一文详解kubernetes 中资源分配的那些事
来源:脚本之家
时间:2023-05-12 18:24:38 161浏览 收藏
学习Golang要努力,但是不要急!今天的这篇文章《一文详解kubernetes 中资源分配的那些事》将会介绍到分配、kubernetes资源等等知识点,如果你想深入学习Golang,可以关注我!我会持续更新相关文章的,希望对大家都能有所帮助!
概要
在k8s中,kube-scheduler是Kubernetes中的调度器,用于将Pod调度到可用的节点上。在调度过程中,kube-scheduler需要了解节点和Pod的资源需求和可用性情况,其中CPU和内存是最常见的资源需求。那么这些资源的使用率是怎么来的呢?当Pod调度到节点上后,系统是如何约束Pod的资源使用而不影响其他Pod的?当资源使用率达到了申请的资源时,会发生什么?下面,我们就这些问题,详细展开说说。阅读本文,你将了解到
- k8s调度Pod时,节点的资源使用率是怎么来的
- k8s中配置的cpu的limit, request在节点上具体是通过什么参数来约束Pod的资源使用的
- 什么是empheral-storage资源,有什么用
- kubelet配置中关于资源管理的那些参数该怎么配置
用过k8s的同学应该都知道,我们在配置deployment的时候,我们一般都会为cpu和内存配置limit和request,那么这个配置具体在节点上是怎么限制的呢?
一个nginx的配置
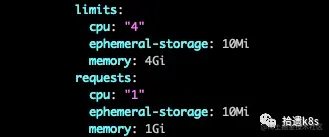
cpu的request、limit分别是1个核和4个核,内存的request、limit分别是1Gi和4Gi(Gi=1024Mi,G=1000Mi)。我们都知道,资源的限制时使用cgroup实现的,那么Pod的资源是怎么实现的呢?我们去Pod所在的节点看下。
k8s的cpu限制的cgroup目录在 /sys/fs/cgroup/cpu/kubepods ,该目录内容如下
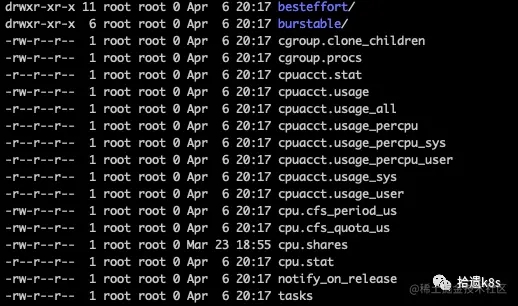
我们能看到besteffort 和 burstable两个目录,这两个目录涉及Pod的QoS
QoS(Quality of Service),大部分译为“服务质量等级”,又译作“服务质量保证”,是作用在 Pod 上的一个配置,当 Kubernetes 创建一个 Pod 时,它就会给这个 Pod 分配一个 QoS 等级,可以是以下等级之一:
- Guaranteed:Pod 里的每个容器都必须有内存/CPU 限制和请求,而且值必须相等。
- Burstable:Pod 里至少有一个容器有内存或者 CPU 请求且不满足 Guarantee 等级的要求,即内存/CPU 的值设置的不同。
- BestEffort:容器必须没有任何内存或者 CPU 的限制或请求。
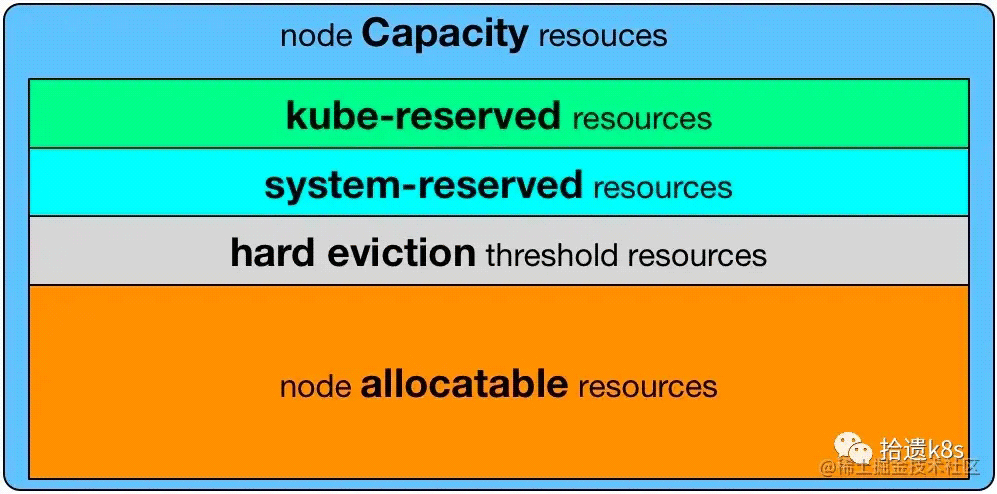
这个东西的作用就是,当节点上出现资源压力的时候,会根据QoS的等级顺序进行驱逐,驱逐顺序为Guaranteed 我们的nginx对资源要求的配置根据上面的描述可以看到是Burstable类型的 我们进该目录看下: 里面的目录表示属于Burstable类型的Pod的cpu cgroup都配置在这个目录,再进到Pod所在目录,可以看到有2个目录,每个目录是容器的cpu cgroup目录,一个是nginx本身的,另外一个Infra容器(沙箱容器)。 我们重点看下红框内的三个文件的含义。 cpu.shares用来设置CPU的相对值,并且是针对所有的CPU(内核),默认值是1024等同于一个cpu核心。 