智谱联合华为,开源多模态SOTA模型
时间:2026-01-16 18:15:38 115浏览 收藏
今日不肯埋头,明日何以抬头!每日一句努力自己的话哈哈~哈喽,今天我将给大家带来一篇《智谱携手华为,开源多模态SOTA模型》,主要内容是讲解等等,感兴趣的朋友可以收藏或者有更好的建议在评论提出,我都会认真看的!大家一起进步,一起学习!
智谱携手华为正式开源全新一代图像生成模型GLM-Image。该模型全程依托昇腾Atlas 800T A2硬件平台与昇思MindSpore AI框架,实现了从数据准备、预处理到大规模训练的全链路国产化,成为首个在纯国产芯片上完成端到端训练的SOTA级多模态大模型。
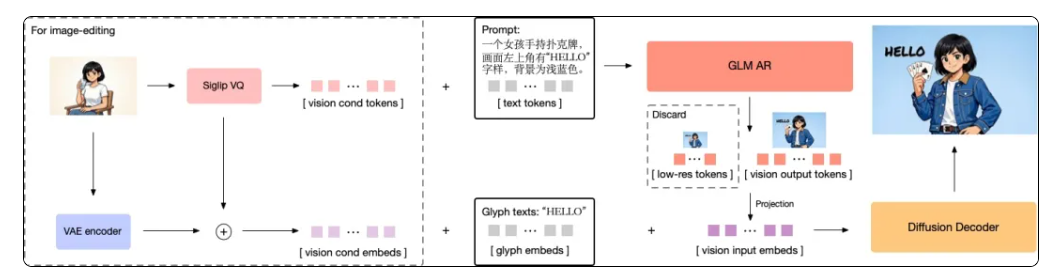
据悉,GLM-Image首创「自回归+扩散解码器」融合架构,深度融合语言理解与图像生成能力,标志着团队在以Nano Banana Pro为典型代表的“认知型生成”技术路径上取得关键突破。
核心优势一览:
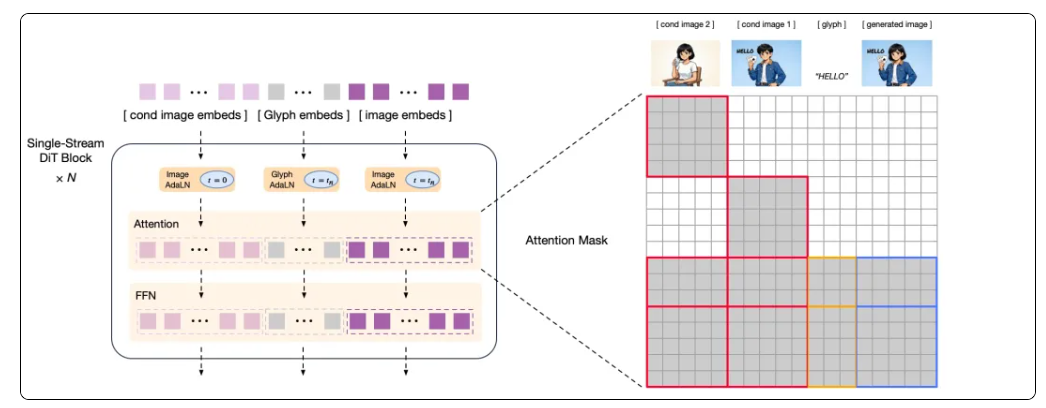
- 架构突破,引领“认知型生成”新范式:创新采用「自回归 + 扩散编码器」混合结构,在保障全局语义指令精准响应的同时,显著提升局部纹理与细节还原能力,有效攻克海报设计、PPT制作、科普插图等知识密集型任务中的生成瓶颈,为构建具备“知识理解+逻辑推理”能力的新一代生成模型奠定坚实基础。
- 全栈国产化训练标杆:模型自回归主干完全基于昇腾Atlas 800T A2算力设备及昇思MindSpore框架完成全流程开发与训练,涵盖数据清洗、特征工程、分布式训练及精度调优等全部环节,充分验证了国产AI软硬协同生态支撑前沿大模型研发的成熟度与可靠性。
- 文字渲染能力领跑开源社区:在CVTG-2K(复杂视觉文本生成)与LongText-Bench(长文本图像渲染)两大权威评测中均登顶开源模型榜首,尤其在中文字符生成方面表现卓越,鲁棒性与可读性俱佳。
- 极致成本与效率平衡:API服务模式下单图生成仅需0.1元;面向高吞吐场景的速度优化版本也已进入发布倒计时。
综合评测表明,GLM-Image已在文字渲染方向达成开源领域SOTA性能。
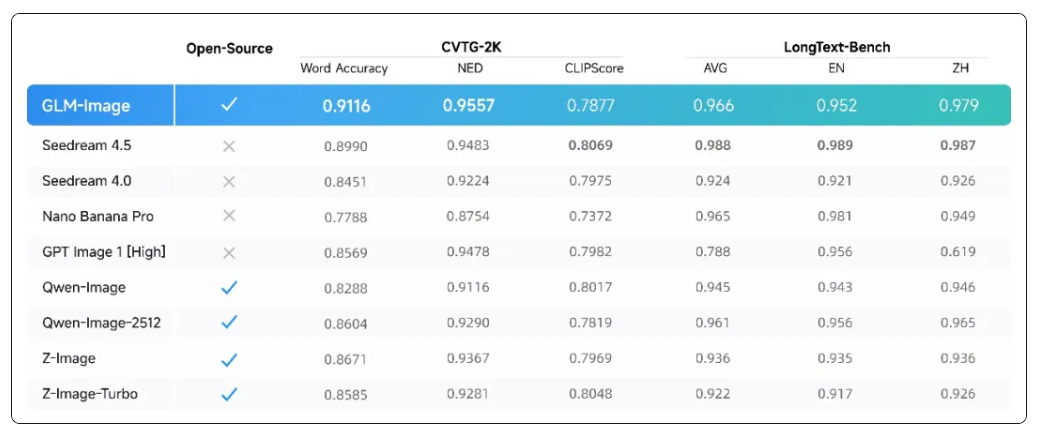
- 在CVTG-2K榜单中,模型重点评估图像内多区域文字同步生成的准确性。GLM-Image以0.9116的Word Accuracy(文字准确率) 高居开源模型首位;其NED(归一化编辑距离)指标达0.9557,远超同类方案,印证其在汉字识别、排版与拼写一致性上的强大能力,错字、漏字、乱序等问题显著减少。
- 在LongText-Bench榜单中,测试覆盖招牌、宣传海报、演示文稿、对话气泡等8类高密度文本场景,并分别进行中英文双语评估。GLM-Image以英文0.952、中文0.979的综合得分双双位列开源模型第一,凸显其对复杂中文排版与语义连贯性的深度建模能力。
源码获取地址:点击下载
理论要掌握,实操不能落!以上关于《智谱联合华为,开源多模态SOTA模型》的详细介绍,大家都掌握了吧!如果想要继续提升自己的能力,那么就来关注golang学习网公众号吧!

