【Linux进程通信】二、深度解析匿名管道
时间:2025-04-20 17:13:56 491浏览 收藏
本文详细介绍了Linux进程间通信中的匿名管道。首先阐述了管道的概念,即基于文件系统、单向连接的数据流,其本质是内核缓冲区,并非磁盘文件,从而保证高效的数据传输。随后,文章深入探讨了匿名管道的原理和创建方法,重点讲解了利用`pipe()`系统调用创建匿名管道,以及父子进程通过继承文件描述符实现共享同一缓冲区的方法,并强调了关闭相应读写端以确保单向通信的必要性。最后,文章简述了匿名管道的读写特征,为读者理解Linux进程间通信提供了清晰的思路。
Ⅰ. 管道一、管道的概念 管道是 Unix 中最古老的进程间基于文件系统通信的形式。我们把从一个进程连接到另一个进程的一个数据流称为一个 “管道”。注意管道是单向连通的,不存在说双向管道,就像生活中水往低处流而不会往高处流一样!
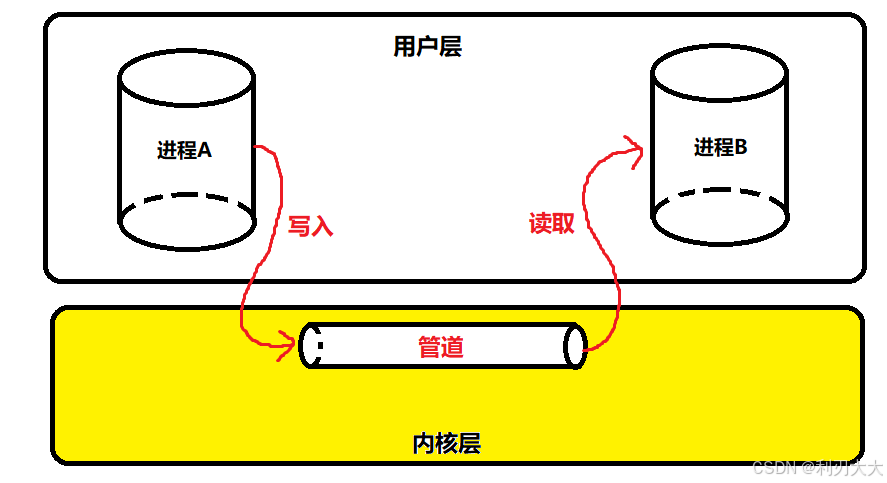
进程 A 通过管道将数据写入到 “公共内存” 中,并且进程 B 可以从该段 “公共内存” 中读取这些数据,这样子的话就达到了两个进程之间的交互!
那么有人可能会有问题:既然这段 “公共内存” 是共享的并且都是基于文件系统的,那这个管道文件是不是在磁盘上面呢,然后进程A通过写入到磁盘中的管道文件,进程B再去读取这样子的方式 ❓❓❓
其实不是的,因为我们都知道,文件 IO 的效率是相当的低的,所以操作系统肯定不笨,操作系统会将这个管道文件 load 到内存中,也就是内存级别的文件,而我们两个进程之间只需要和这个内存级文件打交道即可,这样子大大的提高了效率!
任何一个文件包括两套资源:
struct file 的操作方法有属于自己的内核缓冲区,所以父进程和子进程有一份公共的资源:文件系统提供的内核缓冲区,父进程可以向对应的文件的文件缓冲区写入,子进程可以通过文件缓冲区读取,此时就完成了进程间通信,这种方式提供的文件称为管道文件。管道文件本质就是内存级文件,不需要 IO。 管道的本质是内核中的缓冲区,通过内核缓冲区实现通信,管道文件只是一个标识符,用于让多个进程能够访问同一块缓冲区,并非通信介质。
并且通过这个内存级别文件的不同形式,我们分为匿名管道和命名管道,后面我们来一一介绍!
二、管道通信原理 通过我们上面所说的,管道是个 内存级别的文件(struct file 中特有的,就像内核缓冲区一样),我们要知道为什么它会叫做 “管道” 呢,是因为它一开始就叫做 “管道” 吗,那肯定不是,是因为它的原理和 “管道” 是类似的,人们后期才会将其命名为 “管道”,而管道是单通向的,不存在双向管道!
并且我们生活中常见的管道比如说水管、油等等它们的作用就是来传输水和油,那么我们计算机中的管道就是传输数据,那么这个流向肯定要是一条单向的,我们就不能想象出其原理结构:
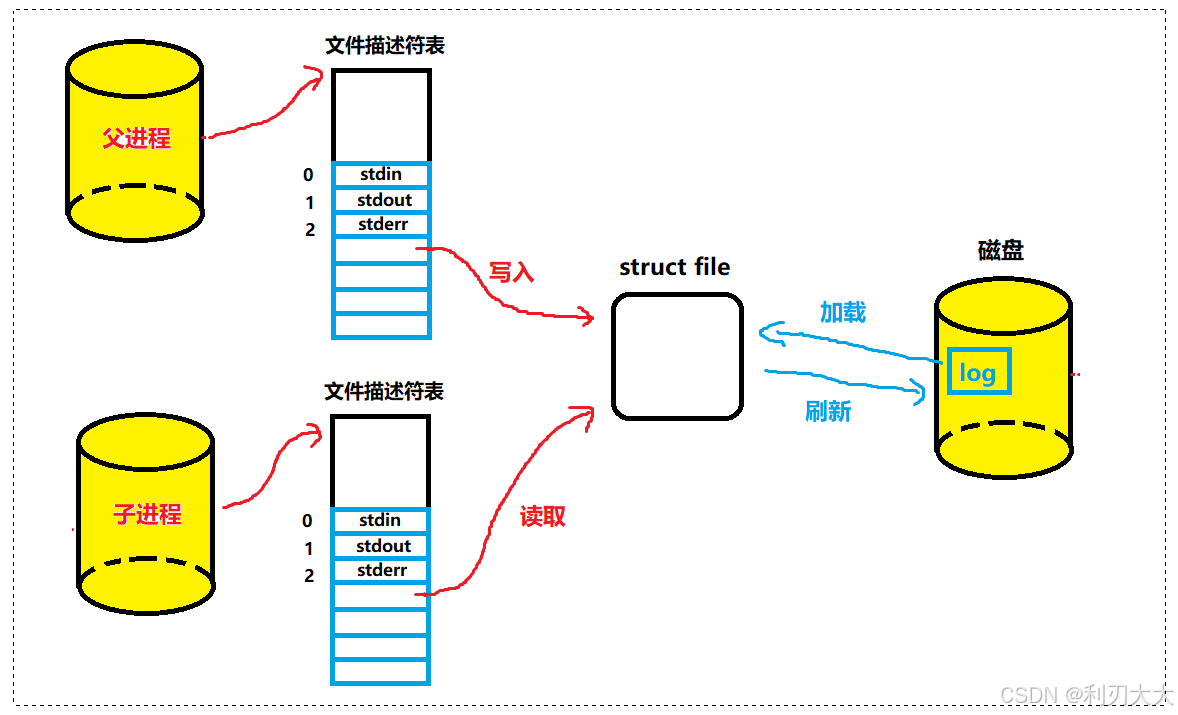
除此之外,我们可以再说说普通文件,我们父进程创建子进程,子进程拷贝父进程的文件描述符表,所以都指向 log 文件,而每次我们写入完毕之后,可能会存在写满等情况就会刷新,那么会访问磁盘,每次读取时候又将 log 加载进内存,不断的来回,这样子 IO 次数非常的多,效率也就非常的低,所以说为什么存在管道文件,其实就是为了避开普通文件通信的效率底下问题!
