ThinkingMachinesLab揭示LLM推理真相
时间:2025-09-11 18:27:57 484浏览 收藏
Thinking Machines Lab 发布首篇技术博客,揭示了大语言模型(LLM)推理中不确定性的真相。即使在温度设置为 0 的情况下,LLM 的输出仍可能因并行计算策略的动态变化而产生差异。该博客深入分析了浮点数运算的非结合律和并行计算策略对 LLM 推理结果的影响,并提出通过确保所有关键计算内核具备 batch-invariant 特性来解决这一问题。针对 RMSNorm、矩阵乘法和注意力机制等核心组件,团队提出了相应的改进方法,并在 Qwen3-235B-A22B-Instruct-2507 模型上进行了验证,成功实现了 100% 可重复的大模型推理输出,为 LLM 的确定性推理提供了新的解决方案。
由前 OpenAI 首席技术官 Mira Murati 创立的 Thinking Machines Lab 近日发布了其首篇技术博客:《在 LLM 推理中战胜不确定性》("Defeating Nondeterminism in LLM Inference")。
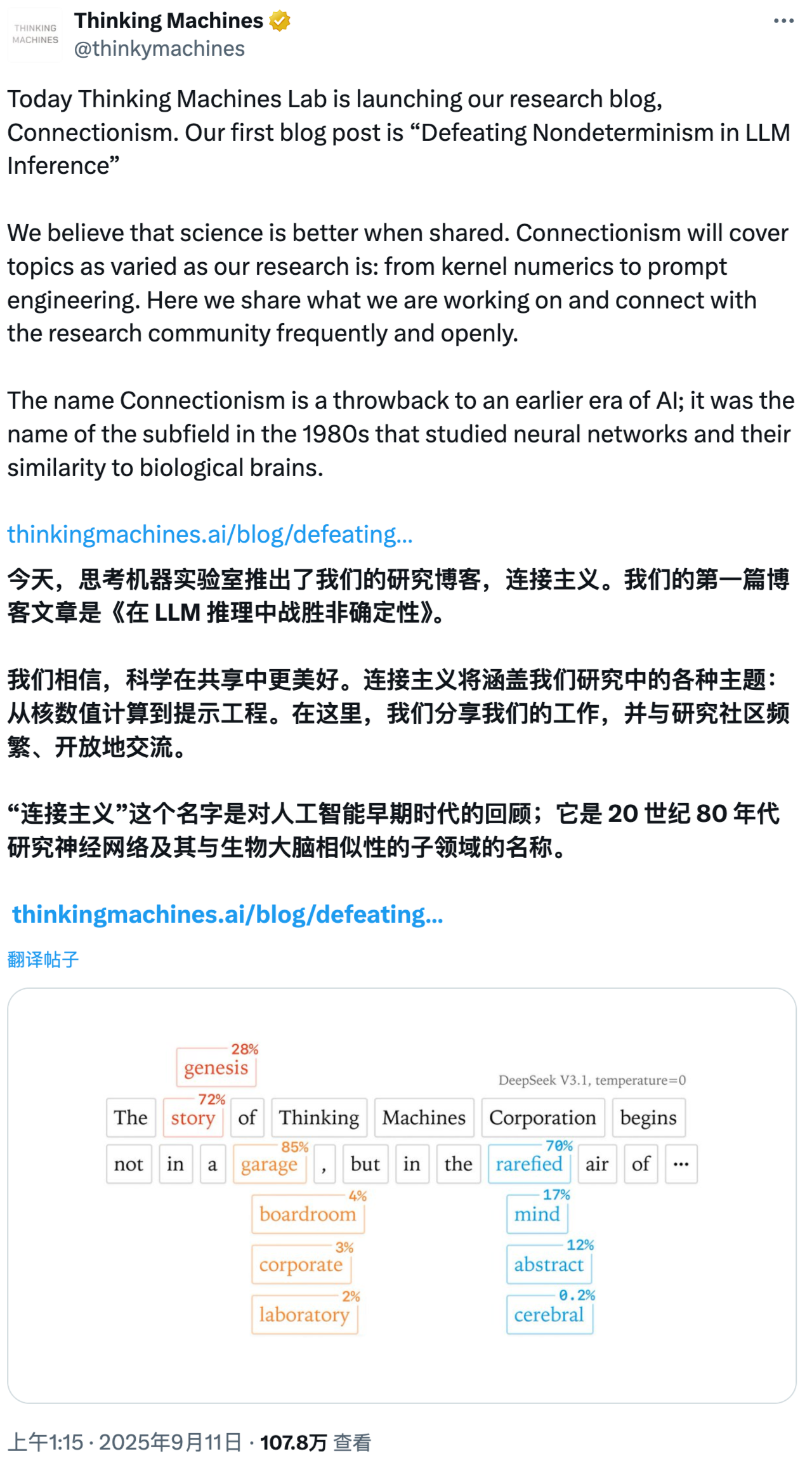
尽管将大语言模型的温度设置为 0,并使用完全相同的输入、模型和硬件,输出结果仍可能出现差异。这篇博客深入探讨了这一现象背后的原因,并提出了解决方案——如何实现 100% 可重复的大模型推理输出。
文章指出,造成这种不确定性的因素主要有两个:
1. 浮点数加法不具备结合律特性(floating-point non-associativity)
即 (a + b) + c 与 a + (b + c) 在浮点运算中可能产生不同结果。由于并行计算时求和顺序不一致,会引入微小数值偏差。不过,作者认为这并非问题的主要根源。
2. 并行计算策略的动态变化(Dynamic Parallelization Strategies)
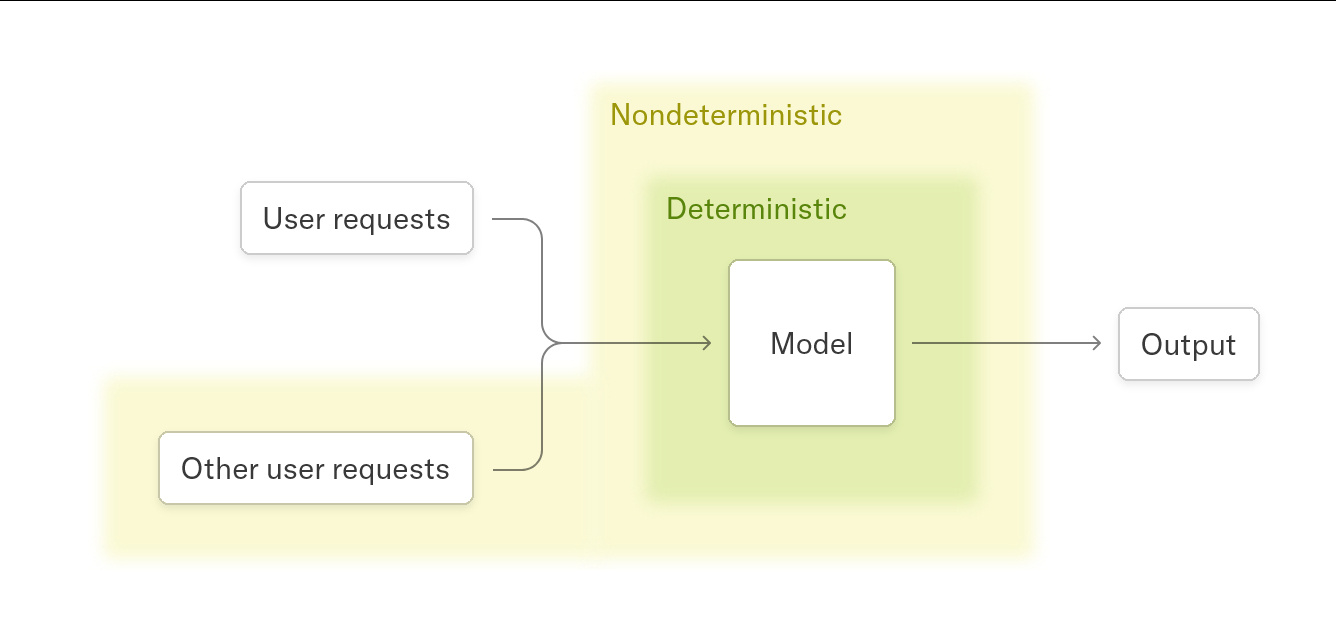
这是导致输出不一致的核心原因。当 batch size、序列长度或 KV-cache 的状态发生变化时,GPU 内核可能会选择不同的并行执行路径,进而改变计算顺序,最终影响输出结果。
为解决此问题,作者提出必须确保所有关键计算内核(kernel)具备 batch-invariant 特性——无论输入批次大小或序列如何分割,计算过程和结果都应保持完全一致。
