一文搞定Redis持久化策略(AOF)
来源:51cto
时间:2023-01-22 10:22:08 315浏览 收藏
哈喽!今天心血来潮给大家带来了《一文搞定Redis持久化策略(AOF)》,想必大家应该对数据库都不陌生吧,那么阅读本文就都不会很困难,以下内容主要涉及到Redis、AOF、AOF日志,若是你正在学习数据库,千万别错过这篇文章~希望能帮助到你!
今天为大家介绍Redis的另一种持久化策略——AOF。

什么是AOF
男孩“一觉醒来”忘记了对女孩子的承诺,这时候女孩子把曾经海誓山盟的录音逐条播放给男孩子听,帮助他“恢复记忆”。
“男孩一觉醒来”像极了Redis宕机重启的样子,而女孩子的录音就是Redis的AOF日志。
AOF(Append Only File)以文本的形式(文本格式由Redis自定义,后文会讲到),通过将所有对数据库的写入命令记录到AOF文件中,达到记录数据库状态的目的。
注意:AOF文件只会记录Redis的写操作命令,因为读命令对数据的恢复没有任何意义。
Redis默认并未开启AOF功能,redis.conf配置文件中,关于AOF的相关配置如下:
# 是否开启AOF功能(开启:yes 关闭:no) appendonly yes # 生成的AOF文件名称 appendfilename 6379.aof # AOF写回策略 appendfsync everysec # 当前AOF文件大小和最后一次重写后的大小之间的比率>=指定的增长百分比则进行重写 # 如100代表当前AOF文件大小是上次重写的两倍时候才重写 auto-aof-rewrite-percentage 100 # AOF文件最小重写大小,只有当AOF文件大小大于该值时候才可能重写,4.0默认配置64mb。 auto-aof-rewrite-min-size 64mb
AOF日志格式
下面我们通过一个例子,看一下AOF机制是如何保存我们的操作日志的,我们对Redis进行如下操作。
127.0.0.1:6379[3]> RPUSH list 1 2 3 4 5 (integer) 5 127.0.0.1:6379[3]> LRANGE list 0 -1 1) "1" 2) "2" 3) "3" 4) "4" 5) "5" 127.0.0.1:6379[3]> RPOP list "5" 127.0.0.1:6379[3]> LPUSH list 0 (integer) 5 127.0.0.1:6379[3]> KEYS * 1) "list" 127.0.0.1:6379[3]> LRANGE list 0 -1 1) "0" 2) "1" 3) "2" 4) "3" 5) "4"
Redis会将上述所有的写指令保存到AOF文件中,如下所示:
RPUSH list 1 2 3 4 5 RPOP list LPUSH list 0
