redis中Hash字典操作的方法
来源:脚本之家
时间:2022-12-30 15:44:55 206浏览 收藏
对于一个数据库开发者来说,牢固扎实的基础是十分重要的,golang学习网就来带大家一点点的掌握基础知识点。今天本篇文章带大家了解《redis中Hash字典操作的方法》,主要介绍了字典、redisHash,希望对大家的知识积累有所帮助,快点收藏起来吧,否则需要时就找不到了!
1.Redis操作之Hash操作
redis支持五大数据类型,只支持第一层,也就说字典的value值,必须是字符串
如果value值想存字典,必须用json转换一下,转成字符串
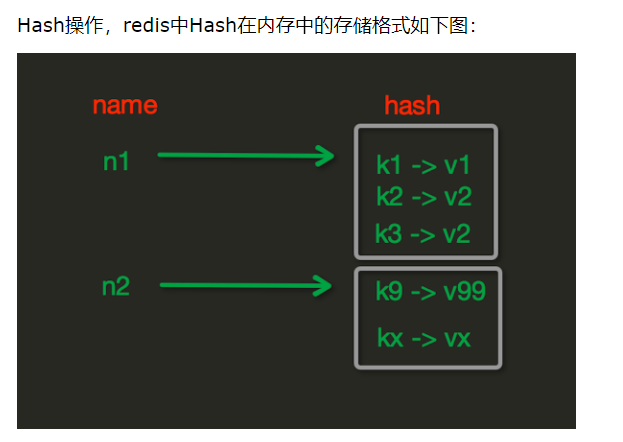
redis hash字典操作
reids:{
k1:'dafdadfasf',
m1:{
'key2':value2,
'key1':value1,
}
}
1.hset(name, key, value),插入值
# name对应的hash中设置一个键值对(不存在,则创建;否则,修改)
# 参数:
# name,redis的name
# key,name对应的hash中的key
# value,name对应的hash中的value
# 注:
# hsetnx(name, key, value),当name对应的hash中不存在当前key时则创建(相当于添加)
# 设置值# conn.hset('m1','cao','曹蕊')
2.hmset(name, mapping),批量插入值
# 在name对应的hash中批量设置键值对
# 参数:
# name,redis的name
# mapping,字典,如:{'k1':'v1', 'k2': 'v2'}
# 如:
# r.hmset('xx', {'k1':'v1', 'k2': 'v2'})
# 批量插入设置值# conn.hmset('m2', {'cao': 100, 'bai': 101})
3.hget(name,key),取值
# 在name对应的hash中获取根据key获取value
# 取值,根据大字典的key,再去查key
print(conn.hget('m2','cao'))
4.hmget(name, keys, *args) 批量取值
# 在name对应的hash中获取多个key的值
# 参数:
# name,reids对应的name
# keys,要获取key集合,如:['k1', 'k2', 'k3']
# *args,要获取的key,如:k1,k2,k3
# 如:
# r.mget('xx', ['k1', 'k2'])
# 或
# print r.hmget('xx', 'k1', 'k2')
print(conn.hmget('m2','cao','bai'))print(conn.hmget('m2',['cao','bai']))
hlen(name)
# 获取name对应的hash中键值对的个数
# print(conn.hlen('m2'))
hkeys(name)
# 获取name对应的hash中所有的key的值
# print(conn.hkeys('m2'))
hvals(name)
# 获取name对应的hash中所有的value的值
# print(conn.hvals('m2'))
hexists(name, key)
# 检查name对应的hash是否存在当前传入的key
# print(conn.hexists('m2','cao'))
hdel(name,*keys)
# 将name对应的hash中指定key的键值对删除
print(re.hdel('xxx','sex','name'))
# conn.hdel('m2','key1','key2')
# 这样可以# conn.hdel('m2',*['key1','key2'])# 这样不行# conn.hdel('m2',['key1','key2'])
hincrby用来统计一个东西的数量的频繁增加(name, key, amount=1)
hincrby应用场景:
统计文章阅读数:key是文章id,value是文章阅读数,有一个阅读者,数字加一,固定一个时间,将数据同步到数据库,一定要写日志,避免出错,还能查找到
# 自增name对应的hash中的指定key的值,不存在则创建key=amount
# 参数:
# name,redis中的name
# key, hash对应的key
# amount,自增数(整数)
conn.hincrby('m1','key3')
hincrbyfloat(name, key, amount=1.0)
# 自增name对应的hash中的指定key的值,不存在则创建key=amount
# 参数:
# name,redis中的name
# key, hash对应的key
# amount,自增数(浮点数)
# 自增name对应的hash中的指定key的值,不存在则创建key=amount
hgetall(name)——慎用,一次性取出数据前需要先hlen看下长度
# 获取name对应hash的所有键值
print(re.hgetall('xxx').get(b'name'))
# 根据key把所有的值取出来
# print(conn.hgetall('m2'))
hscan_iter(name, match=None, count=None),增量迭代取值
# 利用yield封装hscan创建生成器,实现分批去redis中获取数据
# 参数:
# match,匹配指定key,默认None 表示所有的key
# count,每次分片最少获取个数,默认None表示采用Redis的默认分片个数
# 如:
# for item in r.hscan_iter('xx'):
# print item
应用场景:
比如我redis中字典有10000w条数据,全部都打印出来
hscan——指定游标,然后取多少值
for i in range(1000):
conn.hset('m2','key%s'%i,'value%s'%i)
指定每次取10条,直到取完
ret=conn.hscan_iter('m2',count=100)
不要用这种方式,一下全部取出,redis可能会被撑爆,或者先用len查看下长度再决定使用getall或者其他
ret=conn.hgetall('m2')
hscan(name, cursor=0, match=None, count=None)——指定游标,然后取多少数据
# 增量式迭代获取,对于数据大的数据非常有用,hscan可以实现分片的获取数据,并非一次性将数据全部获取完,从而防止内存被撑爆
# 参数:
# name,redis的name
# cursor,游标(基于游标分批取获取数据)
# match,匹配指定key,默认None 表示所有的key
# count,每次分片最少获取个数,默认None表示采用Redis的默认分片个数
# 如:
# 第一次:cursor1, data1 = r.hscan('xx', cursor=0, match=None, count=None)
# 第二次:cursor2, data1 = r.hscan('xx', cursor=cursor1, match=None, count=None)
# ...
# 直到返回值cursor的值为0时,表示数据已经通过分片获取完毕
以上就是本文的全部内容了,是否有顺利帮助你解决问题?若是能给你带来学习上的帮助,请大家多多支持golang学习网!更多关于数据库的相关知识,也可关注golang学习网公众号。
-
303 收藏
-
170 收藏
-
318 收藏
-
137 收藏
-
450 收藏
-
数据库 · Redis | 9小时前 | Redis · go · Pipeline · 批处理 · 重试 · 幂等性 · 重试 go-redis 幂等键 批量写入 Redis Pipeline 逐条结果391 收藏
-
154 收藏
-
386 收藏
-
127 收藏
-
422 收藏
-
326 收藏
-
494 收藏
-
数据库 · Redis | 3天前 | Redis · 缓存 · 限流 · Redis 8.8 · INCREX · Redis 8.8 INCREX Redis窗口限流 Redis计数器 ENX UBOUND123 收藏
-
数据库 · Redis | 5天前 | Redis · 缓存 · go · Redis Cluster · 排错 · Redis Cluster CROSSSLOT Hash Tag MGET CLUSTER KEYSLOT259 收藏
-
183 收藏
-
413 收藏
-
数据库 · Redis | 1星期前 | Redis · 安全配置 · 数据库运维 · ACL · 网络隔离 · Redis公网暴露 Redis protected-mode Redis ACL Redis安全配置 Redis审计364 收藏
-

