Redis实现分布式锁详解
来源:脚本之家
时间:2023-05-13 08:47:19 152浏览 收藏
“纵有疾风来,人生不言弃”,这句话送给正在学习数据库的朋友们,也希望在阅读本文《Redis实现分布式锁详解》后,能够真的帮助到大家。我也会在后续的文章中,陆续更新数据库相关的技术文章,有好的建议欢迎大家在评论留言,非常感谢!
一、前言
为什么需要分布式锁?
在我们的日常开发中,一个进程中当多线程的去竞争某一资源的时候,我们通常会用一把锁来保证只有一个线程获取到资源。如加上synchronize关键字或ReentrantLock锁等操作。
那么,如果是多个进程相互竞争一个资源,如何保证资源只会被一个操作者持有呢?
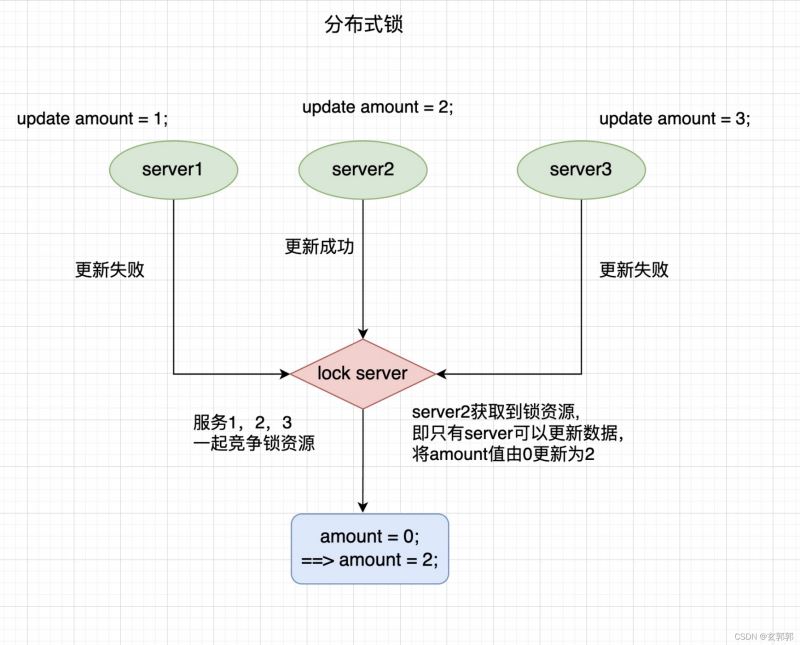
例如:微服务的架构下,多个应用服务要同时对同一条数据做修改,那么要确保数据的正确性,就只能有一个应用修改成功。
server1、server2、server3 这三个服务都要修改amount这个数据,每个服务更新的值不同,为了保证数据的正确性,三个服务都向lock server服务申请修改权限,最终server2拿到了修改权限,即server2将amount更新为2,其他服务由于没有获取到修改权限则返回更新失败。
二、基于redis实现分布式锁
为什么redis可以实现分布式锁?
因为redis是一个单独的非业务服务,不会受到其他业务服务的限制,所有的业务服务都可以向redis发送写入命令,且只有一个业务服务可以写入命令成功,那么这个写入命令成功的服务即获得了锁,可以进行后续对资源的操作,其他未写入成功的服务,则进行其他处理。
如何实现?
redis的String类型就可以实现。
锁的获取
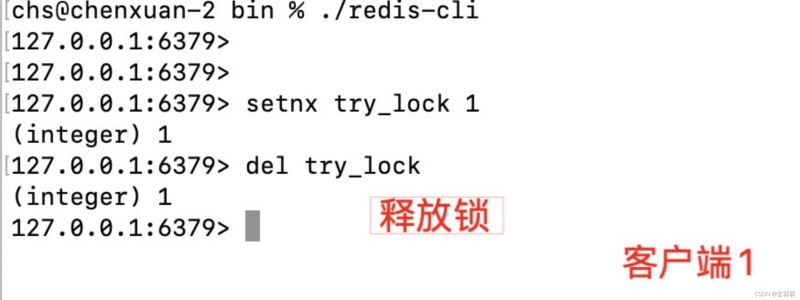
setnx命令:表示SET if Not eXists,即如果 key 不存在,才会设置它的值,否则什么也不做。
两个客户端同时向redis写入try_lock,客户端1写入成功,即获取分布式锁成功。客户端2写入失败,则获取分布式锁失败。


锁的释放
当客户端1操作完后,释放锁资源,即删除try_lock。那么此时客户端2再次尝试获取锁时,则会获取锁成功。

那么这样分布式锁就这样结束了?不不不,现实往往有很多情况出现。
假如客户端1在获取到锁资源后,服务宕机了,那么这个try_lock会一直存在redis中,那么其他服务就永远无法获取到锁了。
如何解决这个问题呢?
