openGeminiv1.5性能全面优化
时间:2026-02-02 15:18:41 208浏览 收藏
积累知识,胜过积蓄金银!毕竟在科技周边开发的过程中,会遇到各种各样的问题,往往都是一些细节知识点还没有掌握好而导致的,因此基础知识点的积累是很重要的。下面本文《openGemini v1.5 性能全面升级》,就带大家讲解一下知识点,若是你对本文感兴趣,或者是想搞懂其中某个知识点,就请你继续往下看吧~
openGemini 正式发布 v1.5 版本,本次更新不仅新增多项实用功能,更在读写性能方面实现了突破性优化。
一、数据模型:基于 TSBS cpu-only 的标准化测试
为保障测试结果的客观性与行业可比性,项目组选用业界主流的 TSBS(cpu-only)基准测试框架,复现典型时间序列应用场景。
- **测试环境:**3节点集群
- **单节点配置:**8核 CPU / 32GB 内存
- **时间线总量:**30 万条
- **测试实例规格:**c3.2xlarge.4,华为云 ECS 产品页
二、写入性能对比:更快、更省、更均衡
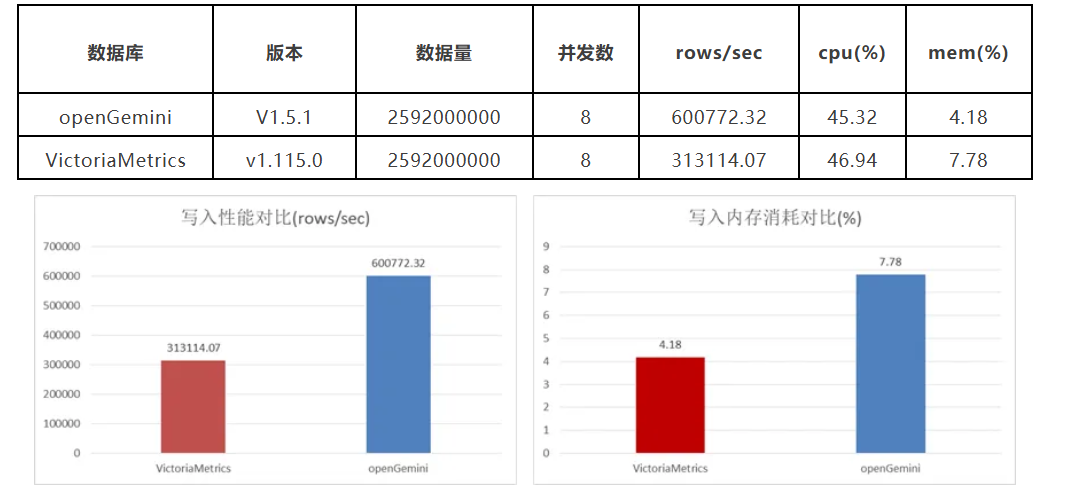
在 TSBS cpu-only 模型下,openGemini 的写入吞吐量达到 VictoriaMetrics(简称 VM)的约 2 倍;内存消耗仅为 VM 的 50%;CPU 占用率则与 VM 基本持平,资源利用效率显著提升。
三、查询性能表现:简查询不逊色,复查询更出众
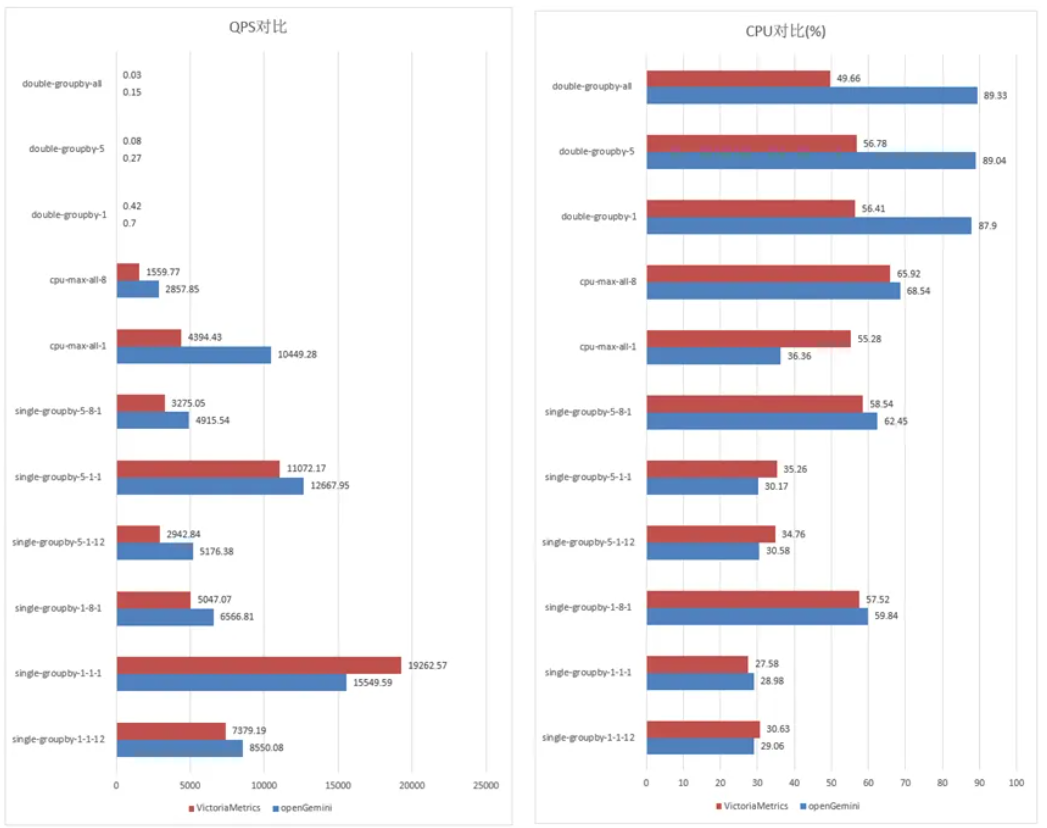
从测试结果可见,在资源开销相近的前提下,openGemini 在全部 11 个查询场景中的 10 个场景中均优于 VM。具体来看:
- 对于
single-groupby和cpu-max-all类查询,openGemini 性能约为 VM 的 1.2–2.4 倍; - 在
double-groupby-5与double-groupby-all场景中,性能优势扩大至 VM 的 1–3 倍; - 唯一例外是
single-groupby-1-1-1这类极简查询,VM 凭借其“轻量设计”仍保持领先——其架构强调最小化计算下推,天然适配最基础的聚合需求。
而 openGemini 在复杂聚合类查询中优势明显,这得益于团队对计算下推能力的深度打磨。v1.5 版本围绕多条件过滤、嵌套聚合及关联查询等高频复杂场景,重构了下推执行流程,使响应延迟和吞吐能力在高负载下依然稳定领先。
当然,团队也注意到当前策略在部分简单查询中存在“计算冗余”现象。后续版本将引入自适应下推决策机制,兼顾极致轻量与深度优化,真正实现“简单查询快如闪电,复杂查询稳如磐石”。
四、驱动性能跃升的三大核心技术突破
1. 智能查询语句匹配引擎
- 场景特征建模:结合车联网、IoT 监控等真实业务高频查询模式,提炼结构化语义特征;
- 极速链路绑定:通过预置特征与执行路径的映射关系,将查询匹配后执行器构建耗时由毫秒级压缩至微秒级,大幅缩短首字节响应时间。
2. 轻量高效执行器架构
- 上下文精简:大幅缩减查询上下文体积,降低网络传输与序列化/反序列化开销;
- 算子深度融合:持续优化 scan、filter、agg、project 四大核心算子,推动 scan/filter、agg/merge 等组合融合,消除中间数据搬运;
- 混合调度机制:融合 pull-based 与 push-based 执行范式,精简调用栈深度,减少函数跳转损耗;
- 向量化内存布局:采用 CPU 缓存友好的内存亲和格式与向量化数据结构,提升缓存命中率,降低编解码成本。
3. 全链路数据复用体系
- 统一数据载体:底层全面采用 Record 结构作为统一数据容器,原生支持 Record ↔ JSON 无损转换,规避多层格式转换开销;
- 分层内存池管理:构建分级内存复用机制,支撑 Record 数据在编解码、执行器初始化等多个环节的跨阶段复用,显著缓解 GC 压力,提升系统长期稳定性。
源码地址:点击下载
今天关于《openGeminiv1.5性能全面优化》的内容介绍就到此结束,如果有什么疑问或者建议,可以在golang学习网公众号下多多回复交流;文中若有不正之处,也希望回复留言以告知!