当然,AOF文件不是直接以指令的格式进行存储的,我们以第一条指令RPUSH list 1 2 3 4 5为例,看一下AOF文件实际保存该条指令的格式。
*2 $6 SELECT $1 3 *7 $5 RPUSH $4 list $1 1 $1 2 $1 3 $1 4 $1 5
除了 SELECT命令是AOF程序自己加上去的之外, 其他命令都是之前我们在终端里执行的命令。自动添加这条指令是因为Redis恢复数据的时候需要知道待恢复的数据属于哪一个数据库。
其中,*2表示当前命令有2个部分,每部分都是由$+数字开头,后面紧跟着具体的命令、键或值。数字表示这部分中的命令、键或值一共有多少字节。例如,$6 SELECT表示这部分有 6 个字节,也就是SELECT命令。
AOF日志的生成过程
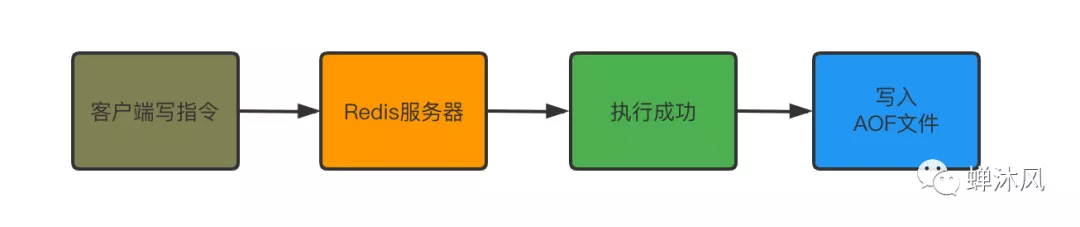
从我们发送写指令开始到指令保存在AOF文件中,需要经历4步,分别为命令传播、命令追加、文件写入和文件同步。
命令传播
命令传播:Redis 将执行完的命令、命令的参数、命令的参数个数等信息发送到 AOF程序中。
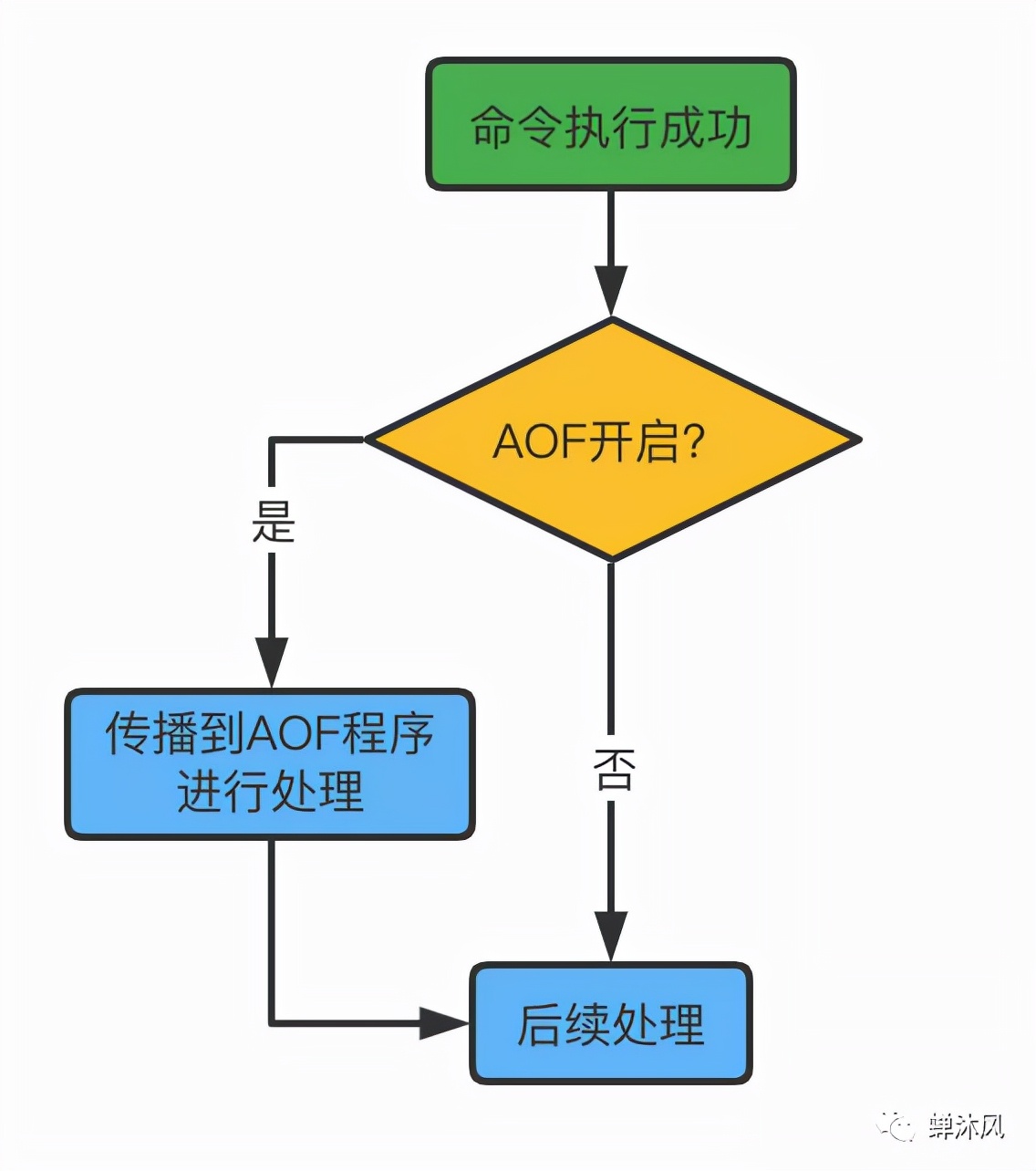
大家有没有关注到其中的一个细节,AOF日志写入是在Redis成功执行命令之后才进行的,为什么要在执行之后而不是之前呢?原因有两点:
首先试想一下,如果我们不小心输错了Redis指令,然后Redis紧接着将该指令保存到了AOF文件中,等到Redis进行数据恢复的时候就可能导致错误。因此这种写后日志的形式可以避免对指令进行语法检查,避免出现记录错误指令的情况。
其次,先执行命令后保存日志,不会阻塞当前的写操作。
但是,AOF写后日志也有两个风险。
第一个风险,假如Redis写操作成功之后突然宕机,此时AOF日志还未来得及写入,则该条指令和相关参数就有丢失的风险。
第二个风险,AOF虽然避免了对当前操作的阻塞,但是有可能阻塞下一个操作。因为保存AOF日志的部分工作也是由主线程完成的(下文有详细介绍),Redis的内存操作速度和文件写入速度简直是云泥之别,如果主线程在文件保存的过程中花费太长的时间必然会阻塞后续的操作。
分析就会发现,第一个风险与AOF写回磁盘的时机有关,写回磁盘的频率越高,发生数据丢失的可能性就越小。第二个风险和文件写入方式以及时机有关,如果Redis每次成功执行指令之后都力图将当前指令同步到AOF文件,开销必然很大。
因此Redis引入了缓冲区的概念,缓冲区对应了文件的写入方式(不求一步到位,允许循序渐进地写入),而何时将缓冲区的内容彻底同步到文件就涉及到了AOF的同步策略(写回磁盘的时机)。
命令追加
在AOF开启的情况下,Redis会将成功执行的写指令以上文我们讲过的协议格式追加到Redis的aof_buf缓冲区。
