蚂蚁千亿参数大模型Ming-flash-omni发布
时间:2025-10-29 14:33:32 351浏览 收藏
一分耕耘,一分收获!既然都打开这篇《蚂蚁发布千亿参数开源大模型 Ming-flash-omni》,就坚持看下去,学下去吧!本文主要会给大家讲到等等知识点,如果大家对本文有好的建议或者看到有不足之处,非常欢迎大家积极提出!在后续文章我会继续更新科技周边相关的内容,希望对大家都有所帮助!
蚂蚁百灵大模型团队近日正式推出了全新开源全模态大模型——Ming-flash-omni-Preview,标志着首个参数规模突破千亿的全模态模型正式向社区开放。该模型基于Ling 2.0的稀疏MoE架构构建,总参数量达103B,激活参数仅为9B,在保持高效推理的同时显著提升了多模态理解与生成能力。
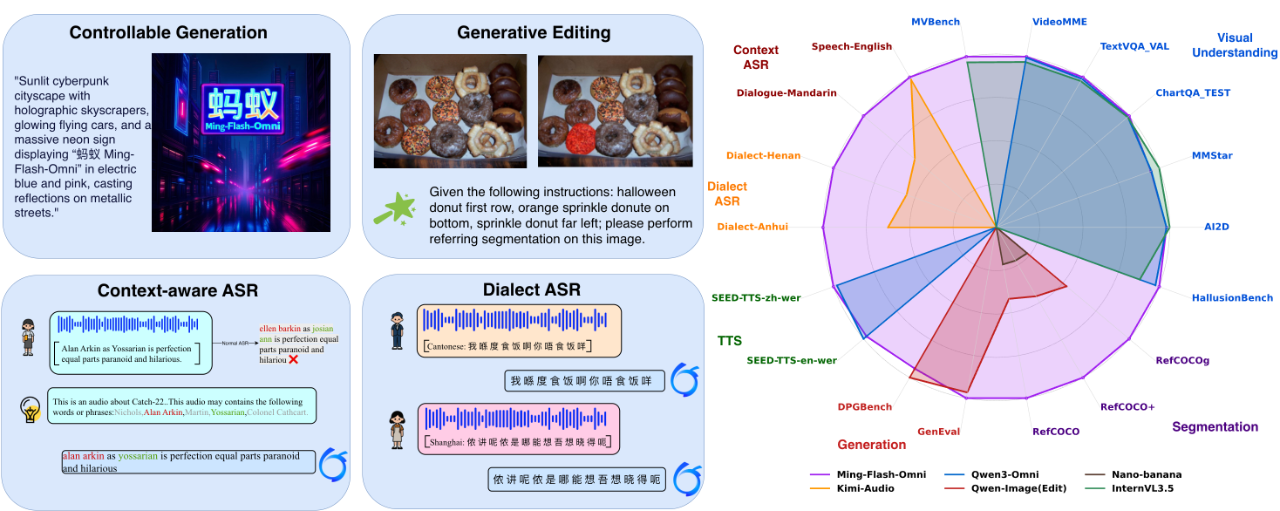
相较于此前广受好评的Ming-lite-omni-1.5,新模型在图像、视频、语音等多个模态任务中实现了全面升级,尤其在可控图像生成、流式视频理解和高精度语音识别方面表现突出,整体性能位居当前开源全模态模型前列。
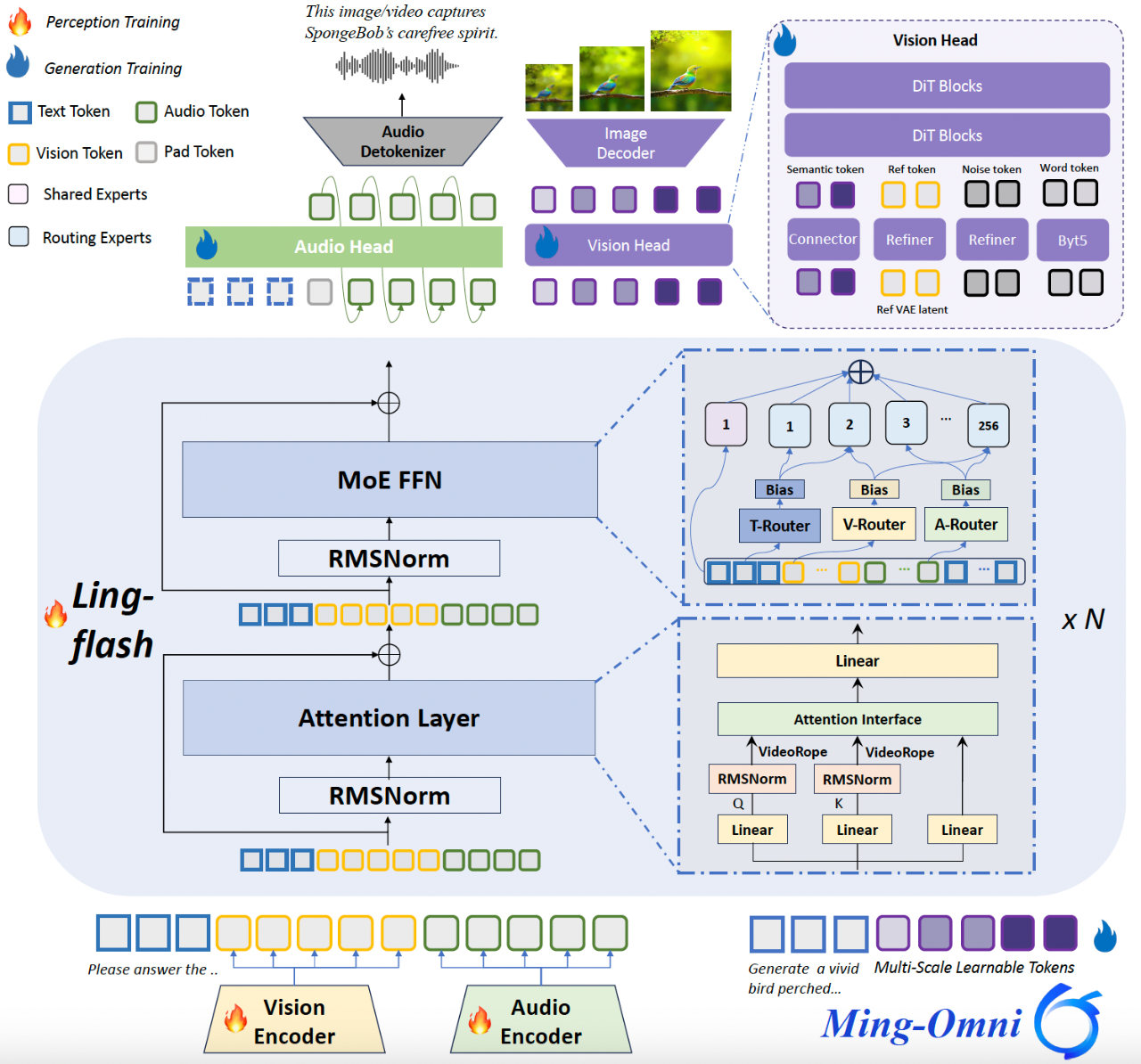
Ming-flash-omni-Preview 模型结构示意图:
据团队介绍,Ming-flash-omni-Preview 在技术层面进行了多项关键优化,主要体现在以下三个方面:
1) 基于稀疏专家架构的全模态协同训练
本模型将Ling-flash-2.0所采用的稀疏MoE架构成功扩展至全模态场景,并沿用Ming-lite-omni提出的模态级路由机制,实现对不同模态数据分布和专家分配策略的精准建模,达成“大容量、小激活”的高效运行模式。通过在注意力层引入VideoRoPE(Video Rotary Position Embedding),增强了对长时视频内容的时空建模能力,显著提升视频交互理解水平。
在训练稳定性方面,团队采用了混合式专家负载均衡方案:
- 结合辅助负载均衡损失函数与路由器偏置动态更新机制,确保各专家模块被均匀激活,保障稀疏训练过程中的收敛性;
- 针对语音识别任务,提出上下文感知ASR训练范式,以任务类型或领域信息作为解码条件输入,有效提升专有名词识别准确率及转录一致性;
- 同时引入涵盖湖南话、闽南话、粤语等在内的15种高质量中国方言语料,使方言识别性能获得显著增强。
2)生成式分割与编辑一体化训练范式
在统一多模态系统中,如何深度融合图像的理解与生成能力是一大核心挑战。虽然Ming-lite-omni-1.5通过冻结语言通路并引入多尺度QueryToken注入层级化语义,在一定程度上实现了理解与生成的融合,但由于两类任务目标本质差异,诸如物体属性、空间关系等细粒度视觉知识仍难以有效迁移至生成端,限制了生成质量与控制精度。
