基于GPT-3的大语言模型训练任务刷新记录:NVIDIA H100加速卡仅用11分钟
来源:ITBear科技资讯
时间:2023-07-11 20:54:52 298浏览 收藏
亲爱的编程学习爱好者,如果你点开了这篇文章,说明你对《基于GPT-3的大语言模型训练任务刷新记录:NVIDIA H100加速卡仅用11分钟》很感兴趣。本篇文章就来给大家详细解析一下,主要介绍一下,希望所有认真读完的童鞋们,都有实质性的提高。
6月28日消息,AI技术的蓬勃发展使得NVIDIA的显卡成为市场上备受瞩目的热门产品。尤其是高端的H100加速卡,其售价超过25万元,然而市场供不应求。该加速卡的性能也非常惊人,最新的AI测试结果显示,基于GPT-3的大语言模型训练任务刷新了记录,完成时间仅为11分钟。

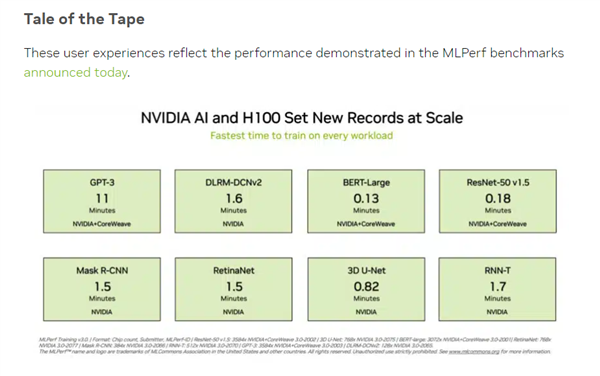
据小编了解,机器学习及人工智能领域的开放产业联盟MLCommons发布了最新的MLPerf基准评测。其中包括8个负载测试,其中就包含基于GPT-3开源模型的LLM大语言模型测试,这对于评估平台的AI性能提出了很高的要求。
参与测试的NVIDIA平台由896个Intel至强8462Y+处理器和3584个H100加速卡组成,是所有参与平台中唯一能够完成所有测试的。并且,NVIDIA平台刷新了记录。在关键的基于GPT-3的大语言模型训练任务中,H100平台仅用了10.94分钟,与之相比,采用96个至强8380处理器和96个Habana Gaudi2 AI芯片构建的Intel平台完成同样测试所需的时间为311.94分钟。
H100平台的性能几乎是Intel平台的30倍,当然,两套平台的规模存在很大差异。但即便只使用768个H100加速卡进行训练,所需时间仍然只有45.6分钟,远远超过采用Intel平台的AI芯片。
H100加速卡采用GH100 GPU核心,定制版台积电4nm工艺制造,拥有800亿个晶体管。它集成了18432个CUDA核心、576个张量核心和60MB的二级缓存,支持6144-bit HBM高带宽内存以及PCIe 5.0接口。
H100计算卡提供SXM和PCIe 5.0两种样式。SXM版本拥有15872个CUDA核心和528个Tensor核心,而PCIe 5.0版本则拥有14952个CUDA核心和456个Tensor核心。该卡的功耗最高可达700W。
就性能而言,H100加速卡在FP64/FP32计算方面能够达到每秒60万亿次的计算能力,而在FP16计算方面达到每秒2000万亿次的计算能力。此外,它还支持TF32计算,每秒可达到1000万亿次,是A100的三倍。而在FP8计算方面,H100加速卡的性能可达每秒4000万亿次,是A100的六倍。
今天带大家了解了的相关知识,希望对你有所帮助;关于科技周边的技术知识我们会一点点深入介绍,欢迎大家关注golang学习网公众号,一起学习编程~
-
501 收藏
-
501 收藏
-
501 收藏
-
501 收藏
-
501 收藏
-
345 收藏
-
356 收藏
-
277 收藏
-
285 收藏
-
270 收藏
-
370 收藏
-
488 收藏
-
155 收藏
-
134 收藏
-
158 收藏
-
218 收藏
-
105 收藏
-

- 前端进阶之JavaScript设计模式
- 设计模式是开发人员在软件开发过程中面临一般问题时的解决方案,代表了最佳的实践。本课程的主打内容包括JS常见设计模式以及具体应用场景,打造一站式知识长龙服务,适合有JS基础的同学学习。
- 立即学习 543次学习
-

- GO语言核心编程课程
- 本课程采用真实案例,全面具体可落地,从理论到实践,一步一步将GO核心编程技术、编程思想、底层实现融会贯通,使学习者贴近时代脉搏,做IT互联网时代的弄潮儿。
- 立即学习 516次学习
-

- 简单聊聊mysql8与网络通信
- 如有问题加微信:Le-studyg;在课程中,我们将首先介绍MySQL8的新特性,包括性能优化、安全增强、新数据类型等,帮助学生快速熟悉MySQL8的最新功能。接着,我们将深入解析MySQL的网络通信机制,包括协议、连接管理、数据传输等,让
- 立即学习 500次学习
-

- JavaScript正则表达式基础与实战
- 在任何一门编程语言中,正则表达式,都是一项重要的知识,它提供了高效的字符串匹配与捕获机制,可以极大的简化程序设计。
- 立即学习 487次学习
-

- 从零制作响应式网站—Grid布局
- 本系列教程将展示从零制作一个假想的网络科技公司官网,分为导航,轮播,关于我们,成功案例,服务流程,团队介绍,数据部分,公司动态,底部信息等内容区块。网站整体采用CSSGrid布局,支持响应式,有流畅过渡和展现动画。
- 立即学习 485次学习