struct redisServer {
// AOF缓冲区
sds aof_buf;
};aof_buf 缓冲区保存着所有等待写入到AOF 文件的协议文本。
至此,将命令追加到缓存区的步骤完成。
文件写入
文件的写入和同步操作往往被放在一起介绍,这里之所以分开,是想向读者强调文件的写入和同步是两步不同的操作。
为了提高文件的写入效率,当用户调用write函数将数据写入到文件时,操作系统内核会将数据首先保存在内存缓冲区中,等到缓冲区的空间被填满或者到达一定的时机之后,内核会将数据同步到磁盘。
这种同步过于依赖于操作系统内核,时机无法掌控。为此,操作系统提供了fsync和fdatasync两个同步函数,可以强制内核立即将缓冲区内的数据同步到磁盘。
Redis的主服务进程本质上是一个死循环,循环中有负责接受客户端的请求,并向客户端发送回执的逻辑,我们称之为文件事件。
在AOF功能开启的情况下,文件事件会将成功执行之后的写命令追加到aof_buf缓冲区,在主服务进程死循环的最后,会调用flushAppendOnlyFile函数,该函数会将aof_buf中的数据写入到内核缓冲区,然后判断是否应该进行同步。伪代码如下:
void eventLoop {
while(true){
// 根据aof功能是否开启,决定是否将写命令追加到aof_buf缓冲区
handleFileEvents();
// 将aof_buf数据写入内核缓冲区
flushAppendOnlyFile();
};而是否进行同步则是由Redis配置中的appendOnlyFile选项来决定的。
文件同步
redis.conf配置文件中appendOnlyFile的选项有三个值可选,对应三种AOF同步策略,分别是:
No :同步时机由内核决定。
Everysec :每一秒钟同步一次。
Always :每执行一个命令同步一次。
No
由操作系统内核决定同步时机,每个写命令执行完,只是先把日志写入AOF文件的内核缓冲区,不立即进行同步。在这种模式下, 同步只会在以下任意一种情况下被执行:
Redis 被关闭
AOF功能被关闭
系统的写缓存被刷新(可能是缓存已经被写满,或者定期保存操作被执行)
这三种情况下的同步操作都会引起 Redis 主进程阻塞。
Everysec
如果用户未指定appendOnlyFile的值,则默认值为Everysec。每秒同步,每个写命令执行完,只是先把日志写到 AOF文件的内核缓冲区,理论上每隔1秒把缓冲区中的内容同步到磁盘,且同步操作有单独的子线程进行,因此不会阻塞主进程。
需要注意的是,我们用的是「理论上」这样的措辞,实际运行中该模式对fsync或fdatasync的调用并不是每秒一次,而是和调用flushAppendOnlyFile函数时Redis所处的状态有关。