Ⅱ. 匿名管道一、匿名管道的原理与创建方法 在讲匿名管道之前呢,我们必须知道管道它的通信方法,而对于匿名管道来说,其实就是 通过 fork 创建子进程!(而命名管道的方法不需要创建子进程,后面会讲)
为什么对于匿名管道来说需要创建子进程呢 ❓❓❓
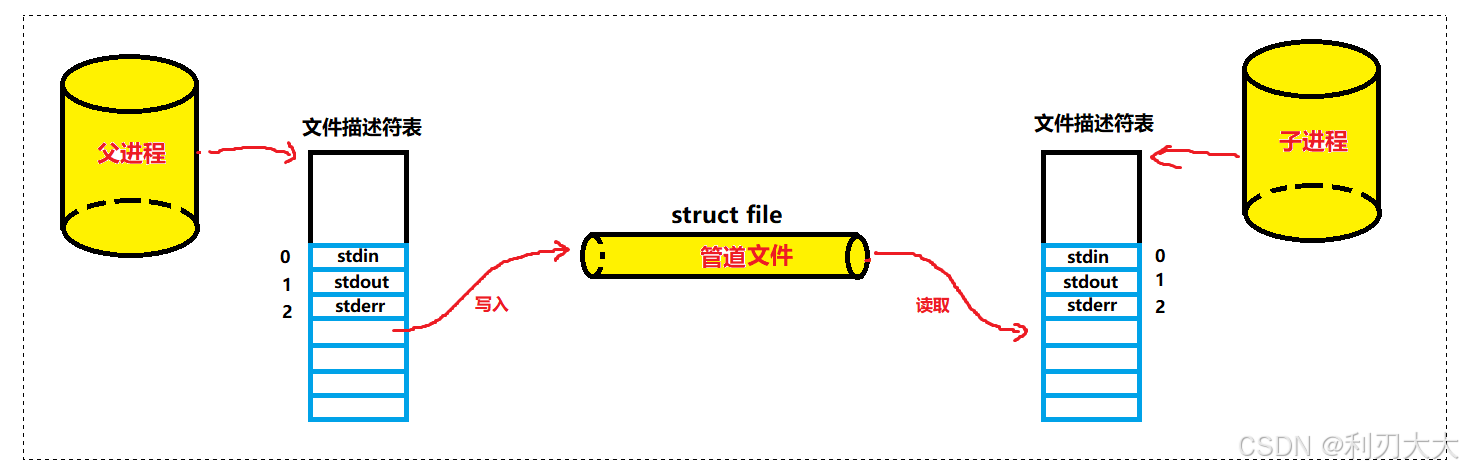
匿名管道的名称由来也是因为这个原因,我们需要通过 fork 创建子进程,我们都知道,子进程会继承父进程的大部分属性和内容包括文件描述符(若发生写时拷贝则会改变),也就是说父进程指向的文件 file,子进程也会指向同一个文件 file(父子进程文件描述符表是独立的,但是指向的文件是同一个),而就像我们下图,父子进程可以都指向该管道文件,这样子的话我们就无需说让子进程和父进程去专门创建一个带名称的管道并且指向它,也就是说我们可以 利用父子进程的继承性让子进程继承这个管道文件达到共同指向它的目的,所以这个管道文件没必要带名称,所以叫做匿名管道!
所以,看待管道,就如同看待文件一样!管道的使用和文件一致,迎合了 “Linux 一切皆文件思想“!
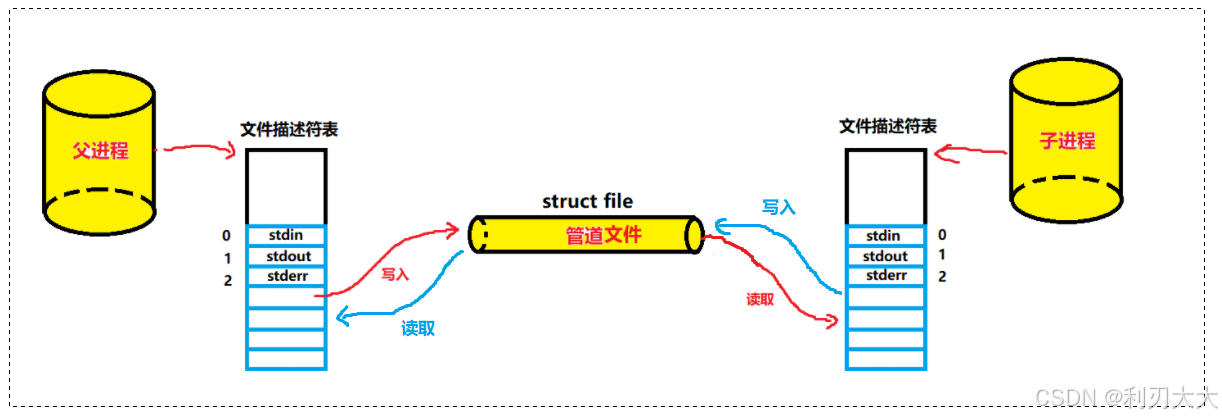
那么我们如何创建这个匿名管道文件呢 ❓❓❓
下面就得调用我们的系统函数 pipe():
#includeint pipe(int pipefd[2]);// 功能:创建一无名管道// 参数:pipefd为文件描述符数组,其中fd[0]表示读端,fd[1]表示写端// 返回值:成功返回0,失败返回-1且设置错误代码
大家是不是就会很疑惑这个 pipefd[2] 数组里面放的是固定的值吗,其实不是的,它会根据当前进程打开文件的个数也就是文件描述符表中 fd_array[] 的有效个数进行返回,但是我们能确定的就是其中 fd[0] 表示的是读,fd[1] 表示的是写,而不需要我们关心具体的 fd 是多少!