为此,Ming-flash-omni-Preview创新性地提出 “生成式分割即编辑”(Generative Segmentation as Editing) 的协同训练框架。该方法将传统图像分割任务重构为语义保持型编辑指令,例如:“把香蕉涂成紫色”。这一设计的关键优势在于:
- 强制统一理解与生成的目标函数:成功的编辑必须依赖对目标对象轮廓和语义的精确理解;
- 编辑结果的质量直接构成对理解能力的监督信号,形成闭环反馈;
- 显著增强模型在时空维度上的细粒度语义控制能力,间接缓解文本到图像生成中的组合性难题。
实验表明,在GenEval基准测试中,Ming-flash-omni-Preview取得0.90分的成绩,超越所有非强化学习(non-RL)方法;在GEdit基准上的精准编辑任务(如物体删除、替换)平均得分从6.9跃升至7.9。这些成果验证了该范式不仅提升了编辑能力,还能有效泛化至自由文本驱动的图像生成任务。
3) 高效全模态训练架构设计
全模态基础模型的训练常面临两大瓶颈:数据异构性(各模态序列长度不一)与模型异构性(专用编码器结构差异导致并行困难),易引发负载不均、内存碎片和流水线气泡,严重影响训练效率。
针对上述问题,团队基于Megatron-LM框架实施了两项关键技术改进:
- 序列打包(Sequence Packing):将多个变长多模态序列智能打包为固定长度批次,大幅提升内存利用率和计算密度;
- 弹性编码器分片(Flexible Encoder Sharding):扩展支持模态特定编码器在数据并行(DP)、管道并行(PP)和张量并行(TP)维度上的细粒度切分,消除流水线等待,实现真正的负载均衡。
这些优化使得Ming-flash-omni-Preview的训练吞吐量相比基线系统提升近一倍,大幅缩短了大规模全模态模型的迭代周期。
目前,Ming-flash-omni-Preview 的完整模型权重与训练代码已全面开源,欢迎开发者与研究者使用:
GitHub: https://github.com/inclusionAI/Ming
HuggingFace: https://huggingface.co/inclusionAI/Ming-flash-omni-Preview
ModelScope: https://www.modelscope.cn/models/inclusionAI/Ming-flash-omni-Preview
到这里,我们也就讲完了《蚂蚁千亿参数大模型Ming-flash-omni发布》的内容了。个人认为,基础知识的学习和巩固,是为了更好的将其运用到项目中,欢迎关注golang学习网公众号,带你了解更多关于的知识点!
-
501 收藏
-
501 收藏
-
501 收藏
-
501 收藏
-
501 收藏
-