每当 flushAppendOnlyFile 函数被调用时, 可能会出现以下四种情况:
子线程正在执行同步,并且这个同步的执行时间未超过 2 秒,那么程序直接返回 ;这个同步已经执行超过 2 秒,那么程序执行写入操作 ,但不执行新的同步操作 。但是,这时的写入操作必须等待子线程先完成原本的同步操作 ,因此这里的写入操作会比平时阻塞更长时间。
子线程没有在执行同步 ,并且上次成功执行同步距今不超过1秒,那么程序执行写入,但不执行同步 ;上次成功执行同步距今已经超过1秒,那么程序执行写入和同步 。
可以用流程图表示这四种情况:
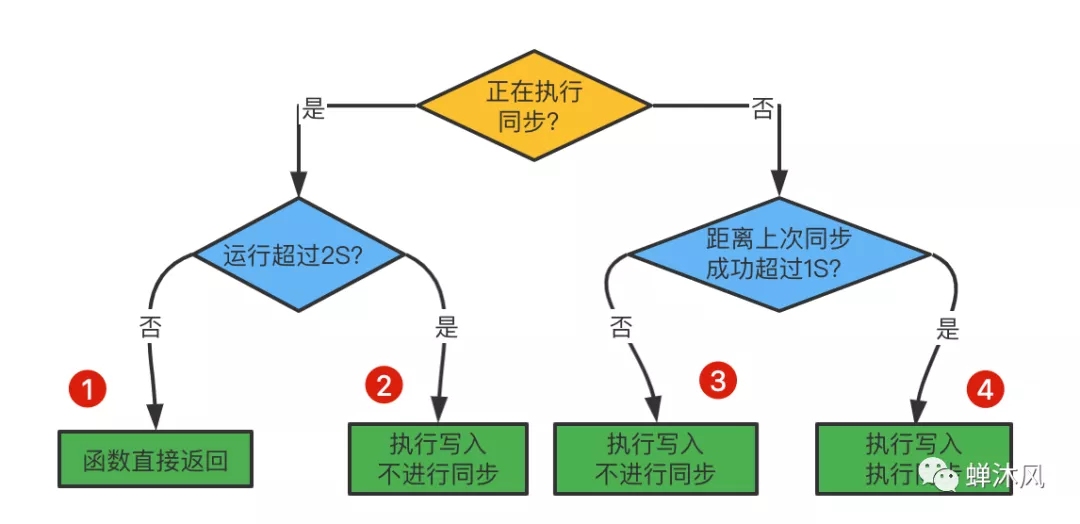
在Everysec模式下
如果在情况1下宕机,那么我们最多损失小于2秒内的所有数据。
如果在情况2下宕机,那么我们损失的数据可能会超过2秒。
因此AOF在Everysec模式下只会丢失 1 秒钟数据的说法实际上并不准确。
Always
每个写命令执行完,立刻同步地将日志写回磁盘。此模式下同步操作是由 Redis 主进程执行的,所以在同步执行期间,主进程会被阻塞,不能接受命令请求。
AOF同步策略小结
对于三种 AOF 同步模式, 它们对Redis主进程的阻塞情况如下:
不同步(No):写入和同步都由主进程执行,两个操作都会阻塞主进程;
每一秒钟同步一次(Everysec):写入操作由主进程执行,阻塞主进程。同步操作由子线程执行,不直接阻塞主进程,但同步操作完成的快慢会影响写入操作的阻塞时长;
每执行一个命令同步一次(Always):同模式 1 。
因为阻塞操作会让 Redis 主进程无法持续处理请求, 所以一般说来, 阻塞操作执行得越少、完成得越快, Redis 的性能就越好。
No的同步操作只会在AOF关闭或Redis关闭时执行, 或由操作系统内核触发。在一般情况下, 这种模式只需要为写入阻塞,因此它的写入性能要比后面两种模式要高, 但是这种性能的提高是以降低安全性为代价的:在这种模式下,如果发生宕机,那么丢失的数据量由操作系统内核的缓存冲洗策略决定。
Everysec在性能方面要优于Always , 并且在通常情况下,这种模式最多丢失不多于2秒的数据, 所以它的安全性要高于No ,这是一种兼顾性能和安全性的保存方案。
Always的安全性是最高的,但性能也是最差的,因为Redis必须阻塞直到命令信息被写入并同步到磁盘之后才能继续处理请求。
三种 AOF模式的特性可以总结为如下表格

AOF生成过程小结
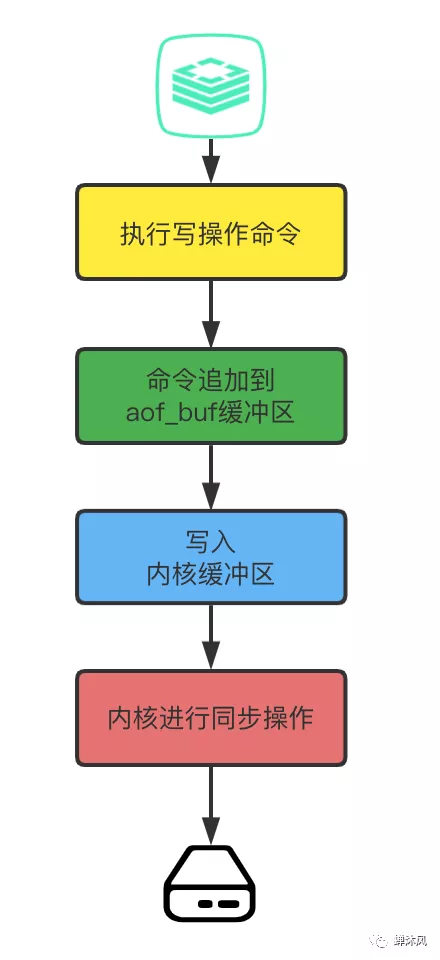
最后总结一下AOF文件的生成过程。以下步骤都是在AOF开启的前提下进行的
Redis成功执行写操作指令,然后将写的指令按照自定义格式追加到aof_buf缓冲区,这是第一个缓冲区;
Redis主进程将aof_buf缓冲区的数据写入到内核缓冲区,这是第二个缓冲区;