针对三大核心组件,团队提出了相应的改进方法:
- RMSNorm:重构归一化计算流程,保证跨设备和批处理的一致性
- 矩阵乘法(Matrix Multiplication):采用确定性算法路径,避免因分块策略不同带来的误差
- 注意力机制(Attention):设计统一的并行化模式,消除 softmax 与 KV-cache 操作中的非确定性
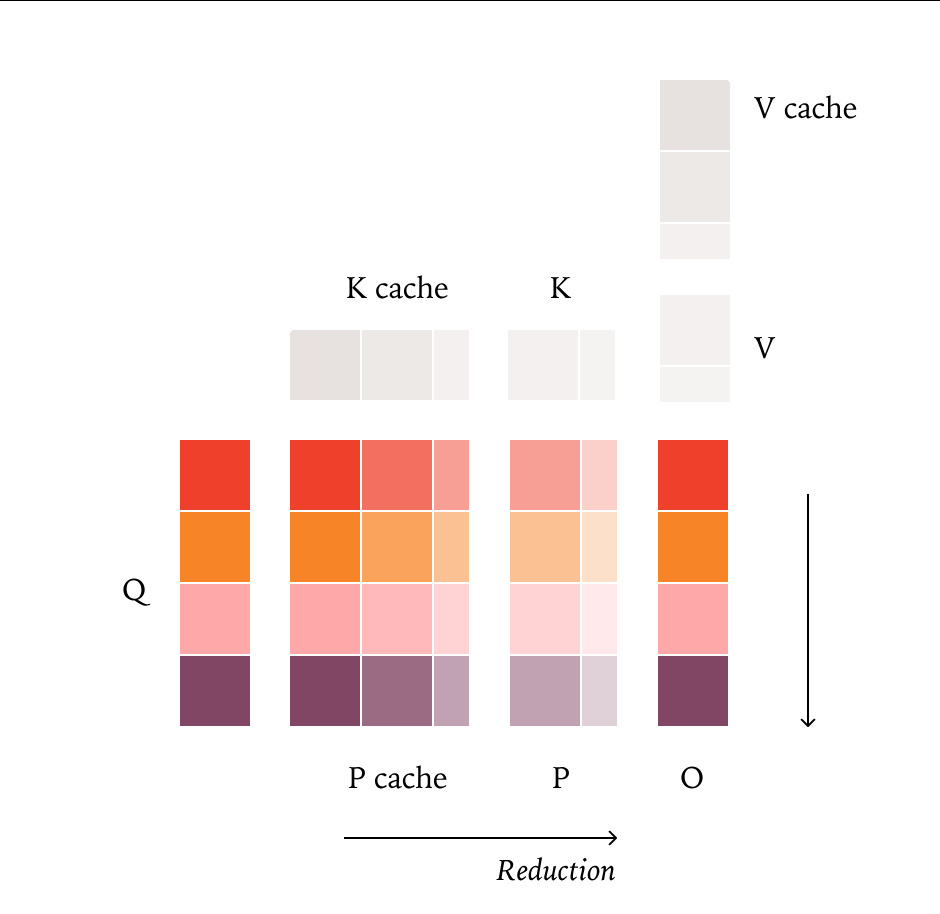
实验部分,研究团队选用 Qwen3-235B-A22B-Instruct-2507 模型进行测试。在应用上述优化后,连续运行 1000 次相同请求,模型每次输出均完全一致,实现了真正意义上的确定性推理。
终于介绍完啦!小伙伴们,这篇关于《ThinkingMachinesLab揭示LLM推理真相》的介绍应该让你收获多多了吧!欢迎大家收藏或分享给更多需要学习的朋友吧~golang学习网公众号也会发布科技周边相关知识,快来关注吧!
-
501 收藏
-
501 收藏
-
501 收藏
-
501 收藏
-
501 收藏
-
198 收藏
-
424 收藏
-
科技周边 · 业界新闻 | 6天前 | github · 业界新闻 · 供应链安全 · 许可证合规 · GitHub 供应链安全 开源许可证合规 Dependency Review Ruleset 企业研发治理116 收藏
-
科技周边 · 业界新闻 | 6天前 | Google Cloud · 业界新闻 · 网络事件 · 云服务排查 · 云服务 Google Cloud 网络延迟 业界新闻 VPC Media CDN Hybrid Connectivity468 收藏
-
415 收藏
-
科技周边 · 业界新闻 | 1星期前 | css · 业界新闻 · Web平台 · Safari · 表单控件 · CSS select 前端表单 Safari 27 beta Customizable Select Web平台239 收藏
-
科技周边 · 业界新闻 | 2星期前 | gitHub actions · 业界新闻 · CI治理 · 供应链安全 GitHub Actions CI安全 工作流触发 pull_request_target419 收藏
-
107 收藏
-
414 收藏
-
375 收藏
-
134 收藏
-
430 收藏
-