假设我们的进程没有打开文件,也就是说只打开了默认的三个标准输入输出流,那么自然我们的 fd[0] = 3,fd[1] = 4,但如果我们开了一个文件,那么 fd[0] = 4,fd[1] = 5,所以说我们关系的是 fd[0] 和 fd[1] 而不是具体的 3 还是 4 !
知道了如何创建匿名管道文件,下面我们来看看如何建立起父子进程之间的通信,也就是让他们看到同一份资源!下面假设我们让父进程进行写入,而子进程进行读取来模拟过程:
首先我们要创建一个父进程,并让这个父进程创建并指向这个管道文件接着父进程fork 创建子进程, 父子进程同时指向管道文件(子进程拷贝父进程大部分内容属性),并且 fd[0] 和 fd[1] 都是打开的然后父进程关闭读端也就是 fd[0],子进程关闭写端也就是 fd[1],这样子的话就形成了一条单向的管道!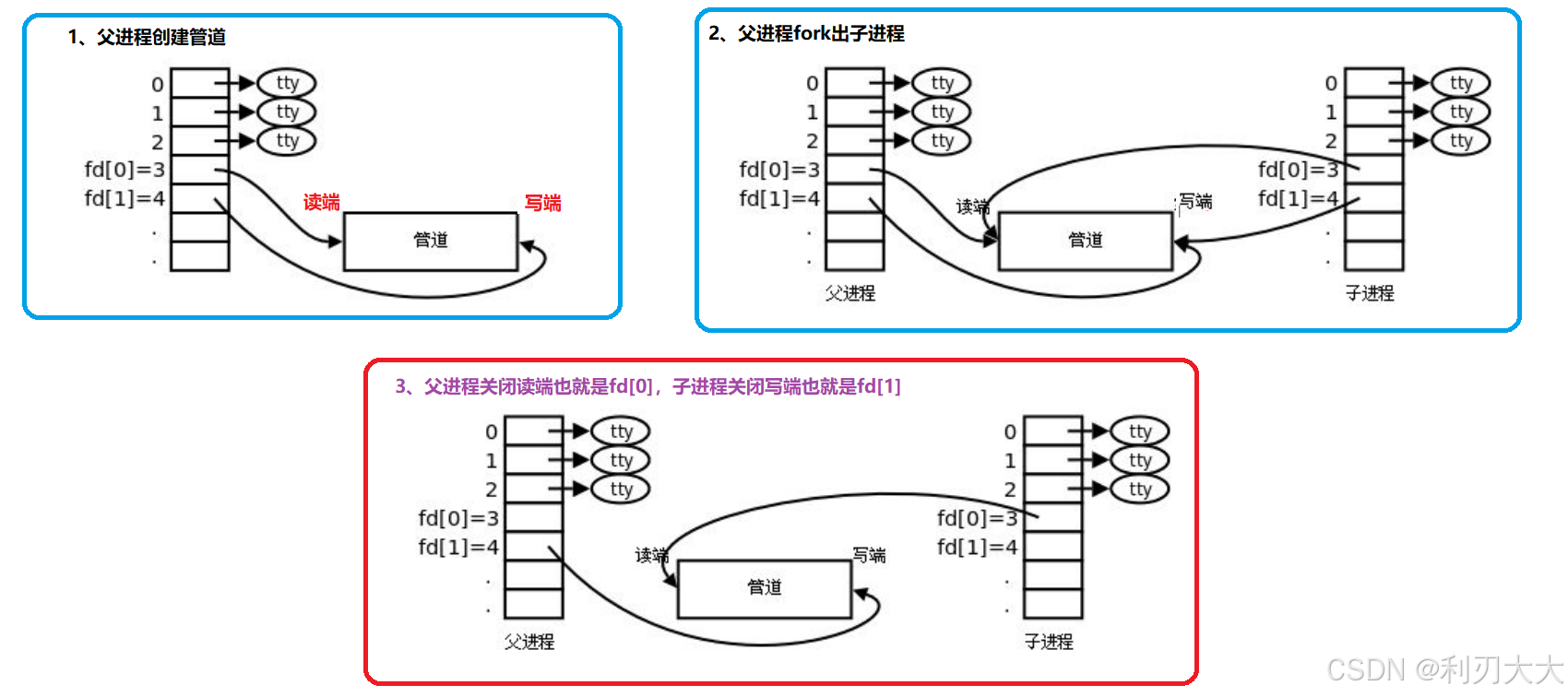
有人会问能不能不关父进程的读端等等,答案肯定是不行的,因为不关的话可能在读写的时候会发生一些问题,所以 不是我们要的管道通向是必须关的!
至于在通信完毕之后,要不要将父子进程中对应的管道关闭呢,这个是建议关闭的,因为不关闭的话,怕会误操作等等!
二、管道读写特征 首先我们先打印一个没有手动打开文件的进程,看看它对应的 fd[0] 和 fd[1] 是多少:
#include#include #include using namespace std;int main(){ int fds[2]; int n = pipe(fds); assert(n != -1); // fds[0]:读 // fds[1]:写 cout

和我们上面的判断一样!
