收集和处理 INMET-BDMEP 气候数据
来源:dev.to
时间:2024-10-13 12:25:04 188浏览 收藏
学习文章要努力,但是不要急!今天的这篇文章《收集和处理 INMET-BDMEP 气候数据》将会介绍到等等知识点,如果你想深入学习文章,可以关注我!我会持续更新相关文章的,希望对大家都能有所帮助!
气候数据在多个领域发挥着至关重要的作用,有助于影响农业、城市规划和自然资源管理等领域的研究和预测。
国家气象研究所(inmet)每月在其网站上提供气象数据库(bdmep)。该数据库包含分布在巴西各地的数百个测量站收集的一系列历史气候信息。在bdmep中,您可以找到有关降雨量、温度、空气湿度和风速的详细数据。
每小时更新一次,数据量相当大,为详细分析和明智决策提供了丰富的基础。
在这篇文章中,我将展示如何从 inmet-bdmep 收集和处理气候数据。我们将收集 inmet 网站上提供的原始数据文件,然后处理这些数据以方便分析。
1. 所需的python包
要实现上述目标,您只需要安装三个软件包:
- httpx 发出 http 请求
- pandas 用于读取和处理数据
- tqdm 在程序下载或读取文件时在终端中显示友好的进度条
要安装必要的软件包,请在终端中运行以下命令:
pip install httpx pandas tqdm
例如,如果您使用诗歌虚拟环境 (venv),请使用以下命令:
poetry add httpx pandas tqdm
2. 文件收集
2.1 文件 url 模式
bdmep 数据文件的地址遵循非常简单的模式。图案如下:
https://portal.inmet.gov.br/uploads/dadoshistoricos/{year}.zip
唯一改变的部分是文件名,它只是数据的参考年份。每月,最近(当前)年份的文件会替换为更新的数据。
这使得创建代码来自动收集所有可用年份的数据文件变得容易。
事实上,可用的历史系列是从 2000 年开始的。
2.2 采集策略
为了从 inmet-bdmep 收集数据文件,我们将使用 httpx 库发出 http 请求,并使用 tqdm 库在终端中显示友好的进度条。
首先,让我们导入必要的包:
import datetime as dt from pathlib import path import httpx from tqdm import tqdm
我们已经确定了 inmet-bdmep 数据文件的 url 模式。现在让我们创建一个接受年份作为参数并返回该年份文件的 url 的函数。
def build_url(year):
return f"https://portal.inmet.gov.br/uploads/dadoshistoricos/{year}.zip"
要检查 url 文件是否已更新,我们可以使用 http 请求返回的标头中存在的信息。在配置良好的服务器上,我们可以使用 head 方法仅请求此标头。在这种情况下,服务器配置良好,我们可以使用此方法。
对 head 请求的响应将采用以下格式:
mon, 01 sep 2024 00:01:00 gmt
为了解析这个日期/时间,我在 python 中创建了以下函数,它接受 字符串 并返回一个日期时间对象:
def parse_last_modified(last_modified: str) -> dt.datetime:
return dt.datetime.strptime(
last_modified,
"%a, %d %b %y %h:%m:%s %z"
)
因此,我们可以使用字符串插值(f-strings),使用上次修改的日期/时间将其包含在我们要下载的文件的名称中:
def build_local_filename(year: int, last_modified: dt.datetime) -> str:
return f"inmet-bdmep_{year}_{last_modified:%y%m%d}.zip"
这样,您可以轻松检查我们的本地文件系统中是否已存在包含最新数据的文件。如果文件已经存在,则可以终止程序;否则,我们必须继续收集文件,向服务器发出请求。
下面的 download_year 函数下载特定年份的文件。如果目标目录中已存在该文件,该函数将简单地返回而不执行任何操作。
请注意我们如何使用 tqdm 在下载文件时在终端中显示友好的进度条。
def download_year(
year: int,
destdirpath: path,
blocksize: int = 2048,
) -> none:
if not destdirpath.exists():
destdirpath.mkdir(parents=true)
url = build_url(year)
headers = httpx.head(url).headers
last_modified = parse_last_modified(headers["last-modified"])
file_size = int(headers.get("content-length", 0))
destfilename = build_local_filename(year, last_modified)
destfilepath = destdirpath / destfilename
if destfilepath.exists():
return
with httpx.stream("get", url) as r:
pb = tqdm(
desc=f"{year}",
dynamic_ncols=true,
leave=true,
total=file_size,
unit="ib",
unit_scale=true,
)
with open(destfilepath, "wb") as f:
for data in r.iter_bytes(blocksize):
f.write(data)
pb.update(len(data))
pb.close()
2.3 文件收集
现在我们已经具备了所有必要的功能,我们可以收集 inmet-bdmep 数据文件了。
使用 for 循环,我们可以下载所有可用年份的文件。下面的代码正是这样做的。从2000年开始至今年。
destdirpath = path("data")
for year in range(2000, dt.datetime.now().year + 1):
download_year(year, destdirpath)
3.数据的读取和处理
下载 inmet-bdmep 原始数据文件后,我们现在可以读取和处理数据。
让我们导入必要的包:
import csv import datetime as dt import io import re import zipfile from pathlib import path import numpy as np import pandas as pd from tqdm import tqdm
