只需几步即可将拥抱脸部模型部署到 AWS Lambda
来源:dev.to
时间:2024-12-02 22:22:05 465浏览 收藏
大家好,我们又见面了啊~本文《只需几步即可将拥抱脸部模型部署到 AWS Lambda》的内容中将会涉及到等等。如果你正在学习文章相关知识,欢迎关注我,以后会给大家带来更多文章相关文章,希望我们能一起进步!下面就开始本文的正式内容~
是否曾经想将 hugging face 模型部署到 aws lambda,但却被容器构建、冷启动和模型缓存所困扰?以下是如何使用 scaffoldly 在 5 分钟内完成此操作。
长话短说
-
在 aws 中创建名为 .cache 的 efs 文件系统:
- 转到 aws efs 控制台
- 点击“创建文件系统”
- 将其命名为.cache
- 选择任意 vpc(scaffoldly 会处理剩下的事情!)
-
从 python-huggingface 分支创建您的应用程序:
npx scaffoldly create app --template python-huggingface
-
部署它:
cd my-app && npx scaffoldly deploy
就是这样!您将获得在 lambda 上运行的 hugging face 模型(以 openai-community/gpt2 为例),并配有适当的缓存和容器部署。
专业提示:对于 efs 设置,您可以将其自定义为突发模式下的单个 az,以进一步节省成本。 scaffoldly 会将 lambda 函数与 efs 的 vpc、子网和安全组进行匹配。
✨ 查看现场演示和示例代码!
问题
将机器学习模型部署到 aws lambda 传统上涉及:
- 构建和管理 docker 容器
- 弄清楚模型缓存和存储
- 处理 lambda 的大小限制
- 管理冷启动
- 设置 api 端点
当您只想为模型提供服务时,需要进行大量基础设施工作!
解决方案
scaffoldly 通过一个简单的配置文件来处理所有这些复杂性。这是一个提供 hugging face 模型的完整应用程序(以 openai-community/gpt2 为例):
# app.py
from flask import flask
from transformers import pipeline
app = flask(__name__)
generator = pipeline('text-generation', model='openai-community/gpt2')
@app.route("/")
def hello_world():
output = generator("hello, world,")
return output[0]['generated_text']
// requirements.txt flask ~= 3.0 gunicorn ~= 23.0 torch ~= 2.5 numpy ~= 2.1 transformers ~= 4.46 huggingface_hub[cli] ~= 0.26
// scaffoldly.json
{
"name": "python-huggingface",
"runtime": "python:3.12",
"handler": "localhost:8000",
"files": ["app.py"],
"packages": ["pip:requirements.txt"],
"resources": ["arn::elasticfilesystem:::file-system/.cache"],
"schedules": {
"@immediately": "huggingface-cli download openai-community/gpt2"
},
"scripts": {
"start": "gunicorn app:app"
},
"memorysize": 1024
}
它是如何运作的
scaffoldly 在幕后做了一些聪明的事情:
-
智能集装箱建筑:
- 自动创建针对 lambda 优化的 docker 容器
- 处理所有 python 依赖项,包括 pytorch
- 无需编写任何 docker 命令即可推送到 ecr
-
高效的模型处理:
- 使用 amazon efs 缓存模型文件
- 部署后预下载模型以加快冷启动
- 在 lambda 中自动挂载缓存
-
lambda 就绪设置:
- rus 建立一个合适的 wsgi 服务器(gunicorn)
- 创建公共 lambda 函数 url
- 代理函数url请求gunicorn
- 管理 iam 角色和权限
部署是什么样的
这是我在此示例中运行的 npx 脚手架部署命令的输出:
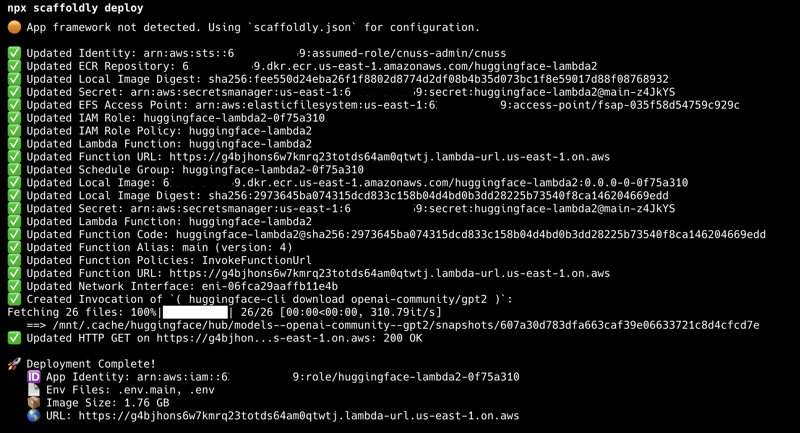
现实世界的性能和成本
✅ 成本:aws lambda、ecr 和 efs 约 0.20 美元/天
✅ 冷启动:第一次请求约 20 秒(模型加载)
✅ 热烈请求:5-20秒(基于cpu的推理)
虽然此设置使用 cpu 推理(比 gpu 慢),但这是一种试验 ml 模型或服务低流量端点的极其经济高效的方法。
其他型号定制
想要使用不同的模型吗?只需更新两个文件:
- 更改app.py中的模型:
generator = pipeline('text-generation', model='your-model-here')
- 更新scaffoldly.json中的下载:
"schedules": {
"@immediately": "huggingface-cli download your-model-here"
}
使用私有或门控模型
scaffoldly 通过 hf_token 环境变量支持私有和门控模型。您可以通过多种方式添加 hugging face 令牌:
- 本地开发:添加到您的 shell 配置文件(.bashrc、.zprofile 等):
export hf_token="hf_rh...a"
- ci/cd:添加为 github actions secret:
# in your repository settings -> secrets and variables -> actions hf_token: hf_rh...a
令牌将自动用于下载和访问您的私人或门控模型。
ci/cd 奖金
scaffoldly 甚至生成用于自动部署的 github action:
name: scaffoldly deploy
jobs:
deploy:
runs-on: ubuntu-latest
steps:
- uses: actions/checkout@v4
- uses: scaffoldly/scaffoldly@v1
with:
secrets: ${{ tojson(secrets) }}
自己尝试一下
完整的示例可以在 github 上找到:
脚手架/脚手架示例#python-huggingface
您可以通过运行以下命令创建您自己的示例副本:
npx scaffoldly create app --template python-huggingface
您可以看到它正在实时运行(尽管由于 cpu 推断,响应可能会很慢):
现场演示
接下来是什么?
- 尝试部署不同的拥抱脸模型
- 加入 discord 上的 scaffoldly 社区
- 查看其他示例
- 如果您觉得这有用,请给我们的代码库加星标!
- 脚手架工具链
- scaffoldly 示例存储库
许可证
scaffoldly 是开源的,欢迎社区贡献。
- 这些示例已获得 apache-2.0 许可证的许可。
- 脚手架工具链已获得 fsl-1.1-apache-2.0 许可证。
您还想在 aws lambda 中运行哪些其他模型?请在评论中告诉我!
以上就是本文的全部内容了,是否有顺利帮助你解决问题?若是能给你带来学习上的帮助,请大家多多支持golang学习网!更多关于文章的相关知识,也可关注golang学习网公众号。
-
501 收藏
-
501 收藏
-
501 收藏
-
501 收藏
-
501 收藏
-
196 收藏
-
文章 · python教程 | 1天前 | logging · Python教程 · 后端开发 · 日志排查 · Python logging 日志重复 propagate addHandler basicConfig324 收藏
-
435 收藏
-
478 收藏
-
文章 · python教程 | 1星期前 | 异步编程 · 后端工程 · Python教程 · asyncio · 超时排查 · Python 超时控制 asyncio 任务取消 wait_for 异步清理320 收藏
-
321 收藏
-
365 收藏
-
文章 · python教程 | 1星期前 | 默认值 · python · 数据建模 · dataclass · default_factory · field · Python 数据类 Field 可变默认值 dataclass default_factory228 收藏
-
文章 · python教程 | 1星期前 | 重试机制 · timeout · requests · Python教程 · 接口调试 · Python Http请求 Requests timeout retry 接口排查330 收藏
-
299 收藏
-
308 收藏
-
209 收藏
-