接下来我们来根据上面讲的匿名管道原理,根据通信的步骤,完成父子进程的通信!(下面以子进程写入,父进程读取为例)
① 读取快,写入慢的情况 这里所谓的读取快,写入慢其实就是子进程写入的时候让他先 sleep 一会再写入:
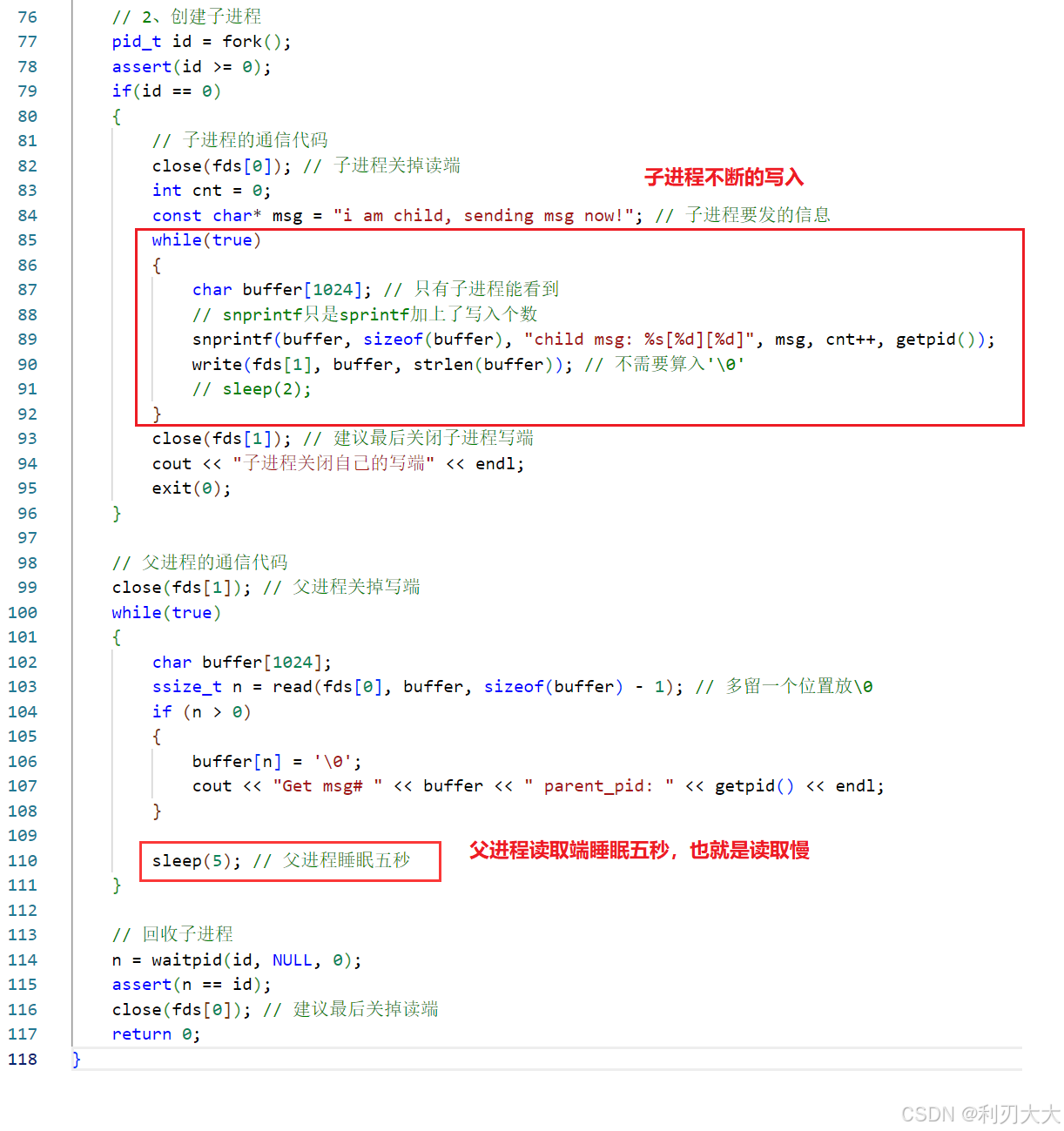
#include#include #include #include #include #include #include #include using namespace std;int main(){ // 1、创建管道文件,打开读写端 int fds[2]; int n = pipe(fds); assert(n == 0); // 2、创建子进程 pid_t id = fork(); assert(id >= 0); if(id == 0) { // 子进程的通信代码 close(fds[0]); // 子进程关掉读端 int cnt = 0; const char* msg = "i am child, sending msg now!"; // 子进程要发的信息 while(true) { char buffer[1024]; // 只有子进程能看到 // snprintf只是sprintf加上了写入个数,将格式化内容转化为字符串 snprintf(buffer, sizeof(buffer), "child msg: %s[%d][%d]", msg, cnt++, getpid()); write(fds[1], buffer, strlen(buffer)); // 不需要算入'\0' sleep(1); // 每隔一秒写一次,这是这个情况的关键点 } close(fds[1]); // 建议最后关闭子进程写端 cout 0) { buffer[n] = '\0'; cout
下面写个监控脚本:
代码语言:javascript代码运行次数:0运行复制while :; do ps ajx | head -1 && ps ajx | grep a.out ; sleep 1 ; done
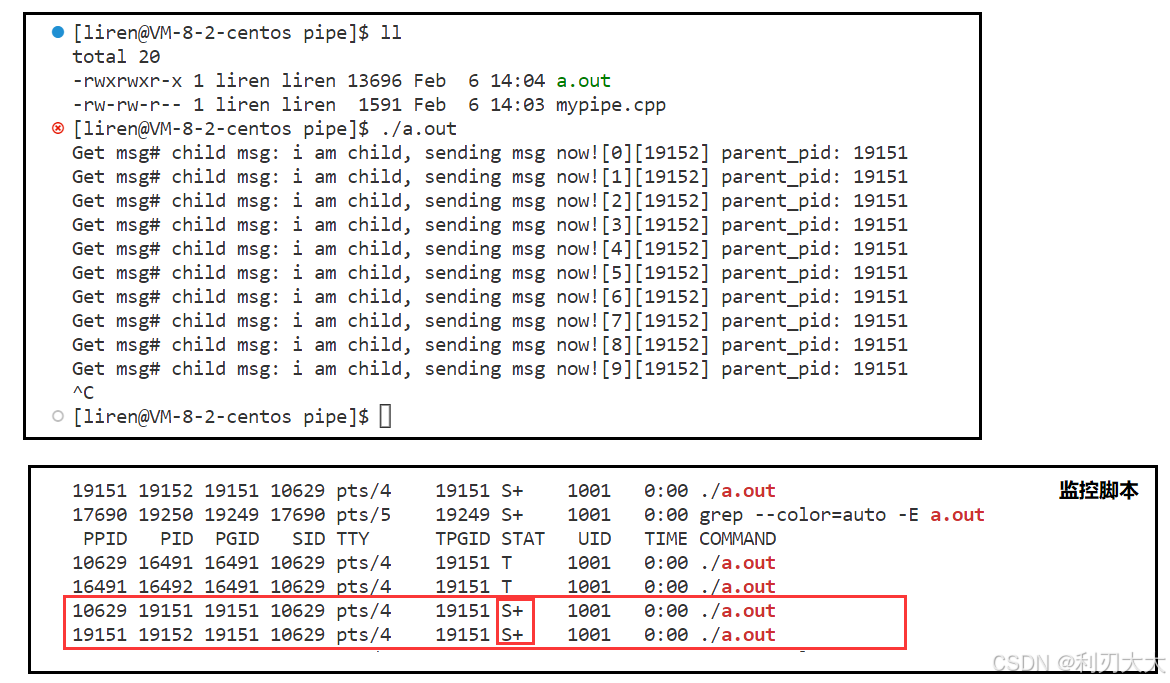
可以看到每 sleep 一秒后父进程接收一次信息,如果我们将 sleep 变成五秒,那么其实父进程会一直处于阻塞状态(监控脚本中看到的 S+ 状态),等待着子进程写入数据,才会响应!也就是说,如果管道中没有写入数据,那么读取的那一端默认会进入阻塞状态!