CPU Shares将每个核心划分为1024个片,并保证每个进程将按比例获得这些片的份额。如果有1024个片(即1核),并且两个进程设置cpu.shares均为1024,那么这两个进程中每个进程将获得大约一半的cpu可用时间。 当系统中有两个cgroup,分别是A和B,A的shares值是1024,B 的shares值是512, 那么A将获得1024/(1024+512)=66%的CPU资源,而B将获得33%的CPU资源。shares有两个特点: 如果A不忙,没有使用到66%的CPU时间,那么剩余的CPU时间将会被系统分配给B,即B的CPU使用率可以超过33%。 如果添加了一个新的cgroup C,且它的shares值是1024,那么A的限额变成了1024/(1024+512+1024)=40%,B的变成了20%。 从上面两个特点可以看出: 在闲的时候,shares不起作用,只有在CPU忙的时候起作用。 由于shares是一个绝对值,单单看某个组的share是没有意义的,需要和其它cgroup的值进行比较才能得到自己的相对限额,而在一个部署很多容器的机器上,cgroup的数量是变化的,所以这个限额也是变化的,自己设置了一个高的值,但别人可能设置了一个更高的值,所以这个功能没法精确的控制CPU使用率。从share这个单词(共享的意思)的意思,我们也能够体会到这一点。 cpu.shares对应k8s内的resources.requests.cpu字段,值对应关系为:resources.requests.cpu * 1024 = cpu.share cpu.cfs_period_us用来配置时间周期长度,cpu.cfs_quota_us用来配置当前cgroup在设置的周期长度内所能使用的CPU时间数。 两个文件配合起来设置CPU的使用上限。两个文件的单位都是微秒(us),cfs_period_us的取值范围为1毫秒(ms)到1秒(s),cfs_quota_us的取值大于1ms即可,如果cfs_quota_us的值为-1(默认值),表示不受cpu时间的限制。 cpu.cpu.cfs_period_us、cpu.cfs_quota_us对应k8s中的resources.limits.cpu字段:resources.limits.cpu = cpu.cfs_quota_us/cpu.cfs_period_us 可以看到上面的nginx的这两个比值正好是4,表示nginx最多可以分配到4个CPU。此时,就算系统很空闲,上面说的share没有发挥作用,也不会分配超时4个CPU,这就是上限的限制。 在平时配置的时候,limit和request两者最好不要相差过大,否则节点CPU容易出现超卖情况,如limit/request=4,那么在调度的时候发现节点是有资源的,一旦调度完成后,Pod可能会由于跑出超过request的CPU,那么节点其他Pod可能就会出现资源”饥饿“情况,反映到业务就是请求反应慢。CPU 属于可压缩资源,内存属于不可压缩资源。当可压缩资源不足时,Pod 会饥饿,但是不会退出;当不可压缩资源不足时,Pod 就会因为 OOM 被内核杀掉。 这个问题还得从源码入手,首先我们看看kube-scheduler在调度的时候对于资源的判断都做了哪些事。