根据AOF同步策略适时地将内核缓冲区的数据同步到磁盘,过程结束。
AOF文件的载入和数据还原
AOF文件中包含了能够重建数据库的所有写命令,因此将所有命令读入并依次执行即可还原Redis之前的数据状态。
Redis 读取AOF文件并还原数据库的详细步骤如下:
创建一个不带网络连接的伪客户端(fake client),伪客户端执行命令的效果, 和带网络连接的客户端执行命令的效果完全相同;
读取AOF所保存的文本,并根据内容还原出命令、命令的参数以及命令的个数;
根据指令、指令的参数等信息,使用伪客户端执行命令。
执行 2 和 3 ,直到AOF文件中的所有命令执行完毕。
注意:为了避免对数据的完整性产生影响, 在服务器载入数据的过程中, 只有和数据库无关的发布订阅功能可以正常使用, 其他命令一律返回错误。
AOF重写
AOF的作用是帮我们还原Redis的数据状态,其中包含了所有的写操作,但是正常情况下客户端会对同一个KEY进行多次不同的写操作,如下:
127.0.0.1:6379[3]> SET name chanmufeng1 OK 127.0.0.1:6379[3]> SET name chanmufeng2 OK 127.0.0.1:6379[3]> SET name chanmufeng3 OK 127.0.0.1:6379[3]> SET name chanmufeng4 OK 127.0.0.1:6379[3]> SET name chanmufeng OK
例子中对name的数据进行写操作就进行了5次,其实对我们而言仅需要最后一条指令而已,但是AOF会将这5条指令都记录下来。更极端的情况是有些被频繁操作的键, 对它们所调用的命令可能有成百上千、甚至上万条, 如果这样被频繁操作的键有很多的话,AOF文件的体积就会急速膨胀。
首先,AOF文件的体积受操作系统大小的限制,本身就不能无限增长;
其次,体积过于庞大的AOF文件会影响指令的写入速度,阻塞时间延长;
最后AOF文件的体积越大,Redis数据恢复所需的时间也就越长。
为了解决AOF文件体积庞大的问题,Redis提供了rewrite的AOF重写功能来精简AOF文件体积。
AOF重写的实现原理
虽然叫AOF「重写」,但是新AOF文件的生成并非是在原AOF文件的基础上进行操作得到的,而是读取Redis当前的数据状态来重新生成的。不难理解,后者的处理方式远比前者高效。
为了避免阻塞主线程,导致数据库性能下降,和 AOF 日志由主进程写回不同,重写过程是由子进程执行bgrewriteaof 来完成的。这样处理的最大好处是:
子进程进行 AOF重写期间,主进程可以继续处理命令请求;
子进程带有主进程的数据副本,操作效率更高。
这里有两个问题值得我们来思考一下。
1.为什么使用子进程,而不是多线程来进行AOF重写呢?
