有一次订单库晚高峰写入抖动,第一反应很多人都盯着磁盘 IOPS。我更愿意先看 redo log:如果检查点一直追着写入跑,脏页刷新被迫加速,接口 p99 就会像被人轻轻拽一下,一阵一阵地抖。
MySQL 8.0.30 以后,生产上更常见的是用 innodb_redo_log_capacity 管 redo log 总容量,而不是继续围着老的文件数和文件大小参数转。到 MySQL 8.4 LTS,这个参数已经是很多升级项目绕不开的检查项。它能缓解写入突发,也会影响崩溃恢复窗口,所以不能靠一句“调大点”解决。
先把问题问对:redo log 容量解决什么
InnoDB 修改数据页时,会先写 redo log。真正的数据页可以稍后刷回磁盘,这让写入路径不用每次都把随机页同步落盘。问题在于 redo log 空间不是无限的,如果写入速度长期压过检查点推进速度,MySQL 就会被迫更积极地刷脏页,前台写入延迟也容易被拖起来。
所以 innodb_redo_log_capacity 解决的是“写入突发和检查点压力之间的缓冲空间”。它不是慢 SQL 优化器,不是锁等待解药,也不是磁盘性能替代品。如果根因是二级索引太多、事务太长、fsync 抖动或热点行锁,单纯调大 redo log 只能让现象变得更难看清。
先查当前容量和版本,不要沿用老经验
我接手老实例时,第一步会确认版本和当前参数。很多团队升级 MySQL 后,配置文件里还留着老参数,真正生效的却已经是新的总容量模型。
SHOW VARIABLES LIKE 'innodb_redo_log_capacity'; SHOW VARIABLES LIKE 'innodb_log_file_size'; SHOW VARIABLES LIKE 'innodb_log_files_in_group';
如果你在 MySQL 8.4 上做变更,我建议把变更单写清楚:当前容量、目标容量、写入峰值、压测窗口、预估恢复时间、回滚方案。redo log 改动看起来像一个参数,实际上牵着写入稳定性和故障恢复。
我怎么估一个比较稳的容量
粗略估算可以从峰值 redo 生成速率开始。比如压测或高峰期观察到 redo 写入大约 80MB/s,你希望给检查点留 60 秒缓冲,那容量至少要有 4.8GB,再加上业务突发和后台任务余量,落到 6GB 到 8GB 会更像一个可讨论的起点。
