后一并插入。就编这个。
插入位置无非三个,头中尾。
头:前一个元素大小为0,因为前面没有元素。
中:待插入位置后一个元素记录的“前一个元素大小”,当然,之后本身大小就成为了后一个元素眼中的“前一个元素大小”。
尾:那就要把三个字段加起来了。
具体怎么重新编码就不看了吧,这篇本来就已经很长了。
解析数据
再往下就是解析数据了。
首先尝试将数据解析为整数,如果可以解析,就按照压缩列表整数类型编码存储;如果解析失败,就按照压缩列表字节数组类型编码存储。
解析之后,数值存储在 value 中,编码格式存储在 encoding中。如果解析成功,还要计算整数所占字节数。变量 reqlen 存储当前元素所需空间大小,再累加其他两个字段的空间大小,就是本节点所需空间大小了。
重新分配空间
看注释这架势,咋滴,还存在没地方给它塞?
来我们看看。
这里的分配空间不是简单的就新插进来的数据多少空间就分配多少,如果没有仔细阅读上面那段英文的话,嗯,可以选择绕回去仔细阅读一下那个节点组成。特别是那个:
/*
* The length of the previous entry, , is encoded in the following way:
* If this length is smaller than 254 bytes, it will only consume a single
* byte representing the length as an unsinged 8 bit integer. When the length
* is greater than or equal to 254, it will consume 5 bytes. The first byte is
* set to 254 (FE) to indicate a larger value is following. The remaining 4
* bytes take the length of the previous entry as value.
*/
所以这个 previous 就是个不确定因素。有可能人家本来是 1 1 排列的,中间插进来一个之后变成 1 1 5 排列了;也有可能人家是1 5 排列的、5 1 排列的,总之就是不确定。
所以,在 entryX 的位置插入一个数据之后,entryX+1 的 previous 可能不变,可能加四,也可能减四,谁也说不准。说不准那不就得测一下嘛。所以就测一下,仅此而已。
接入数据
数据怎么接入?鉴于这里真心不是链表,是列表。
所以,按数组那一套来。对。
很麻烦吧。其实不麻烦,你在redis里见过它给你中间插入的机会了吗?更不要说头插了,你见过它给你头插的机会了吗?
插个题外话:大数据插入时,数组不一定输给链表。在尾插的时候,数组的优势是远超链表的(当然,仅限于尾插)。在我两个月前的博客里有做过这一系列的实验。
删就不写了吧,增的逆操作,从系列开始就没写过删。不过这里删就不可避免的大量数据进行复制了(如果不真删,只是做个删除标志呢?这样会省时间,但是时候会造成内存碎片化。不过可以设计一个定期调整内存的函数,比方说重用三分之一的块之后紧凑一下?内存不够用的时候紧凑一下?STL就是这么干的)。
查也没啥好讲的了吧,这个数据结构的应用场景一般就是对键进行检索,这里就是个值,不一样的是这个值是一串的。
所以除了提供原有的前后向遍历之外,还提供了 range 查询,不难的。
以上就是《redis专属链表ziplist的使用》的详细内容,更多关于redis的资料请关注golang学习网公众号!
-
501 收藏
-
501 收藏
-
501 收藏
-
501 收藏
-
501 收藏
-
235 收藏
-
464 收藏
-
436 收藏
-
407 收藏
-
数据库 · Redis | 5天前 | Redis · Streams · 消费者组 · Pending · XACK · 消息堆积 消费者组 XACK XPENDING XAUTOCLAIM Redis Streams385 收藏
-
194 收藏
-
368 收藏
-
118 收藏
-
464 收藏
-
180 收藏
-
数据库 · Redis | 1星期前 | Redis · 消息队列 · Stream · 消费组 · redis 消息队列 Redis Stream 消费组 XREADGROUP XACK XPENDING XAUTOCLAIM187 收藏
-
139 收藏
-

- 前端进阶之JavaScript设计模式
- 设计模式是开发人员在软件开发过程中面临一般问题时的解决方案,代表了最佳的实践。本课程的主打内容包括JS常见设计模式以及具体应用场景,打造一站式知识长龙服务,适合有JS基础的同学学习。
- 立即学习 543次学习
-

- GO语言核心编程课程
- 本课程采用真实案例,全面具体可落地,从理论到实践,一步一步将GO核心编程技术、编程思想、底层实现融会贯通,使学习者贴近时代脉搏,做IT互联网时代的弄潮儿。
- 立即学习 516次学习
-

- 简单聊聊mysql8与网络通信
- 如有问题加微信:Le-studyg;在课程中,我们将首先介绍MySQL8的新特性,包括性能优化、安全增强、新数据类型等,帮助学生快速熟悉MySQL8的最新功能。接着,我们将深入解析MySQL的网络通信机制,包括协议、连接管理、数据传输等,让
- 立即学习 500次学习
-

- JavaScript正则表达式基础与实战
- 在任何一门编程语言中,正则表达式,都是一项重要的知识,它提供了高效的字符串匹配与捕获机制,可以极大的简化程序设计。
- 立即学习 487次学习
-

- 从零制作响应式网站—Grid布局
- 本系列教程将展示从零制作一个假想的网络科技公司官网,分为导航,轮播,关于我们,成功案例,服务流程,团队介绍,数据部分,公司动态,底部信息等内容区块。网站整体采用CSSGrid布局,支持响应式,有流畅过渡和展现动画。
- 立即学习 485次学习
-

- 微笑的长颈鹿
- 这篇技术贴出现的刚刚好,细节满满,受益颇多,收藏了,关注作者大大了!希望作者大大能多写数据库相关的文章。
- 2023-02-23 02:30:05
-
- 时尚的春天
- 赞 ??,一直没懂这个问题,但其实工作中常常有遇到...不过今天到这,帮助很大,总算是懂了,感谢师傅分享文章!
- 2023-02-07 22:58:57
-
- 糊涂的苗条
- 好细啊,已收藏,感谢楼主的这篇文章内容,我会继续支持!
- 2023-02-06 13:49:20
-
- 迷路的跳跳糖
- 太给力了,一直没懂这个问题,但其实工作中常常有遇到...不过今天到这,帮助很大,总算是懂了,感谢楼主分享文章!
- 2023-01-27 22:07:40
-
- 沉静的睫毛
- 细节满满,已加入收藏夹了,感谢博主的这篇博文,我会继续支持!
- 2023-01-18 07:38:16
-
- 满意的哈密瓜,数据线
- 真优秀,一直没懂这个问题,但其实工作中常常有遇到...不过今天到这,帮助很大,总算是懂了,感谢师傅分享文章内容!
- 2023-01-14 07:34:52
-
- 隐形的朋友
- 这篇文章内容真是及时雨啊,细节满满,感谢大佬分享,码住,关注大佬了!希望大佬能多写数据库相关的文章。
- 2023-01-14 00:59:16
-
- 专注的白开水
- 这篇技术贴真及时,太详细了,很好,码住,关注大佬了!希望大佬能多写数据库相关的文章。
- 2023-01-07 10:35:57
-
- 凶狠的鸭子
- 这篇技术贴真及时,作者加油!
- 2023-01-03 00:24:28