如果是使用线程,线程之间会共享内存,在修改共享内存数据的时候,需要通过加锁来保证数据的安全,这样就会降低性能。
如果使用子进程,操作系统会使用「写时复制」的技术:fork子进程时,子进程会拷贝父进程的页表,即虚实映射关系,而不会拷贝物理内存。子进程复制了父进程页表,也能共享访问父进程的内存数据,达到共享内存的效果。
不过这个共享的内存只能以只读的方式,当父子进程任意一方修改了该共享内存,就会发生「写时复制」,于是父子进程就有了独立的数据副本,就不用加锁来保证数据安全。
这里我把在就这?Redis持久化策略——RDB画过的一张图拿过来帮助大家理解一下写时复制。
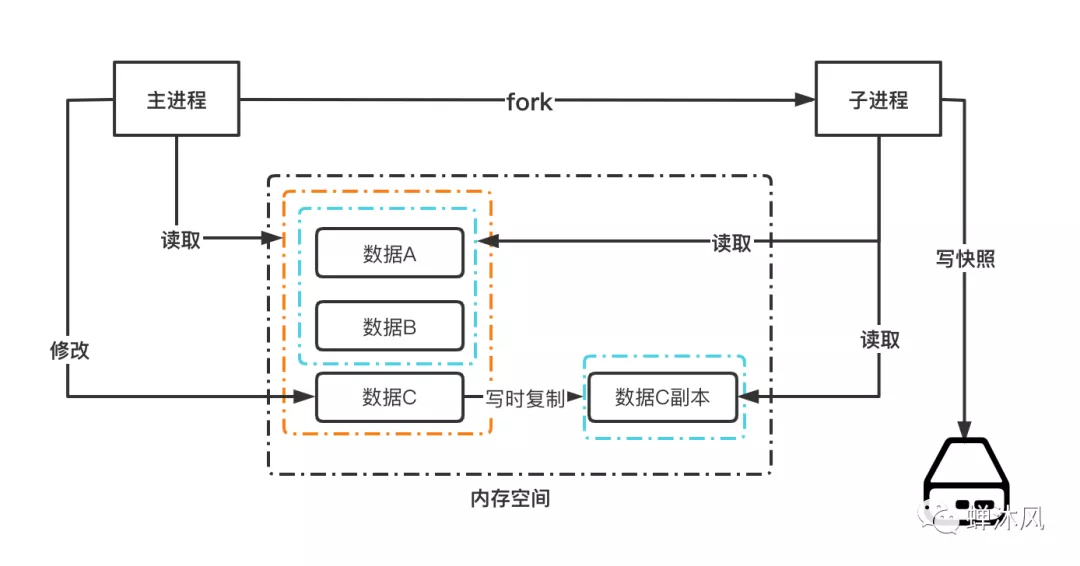
因此,有两个过程可能会导致主进程阻塞:
fork子进程的过程中,由于要复制父进程的页表等数据,阻塞的时间跟页表的大小有关,页表越大阻塞的时间也越长,不过通常而言该过程是非常快的;
fork完子进程后,如果父子进程任意一方修改了共享数据,就会发生「写时复制」,这期间会拷贝物理内存,如果内存越大,自然阻塞的时间也越长。
针对第二个过程,有一个小细节在这里提一下。写时复制,复制的粒度为一个内存页。如果只是修改一个256B的数据,父进程需要读原来的整个内存页,然后再映射到新的物理地址写入。一读一写会造成读写放大。如果内存页越大(例如2MB的大页),那么读写放大也就越严重,对Redis性能造成影响。因此使用Redis的AOF功能时,需要注意页表的大小不要设置的太大。
2.子进程在进行 AOF 重写期间,主进程还需要继续处理命令,而新的命令可能对现有的数据进行修改, 会让当前数据库的数据和重写后的 AOF 文件中的数据不一致,这该怎么办?