3.1 文件结构
在 inmet 提供的 zip 文件中,我们找到几个 csv 文件,每个气象站一个。
但是,在这些 csv 文件的第一行中,我们找到了有关气象站的信息,例如地区、联邦单位、气象站名称、wmo 代码、地理坐标(纬度和经度)、海拔以及成立日期。让我们提取此信息以用作元数据。
3.2 使用pandas读取数据
文件读取分为两部分:首先读取气象站元数据;之后,历史数据本身将被读取。
3.2.1 元数据
要提取 csv 文件前 8 行中的元数据,我们将使用 python 的内置 csv 包。
要理解以下函数,需要对文件处理程序(open)、迭代器(next)和正则表达式(re.match)的工作原理有更深入的了解。
def read_metadata(filepath: path | zipfile.zipextfile) -> dict[str, str]:
if isinstance(filepath, zipfile.zipextfile):
f = io.textiowrapper(filepath, encoding="latin-1")
else:
f = open(filepath, "r", encoding="latin-1")
reader = csv.reader(f, delimiter=";")
_, regiao = next(reader)
_, uf = next(reader)
_, estacao = next(reader)
_, codigo_wmo = next(reader)
_, latitude = next(reader)
try:
latitude = float(latitude.replace(",", "."))
except:
latitude = np.nan
_, longitude = next(reader)
try:
longitude = float(longitude.replace(",", "."))
except:
longitude = np.nan
_, altitude = next(reader)
try:
altitude = float(altitude.replace(",", "."))
except:
altitude = np.nan
_, data_fundacao = next(reader)
if re.match("[0-9]{4}-[0-9]{2}-[0-9]{2}", data_fundacao):
data_fundacao = dt.datetime.strptime(
data_fundacao,
"%y-%m-%d",
)
elif re.match("[0-9]{2}/[0-9]{2}/[0-9]{2}", data_fundacao):
data_fundacao = dt.datetime.strptime(
data_fundacao,
"%d/%m/%y",
)
f.close()
return {
"regiao": regiao,
"uf": uf,
"estacao": estacao,
"codigo_wmo": codigo_wmo,
"latitude": latitude,
"longitude": longitude,
"altitude": altitude,
"data_fundacao": data_fundacao,
}
总之,上面定义的 read_metadata 函数读取文件的前八行,处理数据并返回包含提取信息的字典。
3.2.2 历史数据
最后,我们将了解如何读取 csv 文件。其实很简单。只需使用 pandas 的 read_csv 函数和正确的参数即可。
函数调用如下所示,其中包含我为正确读取文件而确定的参数。
pd.read_csv(
"arquivo.csv",
sep=";",
decimal=",",
na_values="-9999",
encoding="latin-1",
skiprows=8,
usecols=range(19),
)
首先必须要说的是,列分隔符是分号(;),小数分隔符是逗号(,),编码是latin-1,在巴西很常见。
还需要说的是跳过文件的前8行(skiprows=8),其中包含电台元数据),只使用前19列(usecols=range(19))。
最后,我们将值 -9999 视为 null (na_values="-9999")。
3.3 数据处理
inmet-bdmep csv 文件中的列名称非常具有描述性,但有点长。并且文件之间和时间上的名称不一致。让我们重命名列以标准化名称并方便数据操作。
以下函数将用于使用正则表达式 (regex) 重命名列:
def columns_renamer(name: str) -> str:
name = name.lower()
if re.match(r"data", name):
return "data"
if re.match(r"hora", name):
return "hora"
if re.match(r"precipita[çc][ãa]o", name):
return "precipitacao"
if re.match(r"press[ãa]o atmosf[ée]rica ao n[íi]vel", name):
return "pressao_atmosferica"
if re.match(r"press[ãa]o atmosf[ée]rica m[áa]x", name):
return "pressao_atmosferica_maxima"
if re.match(r"press[ãa]o atmosf[ée]rica m[íi]n", name):
return "pressao_atmosferica_minima"
if re.match(r"radia[çc][ãa]o", name):
return "radiacao"
if re.match(r"temperatura do ar", name):
return "temperatura_ar"
if re.match(r"temperatura do ponto de orvalho", name):
return "temperatura_orvalho"
if re.match(r"temperatura m[áa]x", name):
return "temperatura_maxima"
if re.match(r"temperatura m[íi]n", name):
return "temperatura_minima"
if re.match(r"temperatura orvalho m[áa]x", name):
return "temperatura_orvalho_maxima"
if re.match(r"temperatura orvalho m[íi]n", name):
return "temperatura_orvalho_minima"