kube-scheduler会使用informer监听集群内node的变化,如果有变化(如Node的状态,Node的资源情况等),则调用事件函数写入本地index store(cache)中,代码如下: 如上,如果集群内加入了新节点,则会调用addNodeToCache函数将Node信息加入本地缓存,那么咱们来看看addNodeToCache函数: 从上面的代码我们看到,在把该节点加入cache后,还会调用MoveAllToActiveOrBackoffQueue 函数,对在 unschedulablePods (还没有调度的Pod队列)中的Pod进行一次Precheck ,如果MoveAllToActiveOrBackoffQueue** 函数如下 如果上述的Precheck通过后,则会把Pod移到相应的队列等待下一次调度。这里的重点来了,本文是讲关于资源相关的,那么Precheck中到底做了什么检查呢? preCheckForNode 调用了AdmissionCheck,在AdmissionCheck中分别做了资源检查、亲和性检查、nodeName检查、端口检查。这里我们只关注资源的检查 fitsRequest 首先会调用computePodResourceRequest函数计算出这个Pod需要多少资源,然后跟目前节点还能分配的资源做比较,如果还能够分配出资源,那么针对于资源检查这一项就通过了。如果Precheck所有项都能通过,那么该Pod会被放入active队列,该队列里的Pod就会被kube-scheduler取出做调度。前面所说的目前节点资源情况是从哪里来的呢?kubelet会定期(或者node发生变化)上报心跳到Kube-apiserver,因为kube-scheduler监听了node的变化,所以能感知到节点的资源使用情况。 当Kube-scheduler从队列取到Pod后,会进行一系列的判断(如PreFilter),还会涉及资源的检查,这个资源使用情况也是kubelet上报的。 当我们describe 一个node的时候,可以看到能够显示资源allocatable的信息,那这个信息就是实时的资源使用情况吗?答案是否定的,我们看下 注:本机是64U256G的机器 其中capacity是本机的硬件一共可以提供的资源,allocatable是可以分配的,那么为什么allocatable为什么会和capacity不一样呢?这里就涉及到了预留资源和驱逐相关内容 systemReserved, kubeReserved分别 *表示预留给操作系统和kubernetes组件的资源,kubelet在上报可用资源的时候需要减去这部分资源;evictionHard表示资源只剩下这么多的时候,就会启动Pod的驱逐,所以这部分资源也不能算在可分配里面的。这么算起来,上面的capacity减去上述三者相加正好是allocatable的值,也就是该节点实际可分配的资源。他们的关系可以用下图表示 但是这里有个值得注意的点,上面通过describe出来的allocatable的值是一个静态的值,表示该节点总共可以分配多少资源,而不是此时此刻节点可以分配多少资源,kube-scheduler依据Kubelet动态上报的数据来判断某个节点是否能够调度。 还需要注意,要使systemReserved, kubeReserved配置的资源不算在可分配的资源里面,还需要配置如下配置: 到这里,我们就简单讲了scheduler是如何在调度的时候,在资源层面是如何判断的。当然了,上面只简单讲了调度的时候pod被移到可调度队列的情况,后面还有prefilter、filter、score等步骤,但是这些步骤在判断资源情况时,跟上面是一样的。 到这里,我们也就讲完了《一文详解kubernetes 中资源分配的那些事》的内容了。个人认为,基础知识的学习和巩固,是为了更好的将其运用到项目中,欢迎关注golang学习网公众号,带你了解更多关于golang的知识点!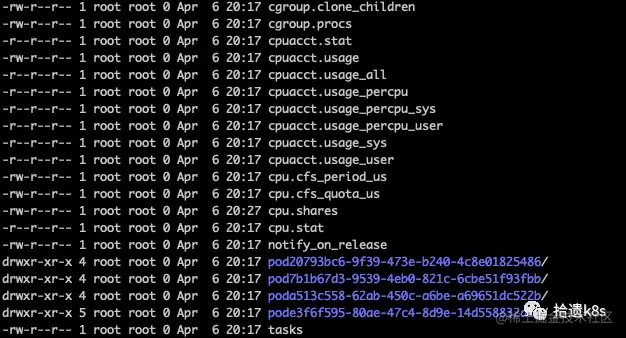
