Python 中 set 是什么?为何要是用它?
时间:2025-01-26 17:09:50 465浏览 收藏
文章不知道大家是否熟悉?今天我将给大家介绍《Python 中 set 是什么?为何要是用它?》,这篇文章主要会讲到等等知识点,如果你在看完本篇文章后,有更好的建议或者发现哪里有问题,希望大家都能积极评论指出,谢谢!希望我们能一起加油进步!
Python 提供多种内置数据结构用于组织数据,包括列表、字典、元组和集合。
根据 Python 3 文档,集合是无序的、不包含重复元素的集合。其主要用途包括成员测试和去除重复项。集合还支持集合运算,如并集、交集、差集和对称差集。
本文将通过示例阐述以上定义中的每个特性,并讲解集合的创建方法。
使用 set() 函数初始化集合:
>>> s1 = set([1, 2, 3])
>>> s1
{1, 2, 3}
>>> type(s1)
使用 {} 初始化集合:
>>> s2 = {3, 4, 5}
>>> s2
{3, 4, 5}
>>> type(s2)
两种方法均有效。但如果需要创建空集合呢?
>>> s = {}
>>> type(s)
使用空花括号将创建一个字典,而非集合。
为简便起见,本文示例使用整数集合,但集合可包含所有 Python 支持的可哈希[1]数据类型,例如整数、字符串和元组,但不包括列表或字典等可变类型。
>>> s = {1, 'coffee', [4, 'python']}
Traceback (most recent call last):
File "", line 1, in
TypeError: unhashable type: 'list'
了解了集合的创建方法及其可包含的元素类型后,我们来探讨一下为什么应该将集合纳入你的编程工具箱。
根据 Python Hitchhiker's Guide[3]:
当经验丰富的 Python 开发者(Pythonista)遇到不够“Pythonic”的代码时,通常认为这些代码不符合通用指南,表达意图的方式不够理想(可读性差)。
让我们看看集合如何提升代码可读性并提高程序执行效率。
>>> s = {1, 2, 3}
>>> s[0]
Traceback (most recent call last):
File "", line 1, in
TypeError: 'set' object does not support indexing
也无法使用切片修改:
>>> s[0:2] Traceback (most recent call last): File "", line 1, in TypeError: 'set' object is not subscriptable
但如果需要去除重复项或进行集合运算(如并集),则应该使用集合。
迭代时,集合的效率优于列表。原因涉及集合的内部实现细节,感兴趣的读者可以参考以下链接:
- 时间复杂度[4]
set()的实现[5]- Python 集合 vs 列表[6]
- 列表中使用集合的优缺点[7]
>>> my_list = [1, 2, 3, 2, 3, 4] >>> no_duplicate_list = [] >>> for item in my_list: ... if item not in no_duplicate_list: ... no_duplicate_list.append(item) ... >>> no_duplicate_list [1, 2, 3, 4]
或者使用列表推导式:
>>> my_list = [1, 2, 3, 2, 3, 4] >>> no_duplicate_list = [] >>> [no_duplicate_list.append(item) for item in my_list if item not in no_duplicate_list] [None, None, None, None] >>> no_duplicate_list [1, 2, 3, 4]
现在,我们可以使用集合:
>>> my_list = [1, 2, 3, 2, 3, 4] >>> no_duplicate_list = list(set(my_list)) >>> no_duplicate_list [1, 2, 3, 4]
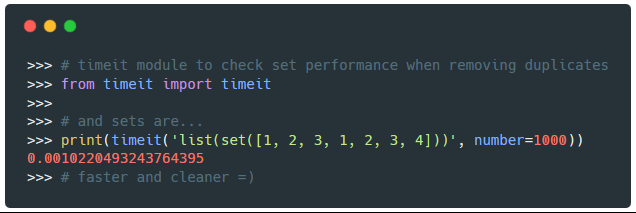
使用 timeit 模块比较列表和集合去除重复项的效率:
>>> from timeit import timeit
>>> def no_duplicates(list):
... no_duplicate_list = []
... [no_duplicate_list.append(item) for item in list if item not in no_duplicate_list]
... return no_duplicate_list
...
>>> # 列表的执行时间:
>>> print(timeit('no_duplicates([1, 2, 3, 1, 7])', globals=globals(), number=1000))
0.0018683355819786227
>>> from timeit import timeit
>>> # 集合的执行时间:
>>> print(timeit('list(set([1, 2, 3, 1, 2, 3, 4]))', number=1000))
0.0010220493243764395
>>> # 更快更简洁
使用集合比列表推导式更简洁,效率更高。
注意:集合是无序的,转换为列表后元素顺序可能发生变化。
Python 之禅[8]:
优美胜于丑陋
明了胜于晦涩
简洁胜于复杂
扁平胜于嵌套
集合正是如此。
my_list = [1, 2, 3]
>>> if 2 in my_list:
... print('Yes, this is a membership test!')
...
Yes, this is a membership test!
集合的成员测试效率更高:
>>> from timeit import timeit
>>> def in_test(iterable):
... for i in range(1000):
... if i in iterable:
... pass
...
>>> timeit('in_test(iterable)',
... setup="from __main__ import in_test; iterable = list(range(1000))",
... number=1000)
12.459663048726043
>>> from timeit import timeit
>>> def in_test(iterable):
... for i in range(1000):
... if i in iterable:
... pass
...
>>> timeit('in_test(iterable)',
... setup="from __main__ import in_test; iterable = set(range(1000))",
... number=1000)
.12354438152988223
注意:以上测试来自 StackOverflow[9]。
对于大型列表,将其转换为集合可以提高成员测试效率。
add() 用于添加单个元素:
>>> s = {1, 2, 3}
>>> s.add(4)
>>> s
{1, 2, 3, 4}
update() 用于添加多个元素:
>>> s = {1, 2, 3}
>>> s.update([2, 3, 4, 5, 6])
>>> s
{1, 2, 3, 4, 5, 6}
集合会自动去除重复元素。
>>> s = {1, 2, 3}
>>> s.remove(3)
>>> s
{1, 2}
>>> s.remove(3)
Traceback (most recent call last):
File "", line 1, in
KeyError: 3
discard() 不会引发异常:
>>> s = {1, 2, 3}
>>> s.discard(3)
>>> s
{1, 2}
>>> s.discard(3)
>>> # 无任何操作
pop() 用于随机移除一个元素:
>>> s = {1, 2, 3, 4, 5}
>>> s.pop() # 移除一个任意元素
1
>>> s
{2, 3, 4, 5}
clear() 用于清空集合:
>>> s = {1, 2, 3, 4, 5}
>>> s.clear() # 清空集合
>>> s
set()
>>> s1 = {1, 2, 3}
>>> s2 = {3, 4, 5}
>>> s1.union(s2) # 或 's1 | s2'
{1, 2, 3, 4, 5}
>>> s1 = {1, 2, 3}
>>> s2 = {2, 3, 4}
>>> s3 = {3, 4, 5}
>>> s1.intersection(s2, s3) # 或 's1 & s2 & s3'
{3}
>>> s1 = {1, 2, 3}
>>> s2 = {2, 3, 4}
>>> s1.difference(s2) # 或 's1 - s2'
{1}
>>> s1 = {1, 2, 3}
>>> s2 = {2, 3, 4}
>>> s1.symmetric_difference(s2) # 或 's1 ^ s2'
{1, 4}
如有任何疑问,请随时提出。此外,Python 速查表[10]中也包含了集合的相关内容[11],方便查阅。
以上就是本文的全部内容了,是否有顺利帮助你解决问题?若是能给你带来学习上的帮助,请大家多多支持golang学习网!更多关于文章的相关知识,也可关注golang学习网公众号。
-
501 收藏
-
501 收藏
-
501 收藏
-
501 收藏
-
501 收藏
-
186 收藏
-
文章 · linux | 3天前 | Linux · 服务治理 · 日志排查 · 运维教程 · Linux 服务管理器 journalctl 服务重启 运维排查 RestartSec start-limit-hit408 收藏
-
399 收藏
-
120 收藏
-
文章 · linux | 2星期前 | Linux · inode · 日志清理 · 磁盘排查 · 服务器运维 · Linux inode 磁盘空间 df du lsof No space left on device335 收藏
-
422 收藏
-
文章 · linux | 2星期前 | 服务器 · Linux · ssh · 运维排查 · 登录慢 · Linux SSH pam sshd_config 登录慢 UseDNS GSSAPI 密钥权限153 收藏
-
文章 · linux | 2星期前 | Linux · 运维排查 · 文件句柄 · ulimit · 服务限制 · Linux 文件句柄 lsof ulimit too many open files LimitNOFILE 服务限制482 收藏
-
文章 · linux | 2星期前 | Linux · 运维 · 性能排查 · 磁盘IO · iostat · pidstat · Linux 性能排查 iostat 磁盘IO pidstat %util260 收藏
-
335 收藏
-
284 收藏
-
286 收藏
-