三、如何避免死锁?锁的过期时间如何设置?
避免死锁
设置键过期时间,超过这个时间即给key删除掉。
这样的话,就算当前服务获取到锁后宕机了,这个key也会在一定时间后被删除,其他服务照样可以继续获取锁。
给serverLock键设置一个10秒的过期时间,10秒后会自动删除该键。

这样虽然解决了上面说的问题,但是又会引入新的问题。
假如服务A加锁成功,锁会在10s后自动释放,但由于业务复杂,执行时间过长,10s内还没执行完,此时锁已经被redis自动释放掉了。此时服务B就重新获取到了该锁,服务B开始执行他的业务,服务A在执行到第12s的时候执行完了,那么服务A会去释放锁,则此时释放的却是服务B刚获取到的锁。
这会有锁过期和释放其他服务锁这种严重的问题。
锁过期处理
那么锁过期这种问题该如何处理的?
虽然可以通过增加删除key时间来处理这个问题,但是并没有从根本上解决。假设设个100s,绝大多数都是1s后就会释放锁,但是由于服务宕机,则会导致100s内其他服务都无法获取到锁,这也是灾难性的。
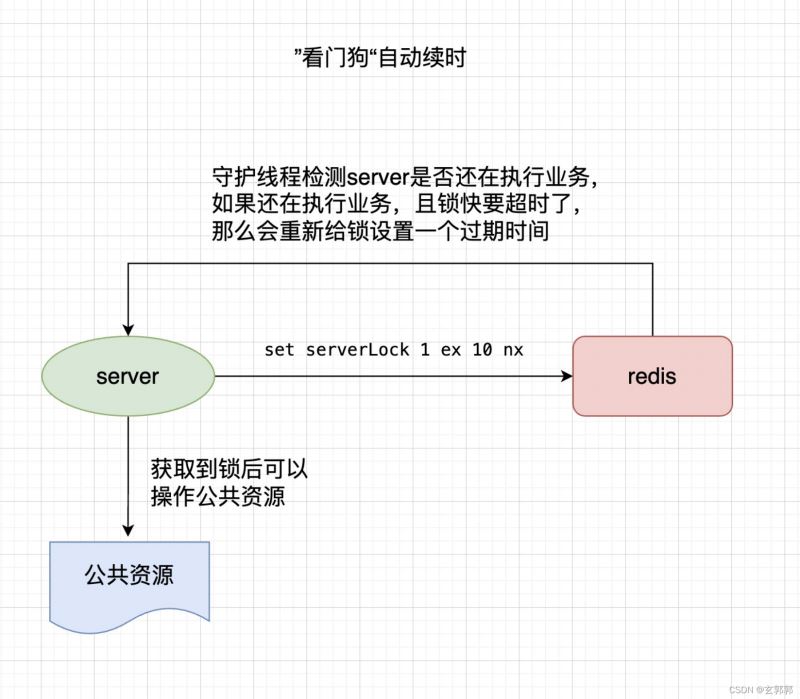
我们可以这样做,在锁将要过期的时候,如果服务还没有处理完业务,那么将这个锁再续一段时间。比如设置key在10s后过期,那么再开启一个守护线程,在第8s的时候检测服务是否处理完,如果没有,则将这个key再续10s后过期。
在Redisson(Redis SDK客户端)中,就已经帮我们实现了这个功能,这个自动续时的我们称其为”看门狗”。
释放其他服务的锁如何处理呢?
每个服务在设置value的时候,带上自己服务的唯一标识,如UUID,或者一些业务上的独特标识。这样在删除key的时候,只删除自己服务之前添加的key就可以了。
如果需要先查看锁是否是自己服务添加的,需要先get取出来判断,然后再进行del。这样的话就无法保证原子性了。
我们可以通过Lua脚本,将这两个操作合并成一个操作,就可以保证其原子性了。
Lua脚本的话,我也不会,用到的时候百度就完了。
如果是在单redis实例的情况下,上面的已经完全实现了分布式锁的功能了。
那么redis宕机了呢?