-
501 收藏
-
501 收藏
-
501 收藏
-
501 收藏
-
501 收藏
-
277 收藏
-
285 收藏
-
270 收藏
-
370 收藏
-
488 收藏
-
155 收藏
-
134 收藏
-
158 收藏
-
218 收藏
-
105 收藏
-
365 收藏
-
226 收藏
-

- 前端进阶之JavaScript设计模式
- 设计模式是开发人员在软件开发过程中面临一般问题时的解决方案,代表了最佳的实践。本课程的主打内容包括JS常见设计模式以及具体应用场景,打造一站式知识长龙服务,适合有JS基础的同学学习。
- 立即学习 543次学习
-

- GO语言核心编程课程
- 本课程采用真实案例,全面具体可落地,从理论到实践,一步一步将GO核心编程技术、编程思想、底层实现融会贯通,使学习者贴近时代脉搏,做IT互联网时代的弄潮儿。
- 立即学习 516次学习
-

- 简单聊聊mysql8与网络通信
- 如有问题加微信:Le-studyg;在课程中,我们将首先介绍MySQL8的新特性,包括性能优化、安全增强、新数据类型等,帮助学生快速熟悉MySQL8的最新功能。接着,我们将深入解析MySQL的网络通信机制,包括协议、连接管理、数据传输等,让
- 立即学习 500次学习
-

- JavaScript正则表达式基础与实战
- 在任何一门编程语言中,正则表达式,都是一项重要的知识,它提供了高效的字符串匹配与捕获机制,可以极大的简化程序设计。
- 立即学习 487次学习
-

- 从零制作响应式网站—Grid布局
- 本系列教程将展示从零制作一个假想的网络科技公司官网,分为导航,轮播,关于我们,成功案例,服务流程,团队介绍,数据部分,公司动态,底部信息等内容区块。网站整体采用CSSGrid布局,支持响应式,有流畅过渡和展现动画。
- 立即学习 485次学习