- 前端进阶之JavaScript设计模式
- 设计模式是开发人员在软件开发过程中面临一般问题时的解决方案,代表了最佳的实践。本课程的主打内容包括JS常见设计模式以及具体应用场景,打造一站式知识长龙服务,适合有JS基础的同学学习。
- 立即学习 543次学习
-

- GO语言核心编程课程
- 本课程采用真实案例,全面具体可落地,从理论到实践,一步一步将GO核心编程技术、编程思想、底层实现融会贯通,使学习者贴近时代脉搏,做IT互联网时代的弄潮儿。
- 立即学习 516次学习
-

- 简单聊聊mysql8与网络通信
- 如有问题加微信:Le-studyg;在课程中,我们将首先介绍MySQL8的新特性,包括性能优化、安全增强、新数据类型等,帮助学生快速熟悉MySQL8的最新功能。接着,我们将深入解析MySQL的网络通信机制,包括协议、连接管理、数据传输等,让
- 立即学习 500次学习
-

- JavaScript正则表达式基础与实战
- 在任何一门编程语言中,正则表达式,都是一项重要的知识,它提供了高效的字符串匹配与捕获机制,可以极大的简化程序设计。
- 立即学习 487次学习
-

- 从零制作响应式网站—Grid布局
- 本系列教程将展示从零制作一个假想的网络科技公司官网,分为导航,轮播,关于我们,成功案例,服务流程,团队介绍,数据部分,公司动态,底部信息等内容区块。网站整体采用CSSGrid布局,支持响应式,有流畅过渡和展现动画。
- 立即学习 485次学习