k8s部署redis集群实现过程实例详解
来源:脚本之家
时间:2023-02-25 10:18:41 111浏览 收藏
大家好,我们又见面了啊~本文《k8s部署redis集群实现过程实例详解》的内容中将会涉及到k8sredis、集群部署等等。如果你正在学习数据库相关知识,欢迎关注我,以后会给大家带来更多数据库相关文章,希望我们能一起进步!下面就开始本文的正式内容~
写在前面
一般来说,REDIS部署有三种模式。
- 单实例模式,一般用于测试环境。
- 哨兵模式
- 集群模式
后两者用于生产部署
- 哨兵模式
在redis3.0以前,要实现集群一般是借助哨兵sentinel工具来监控master节点的状态。
如果master节点异常,则会做主从切换,将某一台slave作为master。
引入了哨兵节点,部署更复杂,维护成本也比较高,并且性能和高可用性等各方面表现一般。
- 集群模式
3.0 后推出的 Redis 分布式集群解决方案
主节点提供读写操作,从节点作为备用节点,不提供请求,只作为故障转移使用
如果master节点异常,也是会自动做主从切换,将slave切换为master。
总的来说,集群模式明显优于哨兵模式
那么今天我们就来讲解下:k8s环境下,如何部署redis集群(三主三从)?
前置准备
一、nfs安装
- nfs
# 服务端
# 1.安装
yum -y install nfs-utils # nfs文件系统
yum -y install rpcbind # rpc协议
# 2.配置(需要共享的文件夹)
vi /etc/exports
/opt/nfs/pv1 *(rw,sync,no_subtree_check,no_root_squash)
/opt/nfs/pv2 *(rw,sync,no_subtree_check,no_root_squash)
/opt/nfs/pv3 *(rw,sync,no_subtree_check,no_root_squash)
/opt/nfs/pv4 *(rw,sync,no_subtree_check,no_root_squash)
/opt/nfs/pv5 *(rw,sync,no_subtree_check,no_root_squash)
/opt/nfs/pv6 *(rw,sync,no_subtree_check,no_root_squash)
# 3.创建文件夹
mkdir -p /opt/nfs/pv{1..6}
# 4.更新配置并重启nfs服务
exportfs -r #更新配置
systemctl restart rpcbind
systemctl restart nfs
systemctl enable nfs #开机启动
systemctl enable rpcbind
# 5.验证
showmount -e 192.168.4.xx #服务端验证NFS共享
> Export list for 192.168.4.xx:
/opt/nfs/pv6 *
/opt/nfs/pv5 *
/opt/nfs/pv4 *
/opt/nfs/pv3 *
/opt/nfs/pv2 *
/opt/nfs/pv1 *
rpcinfo -p #查看端口
# 客户端
yum -y install nfs-utils
systemctl restart nfs
systemctl enable nfs #开机启动
这里说一下,为什么要安装nfs?
是为了下面创建SC,PV做准备,PV需要使用nfs服务器。
二、SC、PV 创建
2.1创建SC
StorageClass:简称sc,存储类,是k8s平台为存储提供商提供存储接入的一种声明。通过sc和相应的存储插件(csi)为容器应用提供持久存储卷的能力。
vi redis-sc.yaml
apiVersion: storage.k8s.io/v1 kind: StorageClass metadata: name: redis-sc provisioner: nfs-storage
名称为redis-sc
执行创建sc:
kubectl apply -f redis-sc.yaml > storageclass.storage.k8s.io/redis-sc created
通过kuboard查看:
2.2创建PV
PersistentVolume简称pv,持久化存储,是k8s为云原生应用提供一种拥有独立生命周期的、用户可管理的存储的抽象设计。
vi redis-pv.yaml
apiVersion: v1
kind: PersistentVolume
metadata:
name: nfs-pv1
spec:
storageClassName: redis-sc
capacity:
storage: 200M
accessModes:
- ReadWriteMany
nfs:
server: 192.168.4.xx
path: "/opt/nfs/pv1"
名称为nfs-pv1,对应的storageClassName为redis-sc,capacity容器200M,accessModes访问模式可被多节点读写
对应nfs服务器192.168.4.xx,对应文件夹路径/opt/nfs/pv1(对应上面安装nfs服务器)
以此类推,我们创建6个pv......