为了验证一下,我们在父进程读取数据那行代码前后打印一些信息来看看:
代码语言:javascript代码运行次数:0运行复制cout

这个情况和情况①是相反的,也就是让父子进程睡眠的顺序交换一下,当父进程在读取的时候让它 sleep 上一会,然后再读取,而子进程不停的写入,整体代码是不变的:
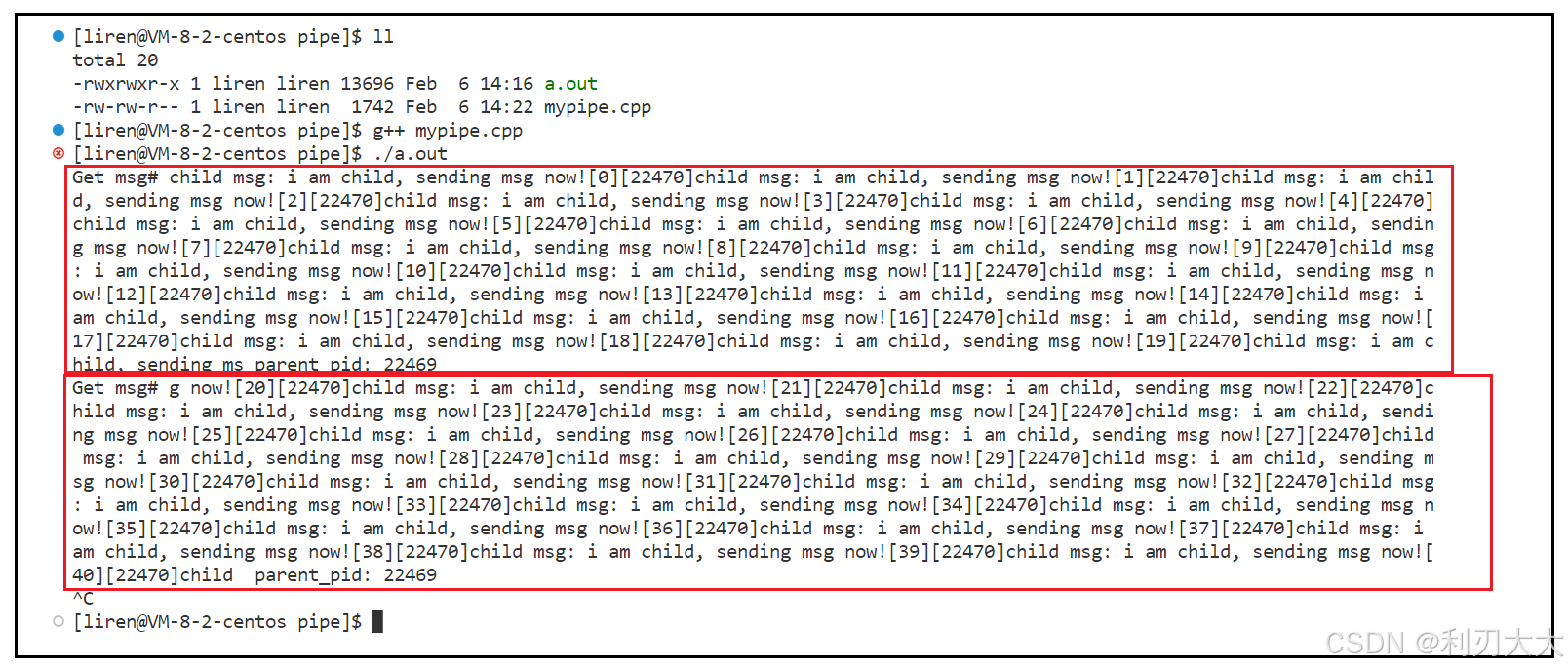
可以看到,在父进程睡眠的五秒期间,子进程其实在不断的写入,所以每隔五秒接收子进程的信息的时候,就是一堆的数据!