为了解决这个问题,Redis引入了另一个缓冲区的概念(这也是本文中涉及到的第3个缓冲区的概念)——AOF重写缓冲区。
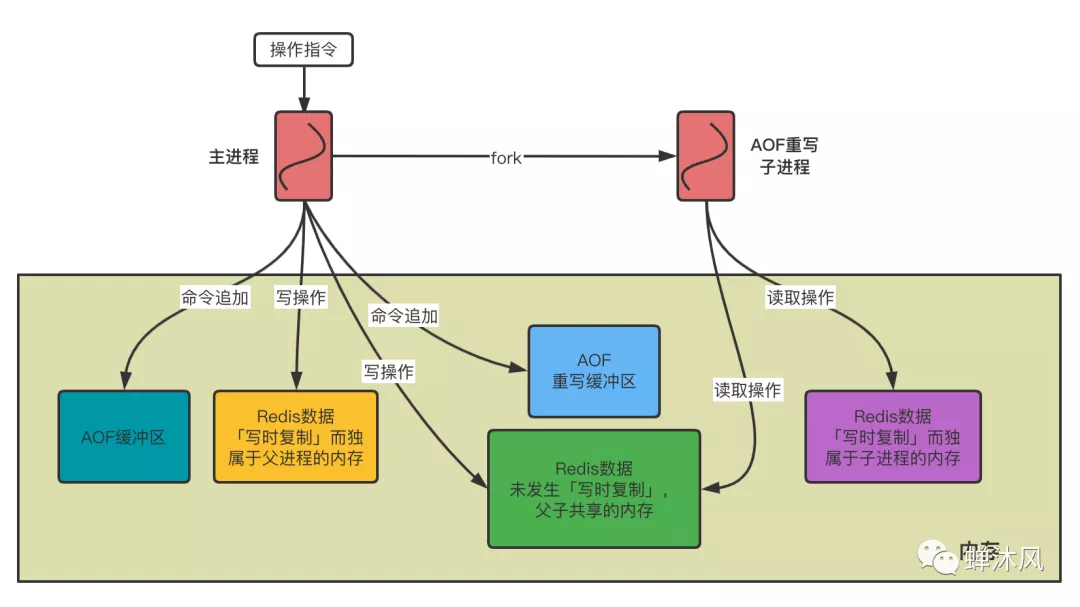
换言之, 当子进程在执行AOF重写(bgrewriteaof)时, 主进程需要执行以下三个工作:
处理客户端的命令请求;
将写命令追加到AOF缓冲区(aof_buf);
将写命令追加到AOF重写缓冲区。
这样一来可以保证:
现有的 AOF功能会继续执行,即使在 AOF 重写期间发生停机,也不会有任何数据丢失;
所有对数据库进行修改的命令都会被记录到AOF重写缓冲区中。
当子进程完成 AOF重写之后, 它会向父进程发送一个完成信号, 父进程在接到完成信号之后, 会调用一个信号处理函数, 并完成以下工作:
将 AOF重写缓冲区中的内容全部写入到新AOF 文件中;
对新的 AOF 文件进行改名,覆盖原有的 AOF 文件。注意,这是一个原子操作,改名过程中不接受客户端指令。
当步骤 1 执行完毕之后, 现有 AOF 文件、新 AOF 文件和数据库三者的状态就完全一致了。
当步骤 2 执行完毕之后, 程序就完成了新旧两个 AOF 文件的交替。
这个信号处理函数执行完毕之后, 主进程就可以继续像往常一样接受命令请求了。 在整个 AOF 后台重写过程中, 只有将AOF重写缓冲区数据写入新AOF文件和改名操作会造成主进程阻塞, 其他时候, AOF 后台重写都不会对主进程造成阻塞, 这将 AOF 重写对性能造成的影响降到了最低。
AOF 后台重写的触发条件
再看一下关于AOF的其他两个配置:
auto-aof-rewrite-percentage 100 auto-aof-rewrite-min-size 64mb
AOF 重写可以由用户通过调用 bgrewriteaof手动触发。
另外, 服务器在 AOF 功能开启的情况下, 会维持以下三个变量:
记录当前 AOF 文件大小的变量 aof_current_size ;
记录最后一次 AOF 重写之后, AOF 文件大小的变量 aof_rewrite_base_size ;
增长百分比变量 aof_rewrite_perc 。
每次当Redis中的定时函数 serverCron 执行时, 它都会检查以下条件是否全部满足, 如果是的话, 就会触发自动的 AOF 重写:
没有 bgsave 命令在进行。
没有 bgrewriteaof 在进行。
当前 AOF 文件大小大于 我们设置的auto-aof-rewrite-min-size。
当前 AOF 文件大小和最后一次 AOF 重写后的大小之间的比率大于等于指定的增长百分比auto-aof-rewrite-percentage。
默认情况下, 增长百分比为 100% , 也即是说, 如果前面三个条件都已经满足, 并且当前 AOF 文件大小比最后一次 AOF 重写时的大小要大一倍的话, 那么触发自动 AOF 重写。
小结
经过多番改稿,终于!给大家梳理完成Redis的AOF持久化方法,最后我们简单总结一下。
AOF是将Redis的所有写日志同步到磁盘的一种持久化方法,通过执行AOF中记录的所有指令可以达到恢复Redis原始数据状态的目的。
对于指令的同步时机,Redis提供了三种AOF同步策略,分别是No,Everysec,Always,三种策略对Redis性能的负面影响是由低到高的,在数据可靠性上也是由低到高的。
为了解决AOF日志太大的问题,Redis提供了AOF重写的机制,利用「写时复制」和「AOF重写缓冲区」达到精简AOF文件的目的。
终于介绍完啦!小伙伴们,这篇关于《一文搞定Redis持久化策略(AOF)》的介绍应该让你收获多多了吧!欢迎大家收藏或分享给更多需要学习的朋友吧~golang学习网公众号也会发布数据库相关知识,快来关注吧!