if re.match(r"umidade rel\. m[áa]x", name):
return "umidade_relativa_maxima"
if re.match(r"umidade rel\. m[íi]n", name):
return "umidade_relativa_minima"
if re.match(r"umidade relativa do ar", name):
return "umidade_relativa"
if re.match(r"vento, dire[çc][ãa]o", name):
return "vento_direcao"
if re.match(r"vento, rajada", name):
return "vento_rajada"
if re.match(r"vento, velocidade", name):
return "vento_velocidade"
现在我们已经标准化了列名,让我们处理日期/时间。 inmet-bdmep csv 文件有两个单独的日期和时间列。这很不方便,因为使用单个日期/时间列更实用。另外,日程安排也不一致,有时有分钟,有时没有。
以下三个函数将用于创建单个日期/时间列:
def convert_dates(dates: pd.series) -> pd.dataframe:
dates = dates.str.replace("/", "-")
return dates
def convert_hours(hours: pd.series) -> pd.dataframe:
def fix_hour_string(hour: str) -> str:
if re.match(r"^\d{2}\:\d{2}$", hour):
return hour
else:
return hour[:2] + ":00"
hours = hours.apply(fix_hour_string)
return hours
def fix_data_hora(d: pd.dataframe) -> pd.dataframe:
d = d.assign(
data_hora=pd.to_datetime(
convert_dates(d["data"]) + " " + convert_hours(d["hora"]),
format="%y-%m-%d %h:%m",
),
)
d = d.drop(columns=["data", "hora"])
return d
inmet-bdmep 数据存在问题,即存在空行。让我们删除这些空行以避免将来出现问题。以下代码执行此操作:
# remove empty rows
empty_columns = [
"precipitacao",
"pressao_atmosferica",
"pressao_atmosferica_maxima",
"pressao_atmosferica_minima",
"radiacao",
"temperatura_ar",
"temperatura_orvalho",
"temperatura_maxima",
"temperatura_minima",
"temperatura_orvalho_maxima",
"temperatura_orvalho_minima",
"umidade_relativa_maxima",
"umidade_relativa_minima",
"umidade_relativa",
"vento_direcao",
"vento_rajada",
"vento_velocidade",
]
empty_rows = data[empty_columns].isnull().all(axis=1)
data = data.loc[~empty_rows]
问题解决了! (•̀ᴗ•́) ̑̑
3.4 封装在函数中
为了完成本节,我们将把读取和处理代码封装在函数中。
第一个函数用于在压缩文件中读取 csv 文件。
def read_data(filepath: path) -> pd.dataframe:
d = pd.read_csv(
filepath,
sep=";",
decimal=",",
na_values="-9999",
encoding="latin-1",
skiprows=8,
usecols=range(19),
)
d = d.rename(columns=columns_renamer)
# remove empty rows
empty_columns = [
"precipitacao",
"pressao_atmosferica",
"pressao_atmosferica_maxima",
"pressao_atmosferica_minima",
"radiacao",
"temperatura_ar",
"temperatura_orvalho",
"temperatura_maxima",
"temperatura_minima",
"temperatura_orvalho_maxima",
"temperatura_orvalho_minima",
"umidade_relativa_maxima",
"umidade_relativa_minima",
"umidade_relativa",
"vento_direcao",
"vento_rajada",
"vento_velocidade",
]
empty_rows = d[empty_columns].isnull().all(axis=1)
d = d.loc[~empty_rows]
d = fix_data_hora(d)
return d
上述功能有问题。它不处理 zip 文件。
然后我们创建了 read_zipfile 函数来读取 zip 文件中包含的所有文件。此函数迭代压缩存档中的所有 csv 文件,使用 read_data 函数读取它们,并使用 read_metadata 函数读取元数据,然后将数据和元数据连接到单个 dataframe 中。
def read_zipfile(filepath: path) -> pd.dataframe:
data = pd.dataframe()
with zipfile.zipfile(filepath) as z:
files = [zf for zf in z.infolist() if not zf.is_dir()]
for zf in tqdm(files):
d = read_data(z.open(zf.filename))
meta = read_metadata(z.open(zf.filename))
d = d.assign(**meta)
data = pd.concat((data, d), ignore_index=true)
return data
最后,只需使用最后定义的函数(read_zipfile)来读取从 inmet 网站下载的 zip 文件即可。 (. ❛ ᴗ ❛.)