这个估算不是精确公式,而是帮你避免两个极端:一边是容量太小,写入一冲高就开始追检查点;另一边是容量拍到几十 GB,平时看着舒服,真崩溃恢复时才发现窗口被拉长。
动态调整也要灰度观察
新版本支持更灵活地调整 redo log 容量,但我仍然不建议在高峰随手改。比较稳的做法是低峰灰度,先调一档,然后观察错误日志、脏页刷新、写入延迟和磁盘利用率。
SET PERSIST innodb_redo_log_capacity = 8589934592; SHOW VARIABLES LIKE 'innodb_redo_log_capacity';
如果实例启用了 Performance Schema,也可以结合 redo log 文件相关表观察状态。不同小版本字段会有差异,脚本不要写死成“所有环境都一样”,上线前在目标版本上实际跑一遍。

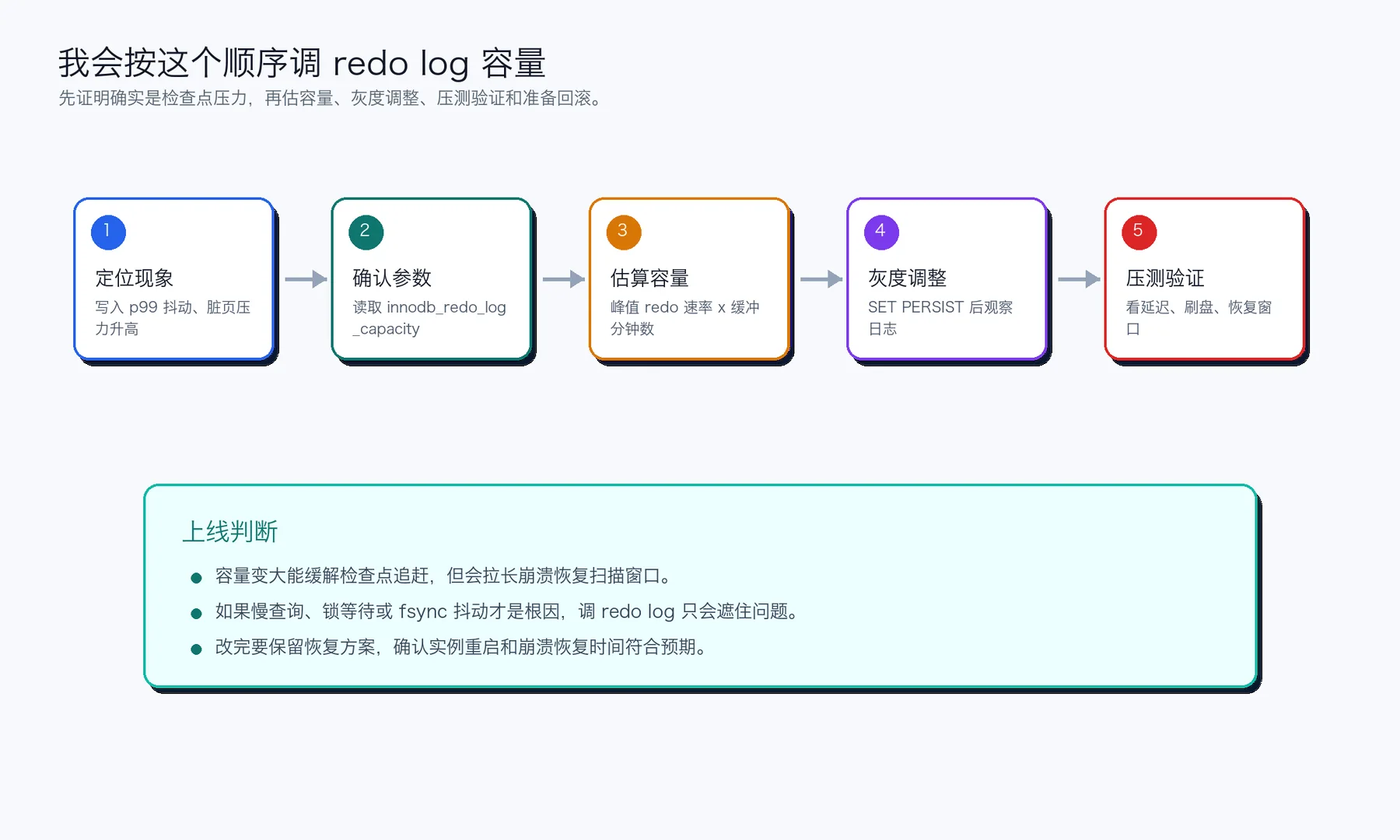
一次真实的排查顺序
我会先看写入延迟是不是和刷脏页、checkpoint 推进相关。如果业务日志显示 insert/update p99 抖动,同时磁盘写入稳定但 InnoDB 刷新变得急促,redo log 容量就值得进入候选项。
然后我会排除几个更常见的噪音:长事务不提交、批量任务一次改太多行、二级索引设计过重、binlog sync 策略太激进、热点行更新导致锁等待。如果这些没排掉,调 redo log 很容易变成“参数遮羞布”。
上线检查清单
- 确认目标实例是 MySQL,不要把 MariaDB 或其他数据库参数混进来。
- 确认 MySQL 版本,尤其是 8.0.30 前后的 redo log 参数差异。
- 记录当前
innodb_redo_log_capacity、写入峰值和磁盘余量。 - 在低峰或灰度环境调整,观察错误日志和写入 p95/p99。
- 做一次重启或恢复时间评估,确保容量变大后恢复窗口还能接受。
- 保留回滚值,不要在事故现场临时猜参数。
我的经验结论
redo log 容量调优最怕两种人:一种把它当玄学按钮,看到写入慢就调大;另一种完全不敢动,继续用多年前的经验判断新版本。我的做法很简单:先证明检查点压力存在,再按写入峰值和恢复目标估容量,最后用压测和灰度把结果落地。
如果调完之后写入 p99 变稳、刷脏页压力下降、恢复窗口仍然可接受,这次变更才算闭环。否则就回到 SQL、索引、事务和磁盘链路继续查,别让一个参数替真正的根因背锅。