并且我们可以将父进程的睡眠时间调久一点,不让父进程去接收,看看让子进程不断的写入数据,我们可以在子进程中打印一下 cnt 的大小看看是怎么变化的,最后会不会这段管道文件被填满:
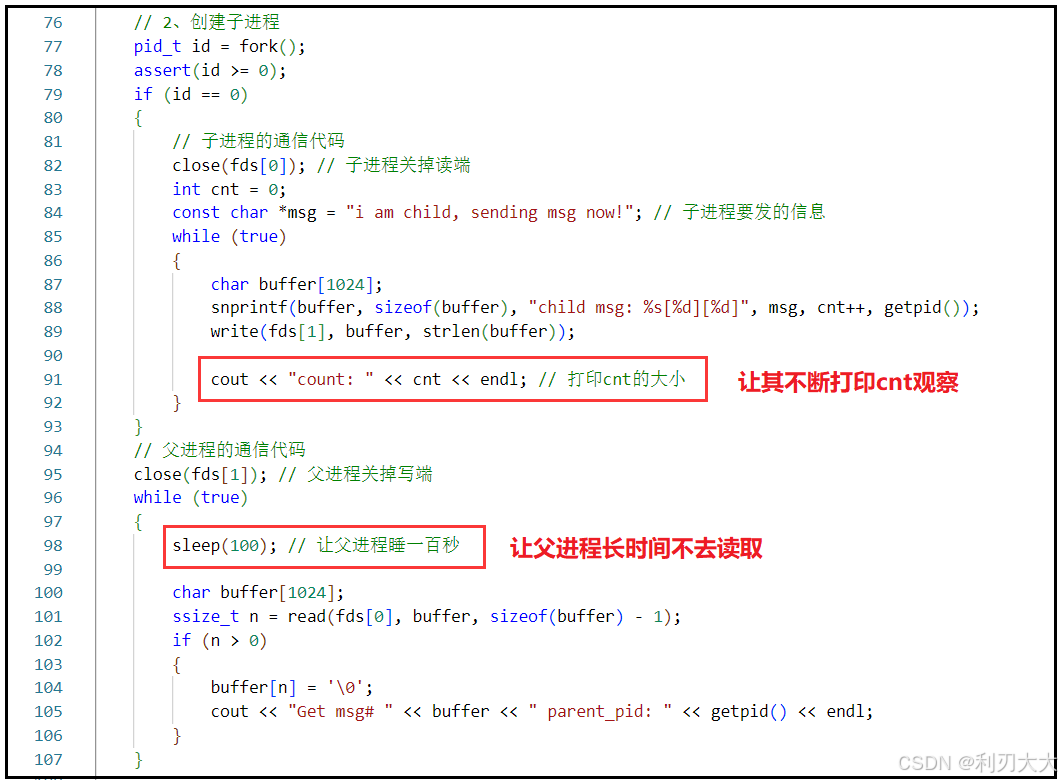

可以看出来,管道文件是有固定大小的,是会被写满的!侧面说明 写入端写满的时候,写入端会阻塞,等待读取端读取!
③ 写入端提前关闭的情况 这里让写入端提前关闭,也就是这里子进程我们让它打印一遍后就直接 break,接着它就会关掉自己的写入端,此时父进程也就是读取端,调用 read 接收的时候,返回值为 0,所以我们可以加以判断后退出。(注意,如果写入端没有被关闭,即使没有写入,那么读取端用 read 的时候也不会返回 0 的!)

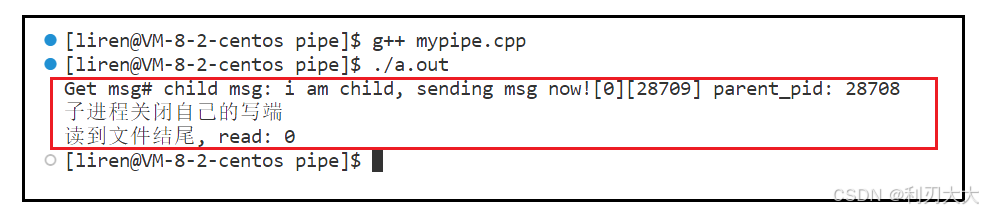
也就是说,写入端提前退出,读取端会读到返回值0!
④ 读取端提前关闭的情况 操作系统很聪明,对于这种读取端提前关闭的情况,操作系统会给写入端进程发送信号,终止写入端,因为没人在接收,那么这只是在浪费系统资源,下面我们用 status 来接受一下子进程的终止信号看看效果:
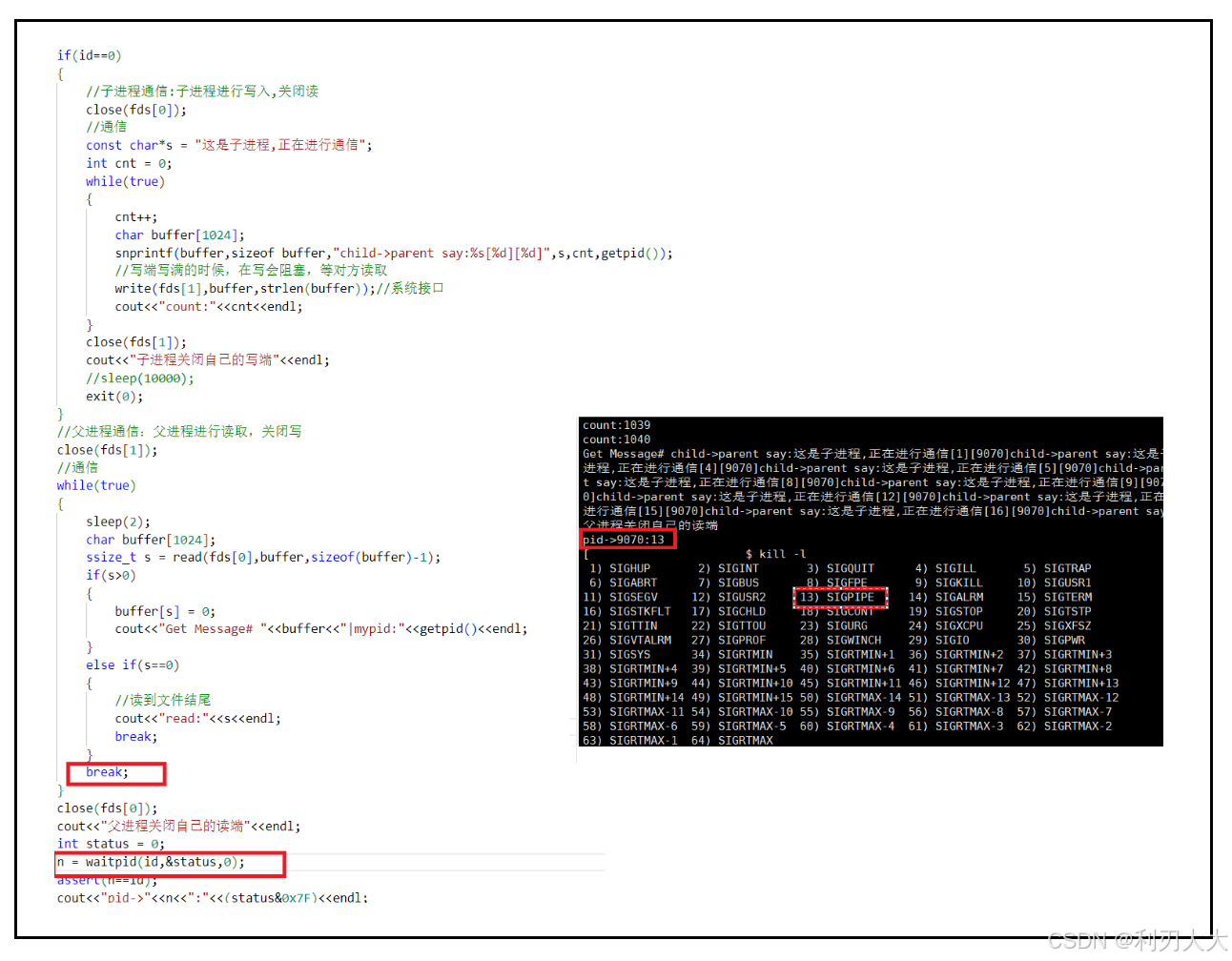
通过上面的几种情况,我们可以看到管道读写的几种规则(额外补充一些):
当没有数据可读时 O_NONBLOCK disable:read 调用阻塞,即进程暂停执行,一直等到有数据来到为止O_NONBLOCK enable:read 调用返回 -1,errno 值为 EAGAIN当管道满的时候 O_NONBLOCK disable: write 调用阻塞,直到有进程读走数据O_NONBLOCK enable:调用返回 -1,errno 值为 EAGAINread 返回 0 如果所有管道读取端对应的文件描述符被关闭,则 write 操作会产生信号 SIGPIPE ,进而 终止写入端 write 当要写入的数据量不大于 PIPE_BUF 时,linux 将保证写入的原子性。 