- 前端进阶之JavaScript设计模式
- 设计模式是开发人员在软件开发过程中面临一般问题时的解决方案,代表了最佳的实践。本课程的主打内容包括JS常见设计模式以及具体应用场景,打造一站式知识长龙服务,适合有JS基础的同学学习。
- 立即学习 543次学习
-

- GO语言核心编程课程
- 本课程采用真实案例,全面具体可落地,从理论到实践,一步一步将GO核心编程技术、编程思想、底层实现融会贯通,使学习者贴近时代脉搏,做IT互联网时代的弄潮儿。
- 立即学习 516次学习
-

- 简单聊聊mysql8与网络通信
- 如有问题加微信:Le-studyg;在课程中,我们将首先介绍MySQL8的新特性,包括性能优化、安全增强、新数据类型等,帮助学生快速熟悉MySQL8的最新功能。接着,我们将深入解析MySQL的网络通信机制,包括协议、连接管理、数据传输等,让
- 立即学习 500次学习
-

- JavaScript正则表达式基础与实战
- 在任何一门编程语言中,正则表达式,都是一项重要的知识,它提供了高效的字符串匹配与捕获机制,可以极大的简化程序设计。
- 立即学习 487次学习
-

- 从零制作响应式网站—Grid布局
- 本系列教程将展示从零制作一个假想的网络科技公司官网,分为导航,轮播,关于我们,成功案例,服务流程,团队介绍,数据部分,公司动态,底部信息等内容区块。网站整体采用CSSGrid布局,支持响应式,有流畅过渡和展现动画。
- 立即学习 485次学习