如何解析计算机代码,代码的出现 ay 3
时间:2025-01-08 19:42:34 413浏览 收藏
本篇文章主要是结合我之前面试的各种经历和实战开发中遇到的问题解决经验整理的,希望这篇《如何解析计算机代码,代码的出现 ay 3》对你有很大帮助!欢迎收藏,分享给更多的需要的朋友学习~
探秘Advent of Code第三天的解析挑战:优雅地处理杂乱输入
最近重温Advent of Code第三天的挑战,它巧妙地提出了一个有趣的解析问题:从杂乱的输入中提取有效代码。这对于解析器和词法分析器开发来说是一次绝佳的练习。让我们一起探索解决这个问题的策略。

起初,我依赖hy进行解析。但最近对生成式AI的探索让我转向了funcparserlib库。这次挑战让我深入了解了funcparserlib的强大功能。
词法分析(分词)
处理杂乱输入的第一步是词法分析(或标记化)。词法分析器(或分词器)扫描输入字符串,将其分解成独立的标记——进一步处理的基本单元。标记代表输入中有意义的单元,并按类型分类。本题中,我们关注以下标记类型:
- 运算符 (op): 例如
mul、do、don't。 - 数字: 数值,例如
2、3。 - 逗号:
,,参数分隔符。 - 括号:
(和),定义函数调用结构。 - 乱码: 与其他类型不匹配的字符或字符序列。
我摒弃了funcparserlib教程中常见的“魔术字符串”方法,转而采用更结构化的枚举定义:
from enum import Enum, auto
class TokenSpec(Enum):
OP = auto()
NUMBER = auto()
COMMA = auto()
LPAREN = auto()
RPAREN = auto()
GIBBERISH = auto()
使用TokenSpec.OP、TokenSpec.NUMBER等,提高了代码可读性、可维护性和类型安全性。
为了与funcparserlib集成,我创建了一个名为tokenspec_的装饰器,它包装了funcparserlib的tokenspec函数,简化了标记定义:
from funcparserlib.lexer import tokenspec
def tokenspec_(spec: TokenSpec, *args, **kwargs):
return tokenspec(spec.name, *args, **kwargs)
利用tokenspec_,我们可以定义分词器:
from funcparserlib.lexer import make_tokenizer
def tokenize(input_str: str):
tokenizer = make_tokenizer([
tokenspec_(TokenSpec.OP, r"mul(?=\(\d{1,3},\d{1,3}\))|do(?=\(\))|don\'t(?=\(\))"),
tokenspec_(TokenSpec.NUMBER, r"\d{1,3}"),
tokenspec_(TokenSpec.LPAREN, r"\("),
tokenspec_(TokenSpec.RPAREN, r"\)"),
tokenspec_(TokenSpec.COMMA, r","),
tokenspec_(TokenSpec.GIBBERISH, r".") #匹配任何字符
])
return tuple(token for token in tokenizer(input_str) if token.type != TokenSpec.GIBBERISH.name)
mul的正则表达式使用前瞻断言确保正确的语法。
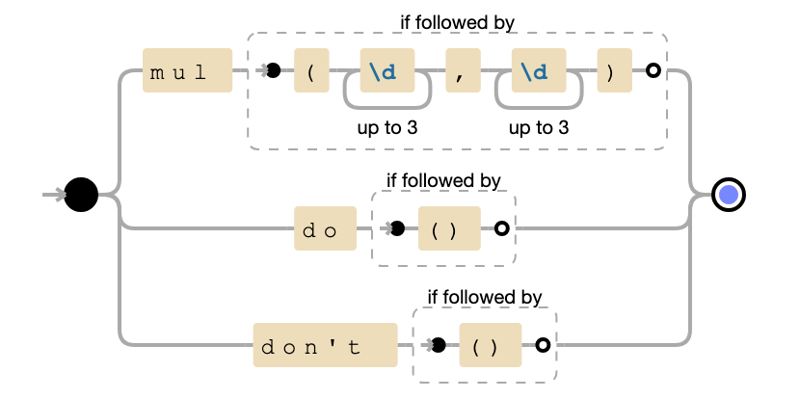
tokenize函数过滤掉乱码标记。
解析器实现
tokenize返回的标记序列将被送入解析器。为了简化解析器定义,我创建了tok_装饰器:
from funcparserlib.parser import tok
def tok_(spec: TokenSpec, *args, **kwargs):
return tok(spec.name, *args, **kwargs)
数字解析器:
number = tok_(TokenSpec.NUMBER) >> int
解析规则:
from dataclasses import dataclass
from abc import ABC, abstractmethod
class Expr(ABC):
@abstractmethod
def evaluate(self) -> int:
pass
@dataclass
class Mul(Expr):
alpha: int
beta: int
def evaluate(self) -> int:
return self.alpha * self.beta
@dataclass
class Condition(Expr):
can_proceed: bool
def evaluate(self) -> int:
return 0 #条件表达式不参与计算
mul = (tok_(TokenSpec.OP, "mul") + tok_(TokenSpec.LPAREN) + number + tok_(TokenSpec.COMMA) + number + tok_(TokenSpec.RPAREN)) >> (lambda t: Mul(t[2], t[4]))
do = (tok_(TokenSpec.OP, "do") + tok_(TokenSpec.LPAREN) + tok_(TokenSpec.RPAREN)) >> (lambda _: Condition(True))
dont = (tok_(TokenSpec.OP, "don't") + tok_(TokenSpec.LPAREN) + tok_(TokenSpec.RPAREN)) >> (lambda _: Condition(False))
expr = mul | do | dont
from funcparserlib.parser import finished, many
import operator
call = many(tok_(TokenSpec.NUMBER) | tok_(TokenSpec.LPAREN) | tok_(TokenSpec.RPAREN) | tok_(TokenSpec.COMMA)) + expr + many(tok_(TokenSpec.NUMBER) | tok_(TokenSpec.LPAREN) | tok_(TokenSpec.RPAREN) | tok_(TokenSpec.COMMA)) >> operator.itemgetter(1)
program = many(call) + finished >> (lambda t: tuple(t[0]))
def parse(tokens):
return program.parse(tokens)
难题求解
第一部分:
def part1(input_str: str) -> int:
expressions = parse(tokenize(input_str.strip()))
return sum(expr.evaluate() for expr in expressions if isinstance(expr, Mul))
第二部分:
def part2(input_str: str) -> int:
expressions = parse(tokenize(input_str.strip()))
can_proceed = True
total = 0
for expr in expressions:
if isinstance(expr, Condition):
can_proceed = expr.can_proceed
elif isinstance(expr, Mul):
if can_proceed:
total += expr.evaluate()
return total
迭代改进
最初,我的方法涉及两次解析。现在,单次解析就完成了所有任务,提高了效率。
这次Advent of Code之旅让我巩固了词法分析和解析的知识。期待未来更复杂的挑战!
今天关于《如何解析计算机代码,代码的出现 ay 3》的内容就介绍到这里了,是不是学起来一目了然!想要了解更多关于的内容请关注golang学习网公众号!
-
501 收藏
-
501 收藏
-
501 收藏
-
501 收藏
-
501 收藏
-
196 收藏
-
文章 · python教程 | 7小时前 | logging · Python教程 · 后端开发 · 日志排查 · Python logging 日志重复 propagate addHandler basicConfig324 收藏
-
435 收藏
-
478 收藏
-
文章 · python教程 | 1星期前 | 异步编程 · 后端工程 · Python教程 · asyncio · 超时排查 · Python 超时控制 asyncio 任务取消 wait_for 异步清理320 收藏
-
321 收藏
-
365 收藏
-
文章 · python教程 | 1星期前 | 默认值 · python · 数据建模 · dataclass · default_factory · field · Python 数据类 Field 可变默认值 dataclass default_factory228 收藏
-
文章 · python教程 | 1星期前 | 重试机制 · timeout · requests · Python教程 · 接口调试 · Python Http请求 Requests timeout retry 接口排查330 收藏
-
299 收藏
-
308 收藏
-
209 收藏
-