我们进入nginx容器所在目录看下
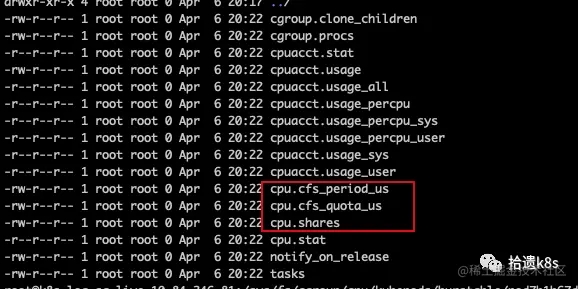
cpu.shares
cpu.cpu.cfs_period_us、cpu.cfs_quota_us

资源使用率数据来源
func addAllEventHandlers{
...
informerFactory.Core().V1().Nodes().Informer().AddEventHandler(
cache.ResourceEventHandlerFuncs{
AddFunc: sched.addNodeToCache,
UpdateFunc: sched.updateNodeInCache,
DeleteFunc: sched.deleteNodeFromCache,
},
)
...
func (sched *Scheduler) addNodeToCache(obj interface{}) {
node, ok := obj.(*v1.Node)
if !ok {
klog.ErrorS(nil, "Cannot convert to *v1.Node", "obj", obj)
return
}
nodeInfo := sched.Cache.AddNode(node)
klog.V(3).InfoS("Add event for node", "node", klog.KObj(node))
sched.SchedulingQueue.MoveAllToActiveOrBackoffQueue(queue.NodeAdd, preCheckForNode(nodeInfo))
}
func (p *PriorityQueue) MoveAllToActiveOrBackoffQueue(event framework.ClusterEvent, preCheck PreEnqueueCheck) {
p.lock.Lock()
defer p.lock.Unlock()
unschedulablePods := make([]*framework.QueuedPodInfo, 0, len(p.unschedulablePods.podInfoMap))
for _, pInfo := range p.unschedulablePods.podInfoMap {
if preCheck == nil || preCheck(pInfo.Pod) {
unschedulablePods = append(unschedulablePods, pInfo)
}
}
p.movePodsToActiveOrBackoffQueue(unschedulablePods, event)
}
func preCheckForNode(nodeInfo *framework.NodeInfo) queue.PreEnqueueCheck {
// Note: the following checks doesn't take preemption into considerations, in very rare
// cases (e.g., node resizing), "pod" may still fail a check but preemption helps. We deliberately
// chose to ignore those cases as unschedulable pods will be re-queued eventually.