当要写入的数据量大于 PIPE_BUF 时,linux 将不再保证写入的原子性。 Ⅲ. 管道的特征1、一般而言,进程退出,管道释放,所以 管道的生命周期随进程。
2、管道用来进行具有血缘关系的进程之间进行通信,常用于父子通信。
3、管道是 面向字节流 的。(网络)
4、管道是 半双工 的,数据只能向一个方向流动;需要双方通信时,需要建立起两个管道。
5、一般而言,内核会对管道操作进行同步与互斥,这是一种对共享资源进行保护的方案。
6、管道本质是内核中的缓冲区,命名管道文件只是标识,用于让多个进程找到同一块缓冲区,删除后,之前已经打开管道的进程依然可以通信
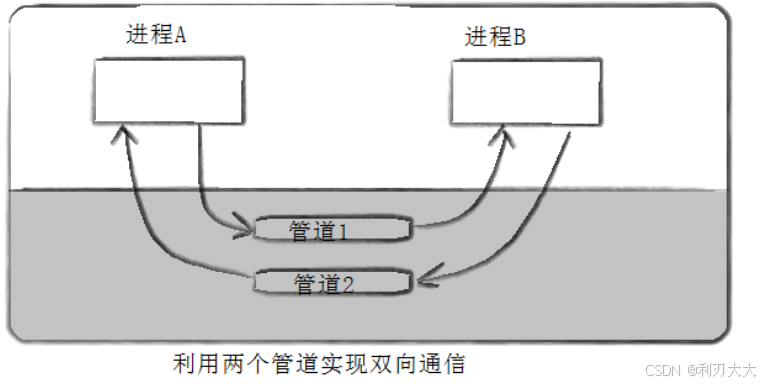
所谓的匿名管道池,其实就是我们的父进程也就是当前进程,有一组子进程等待父进程调度,读取父进程写入的信号进行某些工作的完成,这个就是匿名管道池!池化技术应用也是非常广泛的,这里我们试着写一个小demo!
大概的设计思路就是如下,一个父进程通过创建各自的管道文件对各自的子进程分别管理起来!
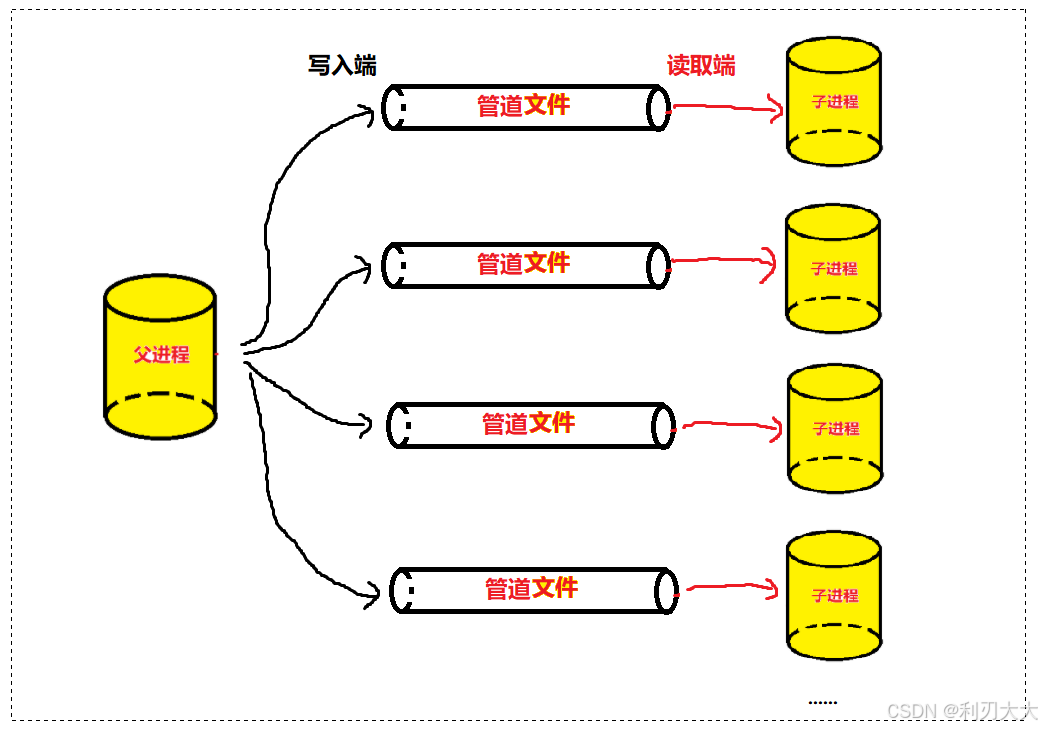
首先我们需要先创建一个管道进程池,其实就是一个数组,其中数组每个元素都是一个结构体,结构体中需要包括每个对应管道文件的写入端文件描述符、子进程的 pid 等等。
可能会有人想为什么不加上那个管道文件的读取端文件描述符呢 ❓❓❓
其实是因为我们在到时候在子进程执行命令那部分代码上面,会调用 pipe() 产生匿名管道,而下面的子进程是能轻易的拿到这个读取端的文件描述符,而对于父进程,它需要管理多个子进程,所以我们需要将每个写端文件描述符记录起来,以便管理!
