Redis处理高并发之布隆过滤器详解
来源:脚本之家
时间:2023-02-25 09:32:51 238浏览 收藏
本篇文章给大家分享《Redis处理高并发之布隆过滤器详解》,覆盖了数据库的常见基础知识,其实一个语言的全部知识点一篇文章是不可能说完的,但希望通过这些问题,让读者对自己的掌握程度有一定的认识(B 数),从而弥补自己的不足,更好的掌握它。
缓存穿透、击穿、雪崩
首先我们从缓存会出现的几种问题,来进行分析,在高并发的场景下如果出现这种情况,我们应该如何解决。
正常情况下,我们的web应用会先去请求缓存服务,如果缓存命中,那么就去拿缓存里面的数据,返回结果给应用,
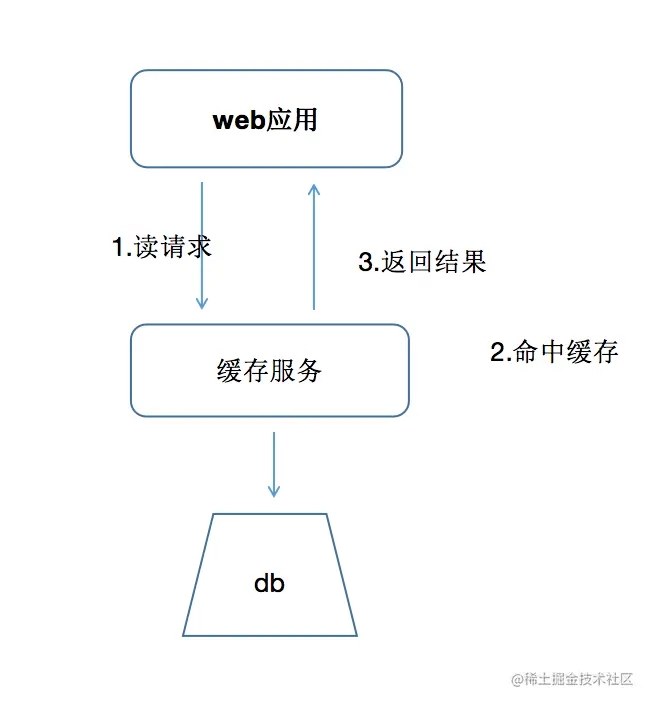
缓存穿透
缓存穿透与缓存雪崩和缓存击穿还是不一样的,雪崩和击穿的情况下,数据库的数据都是真正常的,可以去请求数据库获取数据,只是缓存层出现问题,等待缓存恢复了,就会减轻数据库的压力。 而缓存透不一样的就是,缓存和数据库都没有要请求的数据,大量的请求来了,数据库的压力很大。
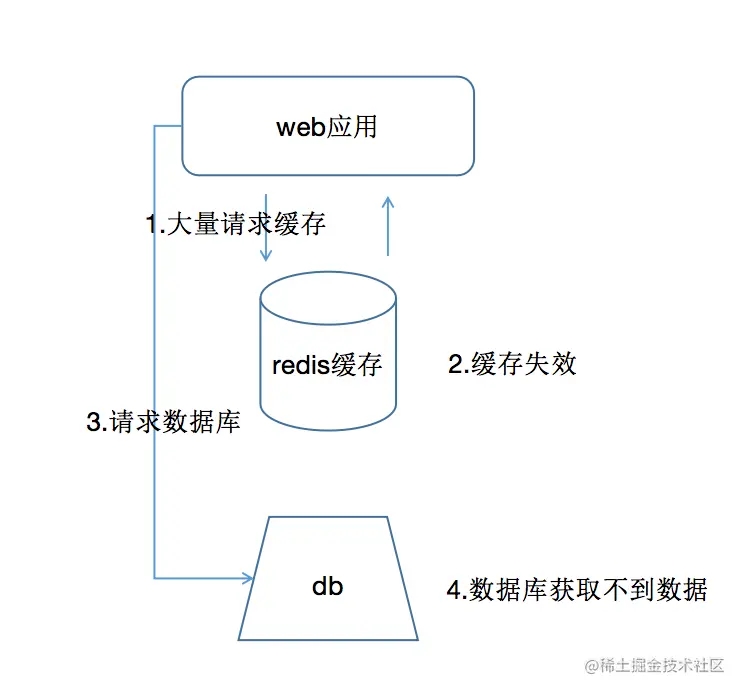
出现情况
- 数据库数据被大量清除,导致访问不到
- 黑客恶意攻击
常见的解决方案
- redis缓存空值,请求不到的时候返回给应用空值。
- 使用布隆过滤器,把数据库的一部分数据hash到布隆过滤器里,在请求数据库之前先去布隆过滤器里筛选到一部分请求,判断数据是否存在,避免直接去访问数据库。
缓存击穿
出现情况
- 大量热点数据库过期,导致无法从缓存获取到数据,大量请求数据库也无法返回书就
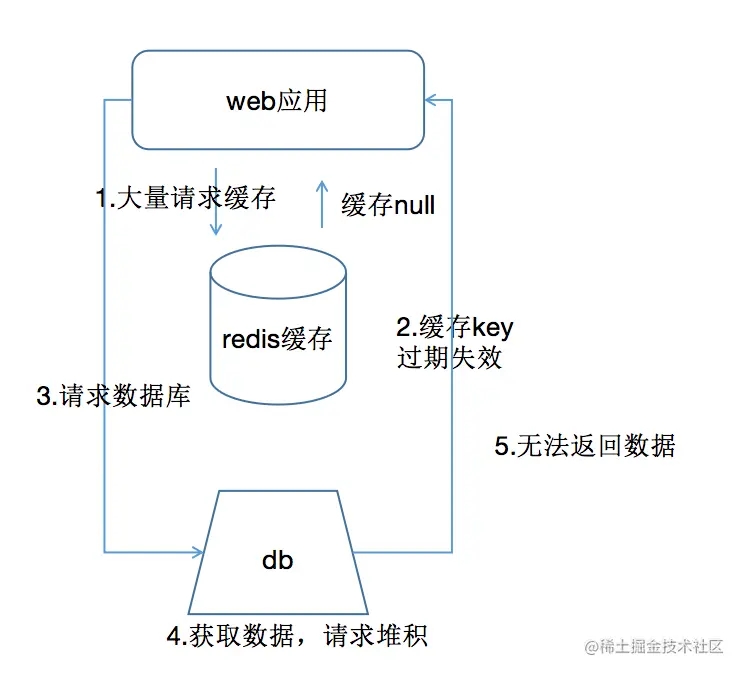
解决方案
- 加锁,保证同一时间内,只允许有一个线程去更新缓存,等锁释放后在重新去请求缓存。
- 热点数据不去设置过期时间,如果要设置过期时间,在过期的时候通知后台去更新缓存的过期时间。
缓存雪崩
- 大量缓存在同一时间失效,导致大量请求进入数据库
- redis故障宕机,导致缓存不能使用。
解决方案
- 同上加锁
- 给缓存的过期时间加入随机数,保证缓存不会在同一时间同时失效。
- 副本key策略,就是对于一个key,在它的基础上在设置一个key,它们的value都是一样的,只不过一个设置过期时间、一个不设置过期时间,相当于给key做了个副本,只不过在更新缓存的时候,副本key也是要更新的,避免出现数据不一致的现象。
布隆过滤器 Bloom filter
前面提到过布隆过滤器在请求比较高的时候,可以帮助我们抵挡一部分请求,从而减轻数据库的压力,布隆过滤器的数据结构是一个二进制的bit向量,或者说是一个bit数组,它相对于list、set、map这些集合,它占用的空间更少,不足之处处就是返回的结果会有一定概率的误差。
public static void main(String[] args) {
int size = 1_000_000;
BloomFilter bloomFilter = BloomFilter.create(Funnels.integerFunnel(), size);
for (int i = 0; i list = new ArrayList(1000);
for (int i = size + 10000; i
确实有误差的数量,但是误差量不大,追求效率的同时只是牺牲一点误差了。