return func(pod *v1.Pod) bool {
admissionResults := AdmissionCheck(pod, nodeInfo, false)
if len(admissionResults) != 0 {
return false
}
_, isUntolerated := corev1helpers.FindMatchingUntoleratedTaint(nodeInfo.Node().Spec.Taints, pod.Spec.Tolerations, func(t *v1.Taint) bool {
return t.Effect == v1.TaintEffectNoSchedule
})
return !isUntolerated
}
}
func AdmissionCheck(pod *v1.Pod, nodeInfo *framework.NodeInfo, includeAllFailures bool) []AdmissionResult {
var admissionResults []AdmissionResult
insufficientResources := noderesources.Fits(pod, nodeInfo)
if len(insufficientResources) != 0 {
for i := range insufficientResources {
admissionResults = append(admissionResults, AdmissionResult{InsufficientResource: &insufficientResources[i]})
}
if !includeAllFailures {
return admissionResults
}
}
if matches, _ := corev1nodeaffinity.GetRequiredNodeAffinity(pod).Match(nodeInfo.Node()); !matches {
admissionResults = append(admissionResults, AdmissionResult{Name: nodeaffinity.Name, Reason: nodeaffinity.ErrReasonPod})
if !includeAllFailures {
return admissionResults
}
}
if !nodename.Fits(pod, nodeInfo) {
admissionResults = append(admissionResults, AdmissionResult{Name: nodename.Name, Reason: nodename.ErrReason})
if !includeAllFailures {
return admissionResults
}
}
if !nodeports.Fits(pod, nodeInfo) {
admissionResults = append(admissionResults, AdmissionResult{Name: nodeports.Name, Reason: nodeports.ErrReason})
if !includeAllFailures {
return admissionResults
}
}
return admissionResults
}
func Fits(pod *v1.Pod, nodeInfo *framework.NodeInfo) []InsufficientResource {
return fitsRequest(computePodResourceRequest(pod), nodeInfo, nil, nil)
}
func fitsRequest(podRequest *preFilterState, nodeInfo *framework.NodeInfo, ignoredExtendedResources, ignoredResourceGroups sets.String) []InsufficientResource {
insufficientResources := make([]InsufficientResource, 0, 4)
allowedPodNumber := nodeInfo.Allocatable.AllowedPodNumber
if len(nodeInfo.Pods)+1 > allowedPodNumber {
insufficientResources = append(insufficientResources, InsufficientResource{
ResourceName: v1.ResourcePods,
Reason: "Too many pods",
Requested: 1,
Used: int64(len(nodeInfo.Pods)),
Capacity: int64(allowedPodNumber),
})
}
if podRequest.MilliCPU == 0 &&
podRequest.Memory == 0 &&
podRequest.EphemeralStorage == 0 &&
len(podRequest.ScalarResources) == 0 {
return insufficientResources
}
if podRequest.MilliCPU > (nodeInfo.Allocatable.MilliCPU - nodeInfo.Requested.MilliCPU) {
insufficientResources = append(insufficientResources, InsufficientResource{
ResourceName: v1.ResourceCPU,
Reason: "Insufficient cpu",
Requested: podRequest.MilliCPU,
Used: nodeInfo.Requested.MilliCPU,
Capacity: nodeInfo.Allocatable.MilliCPU,
})
}
if podRequest.Memory > (nodeInfo.Allocatable.Memory - nodeInfo.Requested.Memory) {
insufficientResources = append(insufficientResources, InsufficientResource{
ResourceName: v1.ResourceMemory,
Reason: "Insufficient memory",
Requested: podRequest.Memory,
Used: nodeInfo.Requested.Memory,
Capacity: nodeInfo.Allocatable.Memory,
})
}
if podRequest.EphemeralStorage > (nodeInfo.Allocatable.EphemeralStorage - nodeInfo.Requested.EphemeralStorage) {
insufficientResources = append(insufficientResources, InsufficientResource{
ResourceName: v1.ResourceEphemeralStorage,
Reason: "Insufficient ephemeral-storage",
Requested: podRequest.EphemeralStorage,
Used: nodeInfo.Requested.EphemeralStorage,
Capacity: nodeInfo.Allocatable.EphemeralStorage,
})
}
for rName, rQuant := range podRequest.ScalarResources {
if v1helper.IsExtendedResourceName(rName) {
// If this resource is one of the extended resources that should be ignored, we will skip checking it.
// rName is guaranteed to have a slash due to API validation.