- 前端进阶之JavaScript设计模式
- 设计模式是开发人员在软件开发过程中面临一般问题时的解决方案,代表了最佳的实践。本课程的主打内容包括JS常见设计模式以及具体应用场景,打造一站式知识长龙服务,适合有JS基础的同学学习。
- 立即学习 543次学习
-

- GO语言核心编程课程
- 本课程采用真实案例,全面具体可落地,从理论到实践,一步一步将GO核心编程技术、编程思想、底层实现融会贯通,使学习者贴近时代脉搏,做IT互联网时代的弄潮儿。
- 立即学习 516次学习
-

- 简单聊聊mysql8与网络通信
- 如有问题加微信:Le-studyg;在课程中,我们将首先介绍MySQL8的新特性,包括性能优化、安全增强、新数据类型等,帮助学生快速熟悉MySQL8的最新功能。接着,我们将深入解析MySQL的网络通信机制,包括协议、连接管理、数据传输等,让
- 立即学习 500次学习
-

- JavaScript正则表达式基础与实战
- 在任何一门编程语言中,正则表达式,都是一项重要的知识,它提供了高效的字符串匹配与捕获机制,可以极大的简化程序设计。
- 立即学习 487次学习
-

- 从零制作响应式网站—Grid布局
- 本系列教程将展示从零制作一个假想的网络科技公司官网,分为导航,轮播,关于我们,成功案例,服务流程,团队介绍,数据部分,公司动态,底部信息等内容区块。网站整体采用CSSGrid布局,支持响应式,有流畅过渡和展现动画。
- 立即学习 485次学习
-

- 还单身的机器猫
- 这篇技术贴真及时,太细致了,写的不错,已收藏,关注博主了!希望博主能多写数据库相关的文章。
- 2023-01-05 20:18:48
-
- 彩色的花生
- 太详细了,收藏了,感谢师傅的这篇文章,我会继续支持!
- 2023-01-04 04:51:37
-
- 光亮的小馒头
- 真优秀,一直没懂这个问题,但其实工作中常常有遇到...不过今天到这,看完之后很有帮助,总算是懂了,感谢大佬分享技术贴!
- 2023-01-02 19:56:39