这个时候就得引入redis集群了。
但是涉及到redis集群,就会有新的问题出现,假设是主从集群,且主从数据并不是强一致性。当主节点宕机后,主节点的数据还未来得及同步到从节点,进行主从切换后,新的主节点并没有老的主节点的全部数据,这就会导致刚写入到老的主节点的锁在新的主节点并没有,其他服务来获取锁时还是会加锁成功。此时则会有2个服务都可以操作公共资源,此时的分布式锁则是不安全的。
redis的作者也想到这个问题,于是他发明了RedLock。
四、RedLock
什么是RedLock?
要实现RedLock,需要至少5个实例(官方推荐),且每个实例都是master,不需要从库和哨兵。
实现流程
1、客户端先获取当前时间戳T1
2、客户端依次向5个master实例发起加锁命令,且每个请求都会设置超时时间(毫秒级,注意:不是锁的超时时间),如果某一个master实例由于网络等原因导致加锁失败,则立即想下一个master实例申请加锁。
3、当客户端加锁成功的请求大于等于3个时,且再次获取当前时间戳T2,
当时间戳T2 - 时间戳T1
4、加锁成功,开始操作公共资源,进行后续业务操作
5、加锁失败,向所有redis节点发送锁释放命令
即当客户端在大多数redis实例上申请加锁成功后,且加锁总耗时小于锁过期时间,则认为加锁成功。
释放锁需要向全部节点发送锁释放命令。
第3步为啥要计算申请锁前后的总耗时与锁释放时间进行对比呢?
因为如果申请锁的总耗时已经超过了锁释放时间,那么可能前面申请redis的锁已经被释放掉了,保证不了大于等于3个实例都有锁存在了,锁也就没有意义了
这样的话分布式锁就真的没问题了嘛?
1、得5个redis实例,成本大大增加
2、可以通过上面的流程感受到,这个RedLock锁太重了
3、主从切换这种场景绝大多数的时候不会碰到,偶尔碰到的话,保证最终的兜底操作我觉得也没啥问题。
4、分布式系统中的NPC问题
分布式系统中的NPC问题
(可不是游戏里的NPC提问哦)
N:Network Delay,网络延迟
P:Process Pause,进程暂停(GC)
C:Clock Drift,时钟漂移
举个例子吧:
1、客户端 1 请求锁定节点 A、B、C、D、E
2、客户端 1 的拿到锁后,进入 GC(时间比较久)
3、所有 Redis 节点上的锁都过期了
4、客户端 2 获取到了 A、B、C、D、E 上的锁
5、客户端 1 GC 结束,认为成功获取锁
6、客户端 2 也认为获取到了锁,发生【冲突】
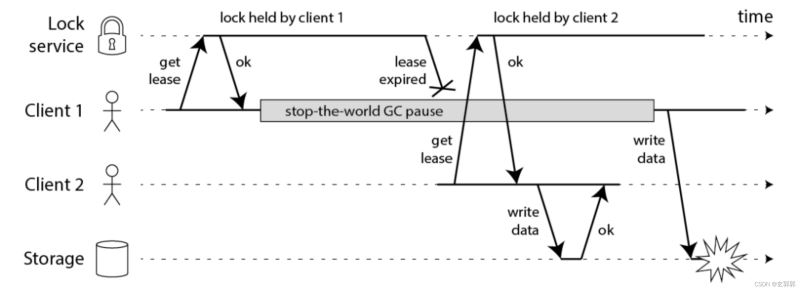
在第2步已经成功获取到锁后,由于GC时间超过锁过期时间,导致GC完成后其他客户端也能够获取到锁,此时2个客户端都会持有锁。就会有问题。
这个问题无论是redlock还是zookeeper都会有这种问题。不做业务上的兜底操作就没得解。
时钟漂移问题也只能是尽量避免吧。无法做到根本解决。
个人思考
用RedLock觉得性价比很低。原因如下
1、得额外的多台服务器部署redis,每台服务器可都是钱啊,而且部署和运维的成本也增加了。
2、用RedLock感觉太重了,效率会很低,既然用了redis,就是为了提升效率,结果一个锁大大降低了效率
3、如果在集群情况下有锁丢失的情况,我们业务上做好兜底操作就可以了,可以不用上RedLock。
4、毕竟集群情况下主从切换的场景还是极少的,为了极少的情况去浪费大量的性能,感觉划不来
5、就算是上了RedLock,也是避免不了NPC问题的,还不是得业务上做兜底。
聊了这么多的redis实现分布式锁。也简单了解下zookeeper是如何实现分布式锁的吧。
五、基于zookeeper实现分布式锁
什么是zookeeper(zk)?