相关阅读
更多>
-
501 收藏
-
501 收藏
-
501 收藏
-
501 收藏
-
501 收藏
最新阅读
更多>
-
277 收藏
-
285 收藏
-
270 收藏
-
370 收藏
-
488 收藏
-
155 收藏
-
134 收藏
-
158 收藏
-
218 收藏
-
105 收藏
-
365 收藏
-
226 收藏
课程推荐
更多>
-

- 前端进阶之JavaScript设计模式
- 设计模式是开发人员在软件开发过程中面临一般问题时的解决方案,代表了最佳的实践。本课程的主打内容包括JS常见设计模式以及具体应用场景,打造一站式知识长龙服务,适合有JS基础的同学学习。
- 立即学习 543次学习
-

- GO语言核心编程课程
- 本课程采用真实案例,全面具体可落地,从理论到实践,一步一步将GO核心编程技术、编程思想、底层实现融会贯通,使学习者贴近时代脉搏,做IT互联网时代的弄潮儿。
- 立即学习 516次学习
-

- 简单聊聊mysql8与网络通信
- 如有问题加微信:Le-studyg;在课程中,我们将首先介绍MySQL8的新特性,包括性能优化、安全增强、新数据类型等,帮助学生快速熟悉MySQL8的最新功能。接着,我们将深入解析MySQL的网络通信机制,包括协议、连接管理、数据传输等,让
- 立即学习 500次学习
-

- JavaScript正则表达式基础与实战
- 在任何一门编程语言中,正则表达式,都是一项重要的知识,它提供了高效的字符串匹配与捕获机制,可以极大的简化程序设计。
- 立即学习 487次学习
-

- 从零制作响应式网站—Grid布局
- 本系列教程将展示从零制作一个假想的网络科技公司官网,分为导航,轮播,关于我们,成功案例,服务流程,团队介绍,数据部分,公司动态,底部信息等内容区块。网站整体采用CSSGrid布局,支持响应式,有流畅过渡和展现动画。
- 立即学习 485次学习