执行创建sc:
kubectl apply -f redis-pv.yaml > persistentvolume/nfs-pv1 created persistentvolume/nfs-pv2 created persistentvolume/nfs-pv3 created persistentvolume/nfs-pv4 created persistentvolume/nfs-pv5 created persistentvolume/nfs-pv6 created
通过kuboard查看:
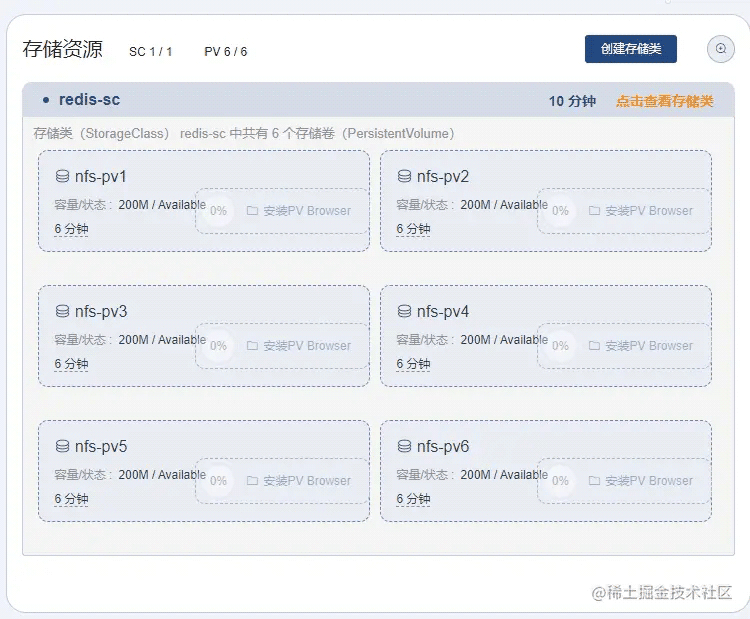
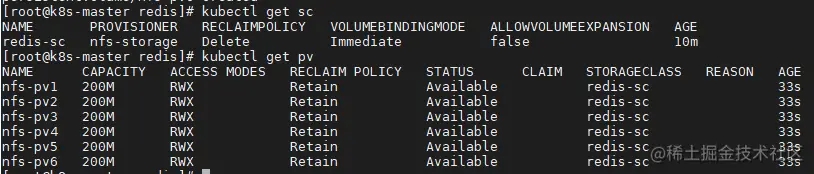
通过kubectl查看:kubectl get sc、kubectl get pv
这里说一下,为什么要创建SC,PV?
因为redis集群,最终需要对应的文件有,redis.conf、nodes.conf、data
由此可见,这些文件每个节点,都得对应有自己得文件夹。
当然redis.conf可以是一个相同得,其他两个,就肯定是不一样得。
如果使用挂载文件夹即是 Volume 的情况部署一个pod,很明显,是不能满足的。
当然,你部署多个不一样的pod,也是可以做到,但是就得写6个部署yaml文件,后期维护也很复杂。
最好的效果是,写一个部署yaml文件,然后有6个replicas副本,就对应了我们redis集群(三主三从)。
那一个pod,再使用Volume挂载文件夹,这个只能是一个文件夹,是无法做到6个pod对应不同的文件夹。
所以这里,就引出了SC、PV了。
使用SC、PV就可以实现,这6个pod启动,就对应上我们创建的6个PV,那就实现了redis.conf、nodes.conf、data,这三个文件,存放的路径,就是不一样的路径了。
哈哈,说了,那么多,不知道,大家明不明白,不明白的可以继续往下看,或者自己部署实操一下,估计你就能明白,为啥要这么干了?