zk是一个分布式协调服务,功能包括:配置维护、域名服务、分布式同步、组服务等。
zk的数据结构跟Unix文件系统类似。是一颗树形结构,这里不做详细介绍。
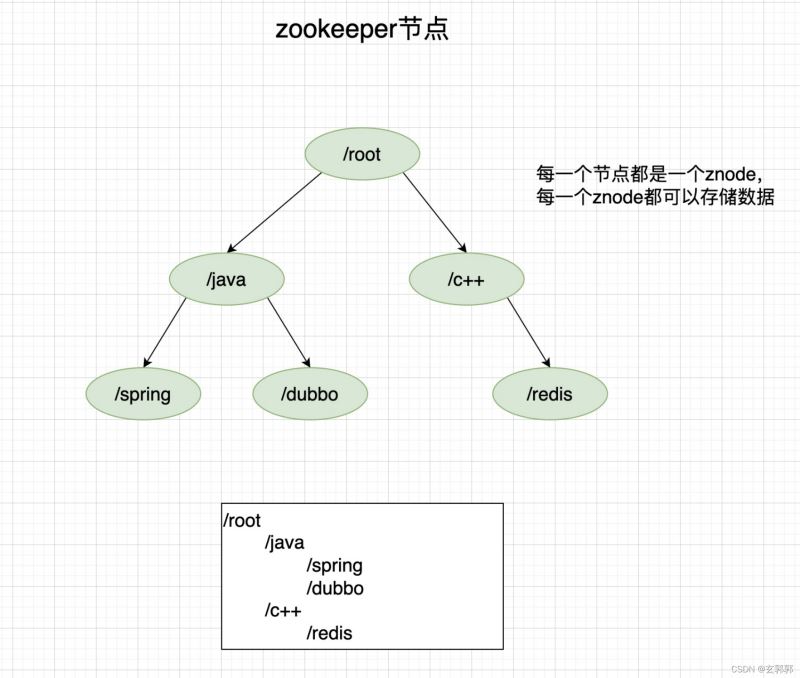
zookeeper节点介绍
zk的节点称之为znode节点,znode节点分两种类型:
1、临时节点(Ephemeral):当客户端与服务器断开连接后,临时znode节点就会被自动删除
2、持久节点(Persistent):当客户端与服务器断开连接后,持久znode节点不会被自动删除
znode节点还有一些特性:
1、节点有序:在一个父节点下创建子节点,zk提供了一个可选的有序性,创建子节点时会根据当前子节点数量给节点名添加序号。例:/root下创建/java,生成的节点名称则为java0001,/root/java0001。
2、临时节点:当会话结束或超时,自动删除节点
3、事件监听:当节点有创建,删除,数据修改,子节点变更的时候,zk会通知客户端的。
zookeeper分布式锁的实现
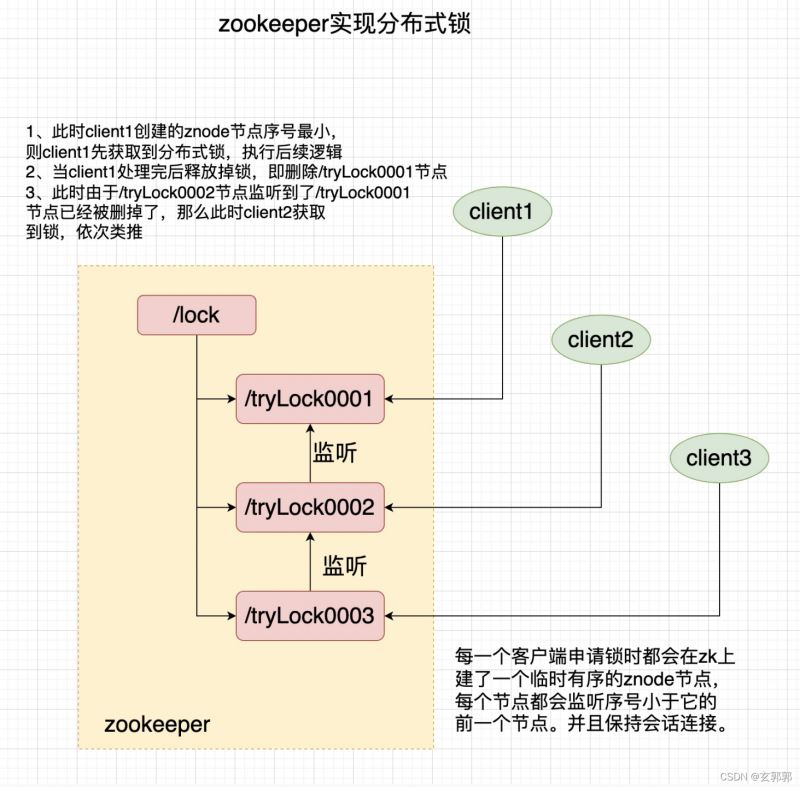
zookeeper就是通过临时节点和节点有序来实现分布式锁的。
1、每个获取锁的线程会在zk的某一个目录下创建一个临时有序的节点。
2、节点创建成功后,判断当前线程创建的节点的序号是否是最小的。
3、如果序号是最小的,那么获取锁成功。
4、如果序号不是最小的,则对他序号的前一个节点添加事件监听。如果前一个节点被删了(锁被释放了),那么就会唤醒当前节点,则成功获取到锁。
六、zookeepe和redisr两者的优缺
zookeeper
优点:
1、不用设置过期时间
2、事件监听机制,加锁失败后,可以等待锁释放
缺点:
1、性能不如redis
2、当网络不稳定时,可能会有多个节点同时获取锁问题。例:node1由于网络波动,导致zk将其删除,刚好node2获取到锁,那么此时node1和node2两者都会获取到锁。
Redis
优点:性能上比较好,天然的支持高并发
缺点:
1、获取锁失败后,得轮询的去获取锁
2、大多数情况下redis无法保证数据强一致性
七、那么实际的工作中,该如何选择呢?