df = reader.read_zipfile("inmet-bdmep_2023_20240102.zip")
# 100%|████████████████████████████████████████████████████████████████████████████████| 567/567 [01:46<00:00, 5.32it/s]
df
# precipitacao pressao_atmosferica pressao_atmosferica_maxima ... longitude altitude data_fundacao
# 0 0.0 887.7 887.7 ... -47.925833 1160.96 2000-05-07
# 1 0.0 888.1 888.1 ... -47.925833 1160.96 2000-05-07
# 2 0.0 887.8 888.1 ... -47.925833 1160.96 2000-05-07
# 3 0.0 887.8 887.9 ... -47.925833 1160.96 2000-05-07
# 4 0.0 887.6 887.9 ... -47.925833 1160.96 2000-05-07
# ... ... ... ... ... ... ... ...
# 342078 0.0 902.6 903.0 ... -51.215833 963.00 2019-02-15
# 342079 0.0 902.2 902.7 ... -51.215833 963.00 2019-02-15
# 342080 0.2 902.3 902.3 ... -51.215833 963.00 2019-02-15
# 342081 0.0 903.3 903.3 ... -51.215833 963.00 2019-02-15
# 342082 0.0 903.8 903.8 ... -51.215833 963.00 2019-02-15
# [342083 rows x 26 columns]
df.to_csv("inmet-bdmep_2023.csv", index=false) # salvando o dataframe em um arquivo csv
4. 示例图表
最后,没有什么比用我们收集和处理的数据制作图表更令人满意的了。 ヾ(≧▽≦*)o
在这一部分中,我使用 r 和 tidyverse 包来制作一张结合圣保罗每小时气温和日平均值的图表。
library(tidyverse)
dados <- read_csv("inmet-bdmep_2023.csv")
print(names(dados))
# [1] "precipitacao" "pressao_atmosferica"
# [3] "pressao_atmosferica_maxima" "pressao_atmosferica_minima"
# [5] "radiacao" "temperatura_ar"
# [7] "temperatura_orvalho" "temperatura_maxima"
# [9] "temperatura_minima" "temperatura_orvalho_maxima"
# [11] "temperatura_orvalho_minima" "umidade_relativa_maxima"
# [13] "umidade_relativa_minima" "umidade_relativa"
# [15] "vento_direcao" "vento_rajada"
# [17] "vento_velocidade" "data_hora"
# [19] "regiao" "uf"
# [21] "estacao" "codigo_wmo"
# [23] "latitude" "longitude"
# [25] "altitude" "data_fundacao"
print(unique(dados$regiao))
# [1] "CO" "N" "NE" "SE" "S"
print(unique(dados$uf))
# [1] "DF" "GO" "MS" "MT" "AC" "AM" "AP" "AL" "BA" "CE" "MA" "PB" "PE" "PI" "RN"
# [16] "SE" "PA" "RO" "RR" "TO" "ES" "MG" "RJ" "SP" "PR" "RS" "SC"
dados_sp <- dados |> filter(uf == "SP")
# Temperatura horária em São Paulo
dados_sp_h <- dados_sp |>
group_by(data_hora) |>
summarise(
temperatura_ar = mean(temperatura_ar, na.rm = TRUE),
)
# Temperatura média diária em São Paulo
dados_sp_d <- dados_sp |>