三、redis集群搭建
RC、Deployment、DaemonSet都是面向无状态的服务,它们所管理的Pod的IP、名字,启停顺序等都是随机的,而StatefulSet是什么?顾名思义,有状态的集合,管理所有有状态的服务,比如MySQL、MongoDB集群等。
StatefulSet本质上是Deployment的一种变体,在v1.9版本中已成为GA版本,它为了解决有状态服务的问题,它所管理的Pod拥有固定的Pod名称,启停顺序,在StatefulSet中,Pod名字称为网络标识(hostname),还必须要用到共享存储。
在Deployment中,与之对应的服务是service,而在StatefulSet中与之对应的headless service,headless service,即无头服务,与service的区别就是它没有Cluster IP,解析它的名称时将返回该Headless Service对应的全部Pod的Endpoint列表。
除此之外,StatefulSet在Headless Service的基础上又为StatefulSet控制的每个Pod副本创建了一个DNS域名,这个域名的格式为:
$(pod.name).$(headless server.name).${namespace}.svc.cluster.local
也即是说,对于有状态服务,我们最好使用固定的网络标识(如域名信息)来标记节点,当然这也需要应用程序的支持(如Zookeeper就支持在配置文件中写入主机域名)。
StatefulSet基于Headless Service(即没有Cluster IP的Service)为Pod实现了稳定的网络标志(包括Pod的hostname和DNS Records),在Pod重新调度后也保持不变。同时,结合PV/PVC,StatefulSet可以实现稳定的持久化存储,就算Pod重新调度后,还是能访问到原先的持久化数据。
以下为使用StatefulSet部署Redis的架构,无论是Master还是Slave,都作为StatefulSet的一个副本,并且数据通过PV进行持久化,对外暴露为一个Service,接受客户端请求。
3.1创建headless服务
Headless service是StatefulSet实现稳定网络标识的基础。
vi redis-hs.yaml
---
apiVersion: v1
kind: Service
metadata:
labels:
k8s.kuboard.cn/layer: db
k8s.kuboard.cn/name: redis
name: redis-hs
namespace: jxbp
spec:
ports:
- name: nnbary
port: 6379
protocol: TCP
targetPort: 6379
selector:
k8s.kuboard.cn/layer: db
k8s.kuboard.cn/name: redis
clusterIP: None
命名空间为:jxbp,名称为:redis-hs
执行:
kubectl apply -f redis-hs.yaml > service/redis-hs created
网络访问:pod名称.headless名称.namespace名称.svc.cluster.local
即:pod名称.redis-hs.jxbp.svc.cluster.local
3.2创建redis对应pod集群
创建好Headless service后,就可以利用StatefulSet创建Redis 集群节点,这也是本文的核心内容。
vi redis.yaml
apiVersion: apps/v1
kind: StatefulSet
metadata:
name: redis
namespace: jxbp
labels:
k8s.kuboard.cn/layer: db
k8s.kuboard.cn/name: redis
spec:
replicas: 6
selector:
matchLabels:
k8s.kuboard.cn/layer: db
k8s.kuboard.cn/name: redis
serviceName: redis
template:
metadata:
labels:
k8s.kuboard.cn/layer: db
k8s.kuboard.cn/name: redis
spec:
terminationGracePeriodSeconds: 20
containers:
- name: redis
image: 192.168.4.xx/jxbp/redis:6.2.6
ports:
- name: redis
containerPort: 6379
protocol: "TCP"
- name: cluster
containerPort: 16379
protocol: "TCP"
volumeMounts:
- name: "redis-conf"