- 前端进阶之JavaScript设计模式
- 设计模式是开发人员在软件开发过程中面临一般问题时的解决方案,代表了最佳的实践。本课程的主打内容包括JS常见设计模式以及具体应用场景,打造一站式知识长龙服务,适合有JS基础的同学学习。
- 立即学习 543次学习
-

- GO语言核心编程课程
- 本课程采用真实案例,全面具体可落地,从理论到实践,一步一步将GO核心编程技术、编程思想、底层实现融会贯通,使学习者贴近时代脉搏,做IT互联网时代的弄潮儿。
- 立即学习 516次学习
-

- 简单聊聊mysql8与网络通信
- 如有问题加微信:Le-studyg;在课程中,我们将首先介绍MySQL8的新特性,包括性能优化、安全增强、新数据类型等,帮助学生快速熟悉MySQL8的最新功能。接着,我们将深入解析MySQL的网络通信机制,包括协议、连接管理、数据传输等,让
- 立即学习 500次学习
-

- JavaScript正则表达式基础与实战
- 在任何一门编程语言中,正则表达式,都是一项重要的知识,它提供了高效的字符串匹配与捕获机制,可以极大的简化程序设计。
- 立即学习 487次学习
-

- 从零制作响应式网站—Grid布局
- 本系列教程将展示从零制作一个假想的网络科技公司官网,分为导航,轮播,关于我们,成功案例,服务流程,团队介绍,数据部分,公司动态,底部信息等内容区块。网站整体采用CSSGrid布局,支持响应式,有流畅过渡和展现动画。
- 立即学习 485次学习