总结
加锁的排队的场景确实能帮助我们很好的解决缓存穿透、击穿的一些问题,但是效率也是非常低了,因为每个请求都是排队等待,如果可以接受轻微误差的话,布隆过滤器的确是个很不错的选择,Bloom filter的bitmap的存储效率确实很高。
今天关于《Redis处理高并发之布隆过滤器详解》的内容就介绍到这里了,是不是学起来一目了然!想要了解更多关于redis的内容请关注golang学习网公众号!
-
497 收藏
-
342 收藏
-
288 收藏
-
178 收藏
-
283 收藏
-
119 收藏
-
280 收藏
-
数据库 · Redis | 1星期前 | Redis · 缓存治理 · Keyspace Notifications · 过期事件 · redis Pub/Sub Keyspace Notifications 过期事件 缓存监听 补偿任务181 收藏
-
501 收藏
-
400 收藏
-
313 收藏
-
235 收藏
-
464 收藏
-
436 收藏
-
407 收藏
-
数据库 · Redis | 3星期前 | Redis · Streams · 消费者组 · Pending · XACK · 消息堆积 消费者组 XACK XPENDING XAUTOCLAIM Redis Streams385 收藏
-
194 收藏
-

- 前端进阶之JavaScript设计模式
- 设计模式是开发人员在软件开发过程中面临一般问题时的解决方案,代表了最佳的实践。本课程的主打内容包括JS常见设计模式以及具体应用场景,打造一站式知识长龙服务,适合有JS基础的同学学习。
- 立即学习 543次学习
-

- GO语言核心编程课程
- 本课程采用真实案例,全面具体可落地,从理论到实践,一步一步将GO核心编程技术、编程思想、底层实现融会贯通,使学习者贴近时代脉搏,做IT互联网时代的弄潮儿。
- 立即学习 516次学习
-

- 简单聊聊mysql8与网络通信
- 如有问题加微信:Le-studyg;在课程中,我们将首先介绍MySQL8的新特性,包括性能优化、安全增强、新数据类型等,帮助学生快速熟悉MySQL8的最新功能。接着,我们将深入解析MySQL的网络通信机制,包括协议、连接管理、数据传输等,让
- 立即学习 500次学习
-

- JavaScript正则表达式基础与实战
- 在任何一门编程语言中,正则表达式,都是一项重要的知识,它提供了高效的字符串匹配与捕获机制,可以极大的简化程序设计。
- 立即学习 487次学习
-

- 从零制作响应式网站—Grid布局
- 本系列教程将展示从零制作一个假想的网络科技公司官网,分为导航,轮播,关于我们,成功案例,服务流程,团队介绍,数据部分,公司动态,底部信息等内容区块。网站整体采用CSSGrid布局,支持响应式,有流畅过渡和展现动画。
- 立即学习 485次学习