mountPath: "/etc/redis/redis.conf"
- name: "redis-data"
mountPath: "/data"
volumes:
- name: "redis-conf"
hostPath:
path: "/opt/redis/conf/redis.conf"
type: FileOrCreate
volumeClaimTemplates:
- metadata:
name: redis-data
spec:
accessModes: [ "ReadWriteMany" ]
resources:
requests:
storage: 200M
storageClassName: redis-sc
名称为:redis,对应的镜像为:redis:6.2.6,
挂载的文件:宿主机的/opt/redis/conf/redis.conf到redis容器的/etc/redis/redis.conf(redis.conf配置文件如下所示)
PVC存储卷声明模板volumeClaimTemplates,指定了名称为redis-sc的SC(storageClassName)
由于之前SC绑定了PV,所以这里的PVC和PV,就能一 一对应绑定上了。
PV和PVC的关系,是一 一绑定的。如果这里不指定SC,那就会导致,PVC绑定PV,是一个混乱的过程,随机绑定PV了。
- redis.conf
# 一般配置 bind 0.0.0.0 port 6379 daemonize no requirepass jxbd # 集群配置 cluster-enabled yes cluster-config-file nodes.conf cluster-node-timeout 5000
执行:
kubectl apply -f redis.yaml
由上操作,我们已经创建好redis的6个副本了。
因为k8s部署redis集群的篇幅,有点长
文中关于redis的知识介绍,希望对你的学习有所帮助!若是受益匪浅,那就动动鼠标收藏这篇《k8s部署redis集群实现过程实例详解》文章吧,也可关注golang学习网公众号了解相关技术文章。
-
501 收藏
-
501 收藏
-
501 收藏
-
501 收藏
-
501 收藏
-
数据库 · Redis | 19小时前 | Redis · go · Pipeline · 批处理 · 重试 · 幂等性 · 重试 go-redis 幂等键 批量写入 Redis Pipeline 逐条结果391 收藏
-
154 收藏
-
386 收藏
-
127 收藏
-
422 收藏
-
326 收藏
-
494 收藏
-
数据库 · Redis | 4天前 | Redis · 缓存 · 限流 · Redis 8.8 · INCREX · Redis 8.8 INCREX Redis窗口限流 Redis计数器 ENX UBOUND123 收藏
-
数据库 · Redis | 6天前 | Redis · 缓存 · go · Redis Cluster · 排错 · Redis Cluster CROSSSLOT Hash Tag MGET CLUSTER KEYSLOT259 收藏
-
183 收藏
-
413 收藏
-
数据库 · Redis | 1星期前 | Redis · 安全配置 · 数据库运维 · ACL · 网络隔离 · Redis公网暴露 Redis protected-mode Redis ACL Redis安全配置 Redis审计364 收藏
-

- 前端进阶之JavaScript设计模式
- 设计模式是开发人员在软件开发过程中面临一般问题时的解决方案,代表了最佳的实践。本课程的主打内容包括JS常见设计模式以及具体应用场景,打造一站式知识长龙服务,适合有JS基础的同学学习。
- 立即学习 543次学习
-

- GO语言核心编程课程
- 本课程采用真实案例,全面具体可落地,从理论到实践,一步一步将GO核心编程技术、编程思想、底层实现融会贯通,使学习者贴近时代脉搏,做IT互联网时代的弄潮儿。
- 立即学习 516次学习
-

- 简单聊聊mysql8与网络通信
- 如有问题加微信:Le-studyg;在课程中,我们将首先介绍MySQL8的新特性,包括性能优化、安全增强、新数据类型等,帮助学生快速熟悉MySQL8的最新功能。接着,我们将深入解析MySQL的网络通信机制,包括协议、连接管理、数据传输等,让
- 立即学习 500次学习
-

- JavaScript正则表达式基础与实战
- 在任何一门编程语言中,正则表达式,都是一项重要的知识,它提供了高效的字符串匹配与捕获机制,可以极大的简化程序设计。
- 立即学习 487次学习
-

- 从零制作响应式网站—Grid布局
- 本系列教程将展示从零制作一个假想的网络科技公司官网,分为导航,轮播,关于我们,成功案例,服务流程,团队介绍,数据部分,公司动态,底部信息等内容区块。网站整体采用CSSGrid布局,支持响应式,有流畅过渡和展现动画。
- 立即学习 485次学习