group_by(data = floor_date(data_hora, "day")) |>
summarise(
temperatura_ar = mean(temperatura_ar, na.rm = TRUE),
)
# Gráfico combinando temperatura horária e média diária em São Paulo
dados_sp_h |>
ggplot(aes(x = data_hora, y = temperatura_ar)) +
geom_line(
alpha = 0.5,
aes(
color = "Temperatura horária"
)
) +
geom_line(
data = dados_sp_d,
aes(
x = data,
y = temperatura_ar,
color = "Temperatura média diária"
),
linewidth = 1
) +
labs(
x = "Data",
y = "Temperatura (°C)",
title = "Temperatura horária e média diária em São Paulo",
color = "Variável"
) +
theme_minimal() +
theme(legend.position = "top")
ggsave("temperatura_sp.png", width = 16, height = 8, dpi = 300)
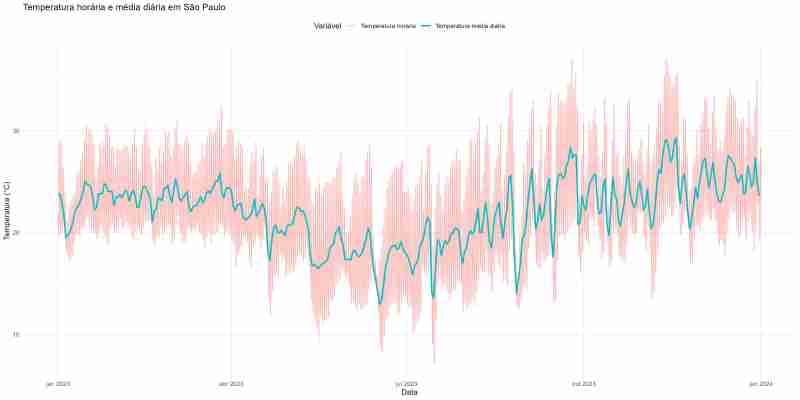
5. 结论
在本文中,我展示了如何从 inmet-bdmep 收集和处理气候数据。收集的数据对于广泛领域的研究和预测非常有用。通过处理后的数据,可以进行分析和图表,就像我在最后展示的那样。
我希望您喜欢这篇文章并且它对您有用。
我使用本文中展示的函数创建了一个 python 包。该包可在我的 git 存储库中找到。如果需要,您可以下载该软件包并在自己的代码中使用该函数。
git 存储库:https://github.com/dankkom/inmet-bdmep-data
(~ ̄▽ ̄)~
今天带大家了解了的相关知识,希望对你有所帮助;关于文章的技术知识我们会一点点深入介绍,欢迎大家关注golang学习网公众号,一起学习编程~
-
501 收藏
-
501 收藏
-
501 收藏
-
501 收藏
-
501 收藏
-
文章 · python教程 | 5小时前 | 异步编程 · 后端工程 · Python教程 · asyncio · 超时排查 · Python 超时控制 asyncio 任务取消 wait_for 异步清理320 收藏
-
321 收藏
-
365 收藏
-
文章 · python教程 | 4天前 | 默认值 · python · 数据建模 · dataclass · default_factory · field · Python 数据类 Field 可变默认值 dataclass default_factory228 收藏
-
文章 · python教程 | 4天前 | 重试机制 · timeout · requests · Python教程 · 接口调试 · Python Http请求 Requests timeout retry 接口排查330 收藏
-
299 收藏
-
308 收藏
-
209 收藏
-
329 收藏
-
437 收藏
-
299 收藏
-
241 收藏
-

- 前端进阶之JavaScript设计模式
- 设计模式是开发人员在软件开发过程中面临一般问题时的解决方案,代表了最佳的实践。本课程的主打内容包括JS常见设计模式以及具体应用场景,打造一站式知识长龙服务,适合有JS基础的同学学习。
- 立即学习 543次学习
-

- GO语言核心编程课程
- 本课程采用真实案例,全面具体可落地,从理论到实践,一步一步将GO核心编程技术、编程思想、底层实现融会贯通,使学习者贴近时代脉搏,做IT互联网时代的弄潮儿。
- 立即学习 516次学习
-

- 简单聊聊mysql8与网络通信
- 如有问题加微信:Le-studyg;在课程中,我们将首先介绍MySQL8的新特性,包括性能优化、安全增强、新数据类型等,帮助学生快速熟悉MySQL8的最新功能。接着,我们将深入解析MySQL的网络通信机制,包括协议、连接管理、数据传输等,让
- 立即学习 500次学习
-

- JavaScript正则表达式基础与实战
- 在任何一门编程语言中,正则表达式,都是一项重要的知识,它提供了高效的字符串匹配与捕获机制,可以极大的简化程序设计。
- 立即学习 487次学习
-

- 从零制作响应式网站—Grid布局
- 本系列教程将展示从零制作一个假想的网络科技公司官网,分为导航,轮播,关于我们,成功案例,服务流程,团队介绍,数据部分,公司动态,底部信息等内容区块。网站整体采用CSSGrid布局,支持响应式,有流畅过渡和展现动画。
- 立即学习 485次学习