- 前端进阶之JavaScript设计模式
- 设计模式是开发人员在软件开发过程中面临一般问题时的解决方案,代表了最佳的实践。本课程的主打内容包括JS常见设计模式以及具体应用场景,打造一站式知识长龙服务,适合有JS基础的同学学习。
- 立即学习 543次学习
-

- GO语言核心编程课程
- 本课程采用真实案例,全面具体可落地,从理论到实践,一步一步将GO核心编程技术、编程思想、底层实现融会贯通,使学习者贴近时代脉搏,做IT互联网时代的弄潮儿。
- 立即学习 516次学习
-

- 简单聊聊mysql8与网络通信
- 如有问题加微信:Le-studyg;在课程中,我们将首先介绍MySQL8的新特性,包括性能优化、安全增强、新数据类型等,帮助学生快速熟悉MySQL8的最新功能。接着,我们将深入解析MySQL的网络通信机制,包括协议、连接管理、数据传输等,让
- 立即学习 500次学习
-

- JavaScript正则表达式基础与实战
- 在任何一门编程语言中,正则表达式,都是一项重要的知识,它提供了高效的字符串匹配与捕获机制,可以极大的简化程序设计。
- 立即学习 487次学习
-

- 从零制作响应式网站—Grid布局
- 本系列教程将展示从零制作一个假想的网络科技公司官网,分为导航,轮播,关于我们,成功案例,服务流程,团队介绍,数据部分,公司动态,底部信息等内容区块。网站整体采用CSSGrid布局,支持响应式,有流畅过渡和展现动画。
- 立即学习 485次学习