- 前端进阶之JavaScript设计模式
- 设计模式是开发人员在软件开发过程中面临一般问题时的解决方案,代表了最佳的实践。本课程的主打内容包括JS常见设计模式以及具体应用场景,打造一站式知识长龙服务,适合有JS基础的同学学习。
- 立即学习 543次学习
-

- GO语言核心编程课程
- 本课程采用真实案例,全面具体可落地,从理论到实践,一步一步将GO核心编程技术、编程思想、底层实现融会贯通,使学习者贴近时代脉搏,做IT互联网时代的弄潮儿。
- 立即学习 516次学习
-

- 简单聊聊mysql8与网络通信
- 如有问题加微信:Le-studyg;在课程中,我们将首先介绍MySQL8的新特性,包括性能优化、安全增强、新数据类型等,帮助学生快速熟悉MySQL8的最新功能。接着,我们将深入解析MySQL的网络通信机制,包括协议、连接管理、数据传输等,让
- 立即学习 500次学习
-

- JavaScript正则表达式基础与实战
- 在任何一门编程语言中,正则表达式,都是一项重要的知识,它提供了高效的字符串匹配与捕获机制,可以极大的简化程序设计。
- 立即学习 487次学习
-

- 从零制作响应式网站—Grid布局
- 本系列教程将展示从零制作一个假想的网络科技公司官网,分为导航,轮播,关于我们,成功案例,服务流程,团队介绍,数据部分,公司动态,底部信息等内容区块。网站整体采用CSSGrid布局,支持响应式,有流畅过渡和展现动画。
- 立即学习 485次学习