具体的实现看下面的代码(其中细节挺多,主要从 main 函数切入,并且在 CreateProcessPool 函数也就是创建管道池中存在 bug,需要我们修复,就是每次产生的子进程会拷贝父进程的读写端,如果有多个子进程的话,那么就会造成多个写入端同时指向一个子进程的情况,所以我们必须采取一些措施,具体看代码!):
#include#include #include #include #include #include #include #include #include #include using namespace std;#define MakeSeed() srand((unsigned long)time(nullptr) ^ getpid() ^ 0x171237 ^ rand() % 1234)///中间部分为任务功能部分/typedef void(* func_t)(); // 函数指针void IOTask(){ cout * funcMap){ assert(funcMap); funcMap->push_back(IOTask); funcMap->push_back(DownloadTask); funcMap->push_back(flushTask);}///以下为管道池的管理const int PROCESS_NUM = 5; // 子进程池的个数// 描述每对子进程和管道文件的结构体class childProcess{public: childProcess(pid_t pid, int writeFd) :_pid(pid), _writeFd(writeFd) { char buffer[1024]; snprintf(buffer, sizeof(buffer), "process-%d[pid(%d)|writeFd(%d)]", num++, _pid, _writeFd); _name = buffer; }public: string _name; // 以统一的规则命名的名称 pid_t _pid; // 子进程pid int _writeFd; // 管道文件的写入端 static int num; // 当前子进程为第几个进程编号};int childProcess::num = 0;void SendTask(const childProcess& cp, int index_func){ cout " * pipePool, vector & funcMap){ vector deleteFd; // 记录每次要关闭的前面的子进程的写端 for(int i = 0; i = 0); // 断言一下是否fork成功 // 子进程的执行部分 if(id == 0) { // 每次删掉子进程拷贝父进程的前n个写入端指向 for(int i = 0; i = 0 && commandCode push_back(move(cp)); // 将该对象调用move移动构造到管道池 deleteFd.push_back(pipefd[1]); // 记录每个子进程的前n个写入端fd }}void loadBlanceContrl(vector & cp, vector & fmp, int taskCnt){ int pipe_size = cp.size(); // 管道池个数 int func_size = fmp.size(); // 任务个数 bool forever = (taskCnt == 0 ? true : false); // 判断是否为永远 while(true) { // 1、选择一个子进程 int index_process = rand() % pipe_size; // 2、选择一个任务 int index_func = rand() % func_size; // 3、任务发送给选择的进程 SendTask(cp[index_process], index_func); sleep(1); if(!forever) { taskCnt--; if(taskCnt == 0) break; } } // 关闭写入端 for(int i = 0; i & cp){ for(int i = 0; i " funcMap; LoadFunction(&funcMap); vector pipePool; CreateProcessPool(&pipePool, funcMap); // 2、父进程控制子进程完成任务,负载均衡的向子进程发送命令码,若父进程退出则关闭子进程 int taskCnt = 3; // 0: 永远进行,其它则表示计数 loadBlanceContrl(pipePool, funcMap, taskCnt); // 3、回收子进程信息 waitProcess(pipePool); return 0;}
今天关于《【Linux进程通信】二、深度解析匿名管道》的内容介绍就到此结束,如果有什么疑问或者建议,可以在golang学习网公众号下多多回复交流;文中若有不正之处,也希望回复留言以告知!
-
501 收藏
-
501 收藏
-
501 收藏
-
501 收藏
-
501 收藏
-
文章 · linux | 1天前 | Linux · inode · 日志清理 · 磁盘排查 · 服务器运维 · Linux inode 磁盘空间 df du lsof No space left on device335 收藏
-
422 收藏
-
文章 · linux | 3天前 | 服务器 · Linux · ssh · 运维排查 · 登录慢 · Linux SSH pam sshd_config 登录慢 UseDNS GSSAPI 密钥权限153 收藏
-
文章 · linux | 4天前 | Linux · 运维排查 · 文件句柄 · ulimit · 服务限制 · Linux 文件句柄 lsof ulimit too many open files LimitNOFILE 服务限制482 收藏
-
文章 · linux | 5天前 | Linux · 运维 · 性能排查 · 磁盘IO · iostat · pidstat · Linux 性能排查 iostat 磁盘IO pidstat %util260 收藏
-
335 收藏
-
284 收藏
-
286 收藏
-
494 收藏
-
360 收藏
-
108 收藏
-
227 收藏
-

- 前端进阶之JavaScript设计模式
- 设计模式是开发人员在软件开发过程中面临一般问题时的解决方案,代表了最佳的实践。本课程的主打内容包括JS常见设计模式以及具体应用场景,打造一站式知识长龙服务,适合有JS基础的同学学习。
- 立即学习 543次学习
-

- GO语言核心编程课程
- 本课程采用真实案例,全面具体可落地,从理论到实践,一步一步将GO核心编程技术、编程思想、底层实现融会贯通,使学习者贴近时代脉搏,做IT互联网时代的弄潮儿。
- 立即学习 516次学习
-

- 简单聊聊mysql8与网络通信
- 如有问题加微信:Le-studyg;在课程中,我们将首先介绍MySQL8的新特性,包括性能优化、安全增强、新数据类型等,帮助学生快速熟悉MySQL8的最新功能。接着,我们将深入解析MySQL的网络通信机制,包括协议、连接管理、数据传输等,让
- 立即学习 500次学习
-

- JavaScript正则表达式基础与实战
- 在任何一门编程语言中,正则表达式,都是一项重要的知识,它提供了高效的字符串匹配与捕获机制,可以极大的简化程序设计。
- 立即学习 487次学习
-

- 从零制作响应式网站—Grid布局
- 本系列教程将展示从零制作一个假想的网络科技公司官网,分为导航,轮播,关于我们,成功案例,服务流程,团队介绍,数据部分,公司动态,底部信息等内容区块。网站整体采用CSSGrid布局,支持响应式,有流畅过渡和展现动画。
- 立即学习 485次学习