var rNamePrefix string
if ignoredResourceGroups.Len() > 0 {
rNamePrefix = strings.Split(string(rName), "/")[0]
}
if ignoredExtendedResources.Has(string(rName)) || ignoredResourceGroups.Has(rNamePrefix) {
continue
}
}
if rQuant > (nodeInfo.Allocatable.ScalarResources[rName] - nodeInfo.Requested.ScalarResources[rName]) {
insufficientResources = append(insufficientResources, InsufficientResource{
ResourceName: rName,
Reason: fmt.Sprintf("Insufficient %v", rName),
Requested: podRequest.ScalarResources[rName],
Used: nodeInfo.Requested.ScalarResources[rName],
Capacity: nodeInfo.Allocatable.ScalarResources[rName],
})
}
}
return insufficientResources
}
kubectl describe node xxxx
Capacity:
cpu: 64
ephemeral-storage: 1056889268Ki
hugepages-1Gi: 0
hugepages-2Mi: 0
memory: 263042696Ki
pods: 110
Allocatable:
cpu: 63
ephemeral-storage: 1044306356Ki
hugepages-1Gi: 0
hugepages-2Mi: 0
memory: 257799816Ki
pods: 110
下kubelet相关配置:**
systemReserved:
cpu: "0.5"
ephemeral-storage: 1Gi
memory: 2Gi
pid: "1000"
kubeReserved:
cpu: "0.5"
ephemeral-storage: 1Gi
memory: 2Gi
pid: "1000
evictionHard:
imagefs.available: 10Gi
memory.available: 1Gi
nodefs.available: 10Gi
nodefs.inodesFree: 5%
*
# 该配置表示,capacity减去下面的配置的资源才是节点d当前可分配的
# 默认是pods,表示只减去pods占用了的资源
enforceNodeAllocatable:
- pods
- kube-reserved
- system-reserved
# 如果你使用的是systemd作为cgroup驱动,你还需要配置下面的配置
# 否则kubelet无法正常启动,因为找不到cgroup目录
# k8s官方推荐s会用systemd
kubeReservedCgroup: /kubelet.slice
systemReservedCgroup: /system.slice/kubelet.service
-
388 收藏
-
167 收藏
-
339 收藏
-
384 收藏
-
396 收藏
-
Golang · Go教程 | 1天前 | go · net/url · url · HTTP客户端 · 路径转义 · Go教程 url.JoinPath PathEscape RawPath URL拼接354 收藏
-
261 收藏
-
334 收藏
-
469 收藏
-
395 收藏
-
270 收藏
-
Golang · Go教程 | 2天前 | JSON · 基准测试 · go · 性能优化 · 内存分配 encoding/json json.RawMessage json.Decoder Go JSON206 收藏
-

- 前端进阶之JavaScript设计模式
- 设计模式是开发人员在软件开发过程中面临一般问题时的解决方案,代表了最佳的实践。本课程的主打内容包括JS常见设计模式以及具体应用场景,打造一站式知识长龙服务,适合有JS基础的同学学习。
- 立即学习 543次学习
-

- GO语言核心编程课程
- 本课程采用真实案例,全面具体可落地,从理论到实践,一步一步将GO核心编程技术、编程思想、底层实现融会贯通,使学习者贴近时代脉搏,做IT互联网时代的弄潮儿。
- 立即学习 516次学习
-

- 简单聊聊mysql8与网络通信
- 如有问题加微信:Le-studyg;在课程中,我们将首先介绍MySQL8的新特性,包括性能优化、安全增强、新数据类型等,帮助学生快速熟悉MySQL8的最新功能。接着,我们将深入解析MySQL的网络通信机制,包括协议、连接管理、数据传输等,让
- 立即学习 500次学习
-

- JavaScript正则表达式基础与实战
- 在任何一门编程语言中,正则表达式,都是一项重要的知识,它提供了高效的字符串匹配与捕获机制,可以极大的简化程序设计。
- 立即学习 487次学习
-

- 从零制作响应式网站—Grid布局
- 本系列教程将展示从零制作一个假想的网络科技公司官网,分为导航,轮播,关于我们,成功案例,服务流程,团队介绍,数据部分,公司动态,底部信息等内容区块。网站整体采用CSSGrid布局,支持响应式,有流畅过渡和展现动画。
- 立即学习 485次学习
-

- 阔达的路人
- 这篇文章内容真是及时雨啊,太全面了,赞 ??,收藏了,关注师傅了!希望师傅能多写Golang相关的文章。
- 2023-05-16 10:27:15
-
- 舒服的春天
- 受益颇多,一直没懂这个问题,但其实工作中常常有遇到...不过今天到这,看完之后很有帮助,总算是懂了,感谢作者大大分享技术文章!
- 2023-05-16 01:34:15