-
117 收藏
-
426 收藏
-
171 收藏
-
113 收藏
-
195 收藏
-

- 前端进阶之JavaScript设计模式
- 设计模式是开发人员在软件开发过程中面临一般问题时的解决方案,代表了最佳的实践。本课程的主打内容包括JS常见设计模式以及具体应用场景,打造一站式知识长龙服务,适合有JS基础的同学学习。
- 立即学习 543次学习
-

- GO语言核心编程课程
- 本课程采用真实案例,全面具体可落地,从理论到实践,一步一步将GO核心编程技术、编程思想、底层实现融会贯通,使学习者贴近时代脉搏,做IT互联网时代的弄潮儿。
- 立即学习 516次学习
-

- 简单聊聊mysql8与网络通信
- 如有问题加微信:Le-studyg;在课程中,我们将首先介绍MySQL8的新特性,包括性能优化、安全增强、新数据类型等,帮助学生快速熟悉MySQL8的最新功能。接着,我们将深入解析MySQL的网络通信机制,包括协议、连接管理、数据传输等,让
- 立即学习 500次学习
-

- JavaScript正则表达式基础与实战
- 在任何一门编程语言中,正则表达式,都是一项重要的知识,它提供了高效的字符串匹配与捕获机制,可以极大的简化程序设计。
- 立即学习 487次学习
-

- 从零制作响应式网站—Grid布局
- 本系列教程将展示从零制作一个假想的网络科技公司官网,分为导航,轮播,关于我们,成功案例,服务流程,团队介绍,数据部分,公司动态,底部信息等内容区块。网站整体采用CSSGrid布局,支持响应式,有流畅过渡和展现动画。
- 立即学习 485次学习
-

- 繁荣的故事
- 这篇文章内容出现的刚刚好,很详细,真优秀,已收藏,关注作者大大了!希望作者大大能多写数据库相关的文章。
- 2023-06-23 12:39:29
-
- 善良的台灯
- 很好,一直没懂这个问题,但其实工作中常常有遇到...不过今天到这,看完之后很有帮助,总算是懂了,感谢老哥分享技术贴!
- 2023-04-18 00:40:16
-
- 着急的酸奶
- 这篇博文太及时了,太全面了,赞 ??,mark,关注作者了!希望作者能多写数据库相关的文章。
- 2023-04-10 19:09:39
-
- 霸气的毛豆
- 这篇文章出现的刚刚好,太细致了,很好,码起来,关注大佬了!希望大佬能多写数据库相关的文章。
- 2023-03-21 11:47:05
-
- 正直的棒棒糖
- 细节满满,mark,感谢楼主的这篇博文,我会继续支持!
- 2023-03-16 13:06:00
-
- 魁梧的乌冬面
- 这篇技术贴真是及时雨啊,细节满满,很棒,已加入收藏夹了,关注师傅了!希望师傅能多写数据库相关的文章。
- 2023-02-26 22:21:36
-
- 阔达的蓝天
- 这篇文章真是及时雨啊,大佬加油!
- 2023-02-01 21:47:11
-
- 香蕉摩托
- 写的不错,一直没懂这个问题,但其实工作中常常有遇到...不过今天到这,看完之后很有帮助,总算是懂了,感谢大佬分享博文!
- 2023-01-31 17:03:20
-
- 高高的板栗
- 很详细,码起来,感谢up主的这篇博文,我会继续支持!
- 2023-01-26 04:22:46
-
- 单身的手机
- 这篇技术贴太及时了,很详细,很好,收藏了,关注师傅了!希望师傅能多写数据库相关的文章。
- 2023-01-24 20:31:01