比如我来说,很简单,没得选,就Redis,为啥?因为公司没有用zk。
具体如何选择,还是得看公司是否有使用相应的中间件。
如果两种公司都有使用,那就具体的看业务场景了,看是基于性能考虑还是其他方面的考虑。
如果用redis的话,个人觉得没必要上RedLock,感觉性价比太低。
但是要注意的是,无论哪一种,在极端的情况下,都会有锁失效或锁冲突的情况出现,因此业务上,设计上要有兜底的方案,不要造成不必要的损失。
本文中没有通过代码来实现分布式锁,只是提供了方向和思路,以及要注意的地方。至于具体如何通过代码实现,Java的话有Redisson封装好了大部分功能,使用起来也比较简单,大家可以参考相应的文档即可。
今天关于《Redis实现分布式锁详解》的内容介绍就到此结束,如果有什么疑问或者建议,可以在golang学习网公众号下多多回复交流;文中若有不正之处,也希望回复留言以告知!
-
130 收藏
-
178 收藏
-
355 收藏
-
316 收藏
-
361 收藏
-
数据库 · Redis | 1天前 | Redis · 安全配置 · 数据库运维 · ACL · 网络隔离 · Redis公网暴露 Redis protected-mode Redis ACL Redis安全配置 Redis审计364 收藏
-
250 收藏
-
110 收藏
-
366 收藏
-
449 收藏
-
441 收藏
-
119 收藏
-
280 收藏
-
数据库 · Redis | 2星期前 | Redis · 缓存治理 · Keyspace Notifications · 过期事件 · redis Pub/Sub Keyspace Notifications 过期事件 缓存监听 补偿任务181 收藏
-
501 收藏
-
400 收藏
-
313 收藏
-

- 前端进阶之JavaScript设计模式
- 设计模式是开发人员在软件开发过程中面临一般问题时的解决方案,代表了最佳的实践。本课程的主打内容包括JS常见设计模式以及具体应用场景,打造一站式知识长龙服务,适合有JS基础的同学学习。
- 立即学习 543次学习
-

- GO语言核心编程课程
- 本课程采用真实案例,全面具体可落地,从理论到实践,一步一步将GO核心编程技术、编程思想、底层实现融会贯通,使学习者贴近时代脉搏,做IT互联网时代的弄潮儿。
- 立即学习 516次学习
-

- 简单聊聊mysql8与网络通信
- 如有问题加微信:Le-studyg;在课程中,我们将首先介绍MySQL8的新特性,包括性能优化、安全增强、新数据类型等,帮助学生快速熟悉MySQL8的最新功能。接着,我们将深入解析MySQL的网络通信机制,包括协议、连接管理、数据传输等,让
- 立即学习 500次学习
-

- JavaScript正则表达式基础与实战
- 在任何一门编程语言中,正则表达式,都是一项重要的知识,它提供了高效的字符串匹配与捕获机制,可以极大的简化程序设计。
- 立即学习 487次学习
-

- 从零制作响应式网站—Grid布局
- 本系列教程将展示从零制作一个假想的网络科技公司官网,分为导航,轮播,关于我们,成功案例,服务流程,团队介绍,数据部分,公司动态,底部信息等内容区块。网站整体采用CSSGrid布局,支持响应式,有流畅过渡和展现动画。
- 立即学习 485次学习