我第一次真正重视 asyncio.TaskGroup,不是因为它写起来更优雅,而是因为线上一个 FastAPI 接口超时后,后台任务还在跑,连接池也迟迟不回收。异步代码最容易骗人的地方就在这里:请求已经返回 504,但你创建出去的协程未必真的停了。
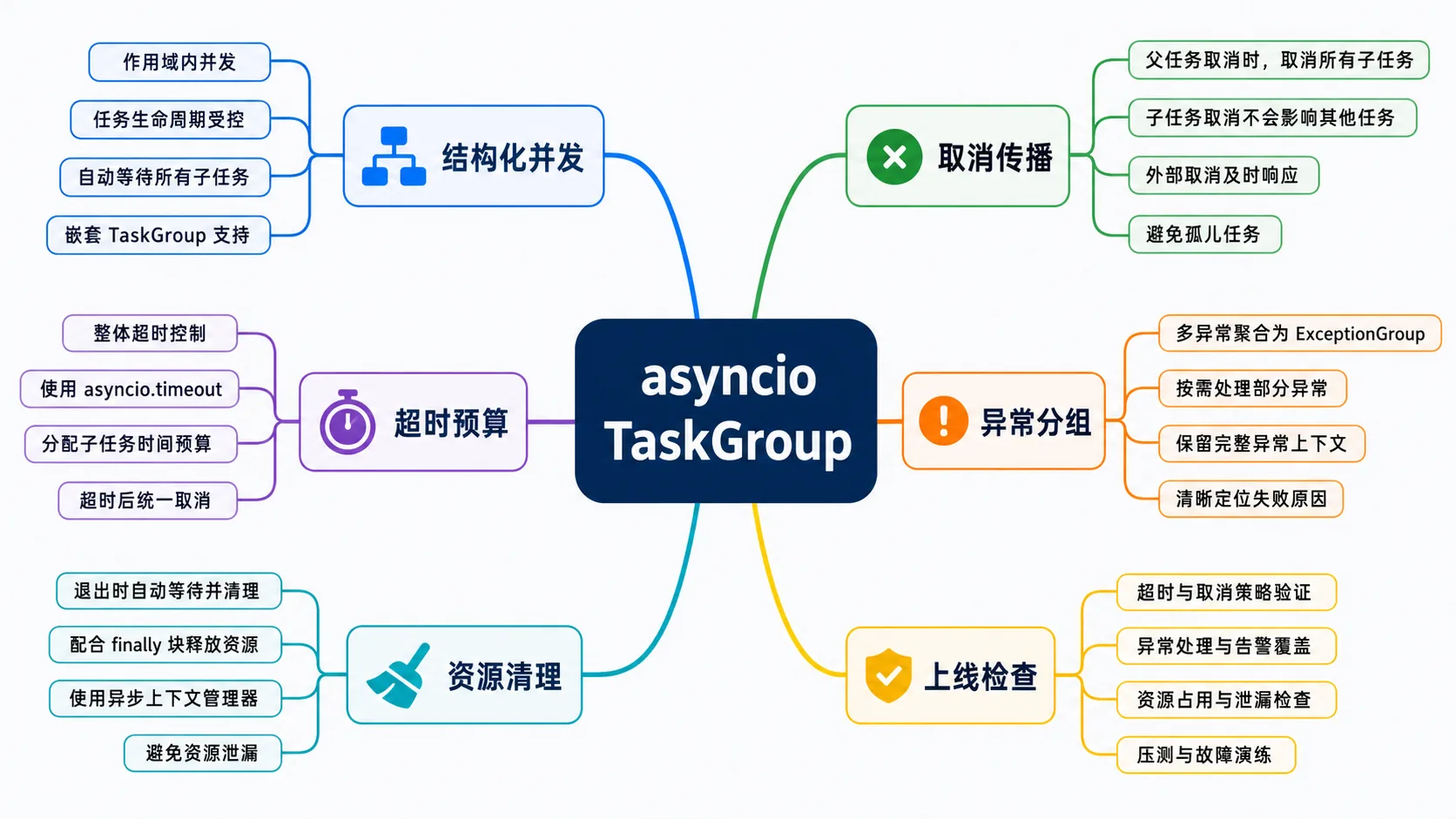
这篇聊一个很具体的 Python 生产问题:在 Python 3.11+ 里,如何用 asyncio.TaskGroup、asyncio.timeout 和正确的取消处理,把并发调用收口。资料我只用来核对事实:Python 官方文档明确把 TaskGroup 称为结构化并发的一部分,timeout 和 TaskGroup 都依赖取消语义;真正上线时,难点不是 API 名字,而是你有没有把失败、超时和清理路径写完整。
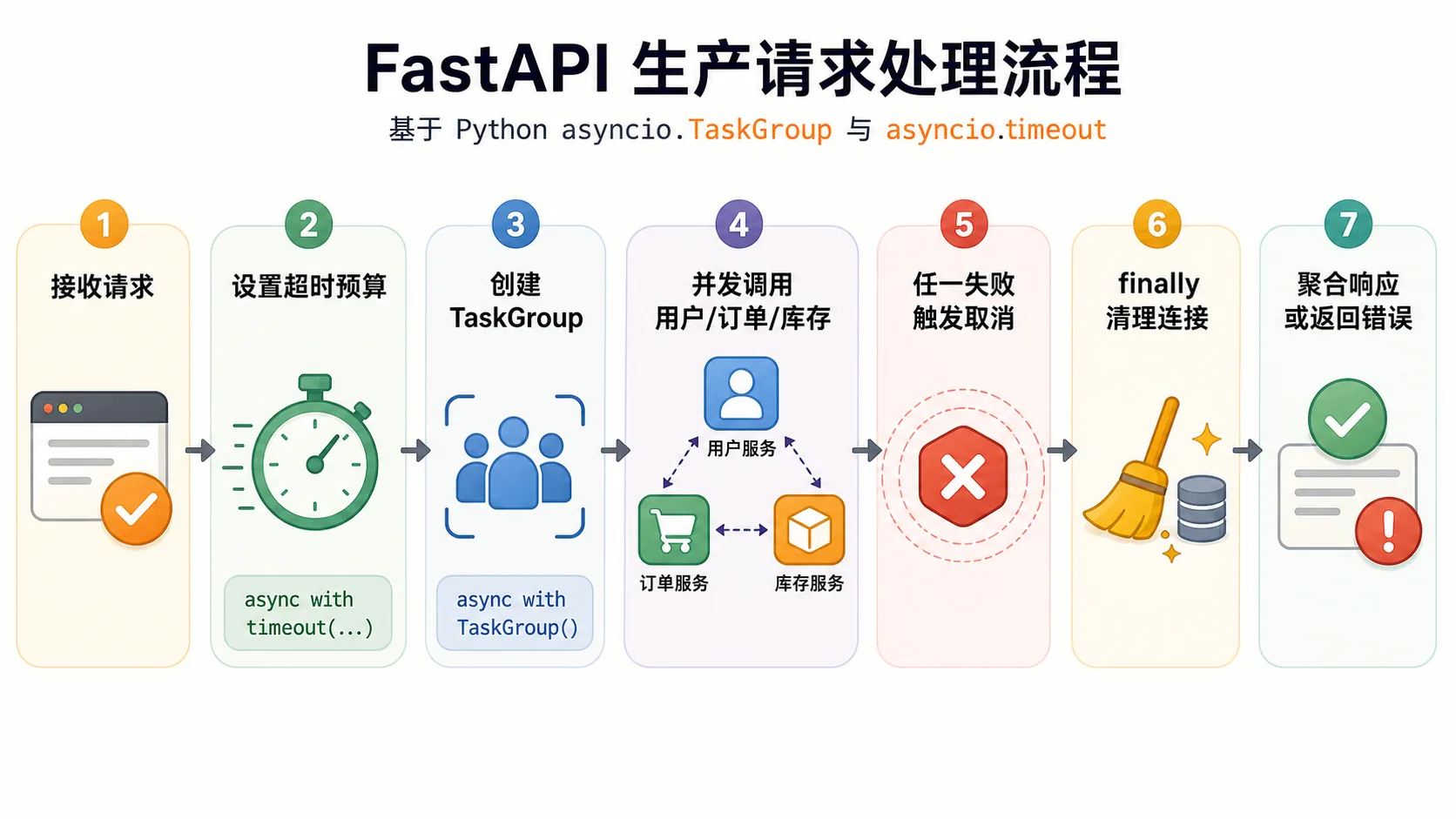
业务场景:一个接口并发查三类数据
假设订单详情页要同时拿用户、订单和库存。最直接的写法是把三个协程丢给 asyncio.gather。这在 demo 里很好看,但生产里会遇到几个问题:任何一个下游慢了怎么办?其中一个失败后,其他任务是否继续占连接?调用方取消请求后,后台协程有没有收到取消?
我更愿意把这类代码写成“有边界的并发块”:入口设置整体预算,并发块内部启动任务,异常统一冒泡,退出时确保连接、锁、临时文件、span 都能清理。TaskGroup 的价值就在这里,它让一组任务像一个作用域,而不是散落在函数里的后台任务。
容易出事的写法
async def detail(user_id: int, order_id: int):
user_task = asyncio.create_task(fetch_user(user_id))
order_task = asyncio.create_task(fetch_order(order_id))
stock_task = asyncio.create_task(fetch_stock(order_id))
try:
return await asyncio.gather(user_task, order_task, stock_task)
except asyncio.CancelledError:
# 这个吞掉取消的写法很危险
logger.warning("request cancelled")
return None
这段代码的问题不是一定会炸,而是边界很松。首先,create_task 创建的是脱离当前语义块的任务,你必须非常清楚谁负责等待、谁负责取消。其次,CancelledError 不能随便吞;它是 asyncio 用来传播取消的信号。吞掉之后,上层以为已经取消,底层可能还在跑。
更适合上线的写法
import asyncio
async def detail(user_id: int, order_id: int):
try:
async with asyncio.timeout(0.8):
async with asyncio.TaskGroup() as tg:
user_task = tg.create_task(fetch_user(user_id))
order_task = tg.create_task(fetch_order(order_id))
stock_task = tg.create_task(fetch_stock(order_id))
return {
"user": user_task.result(),
"order": order_task.result(),
"stock": stock_task.result(),
}
except TimeoutError:
raise ServiceTimeout("order detail timeout")
except* DownstreamError as eg:
logger.exception("downstream failed", extra={"count": len(eg.exceptions)})
raise
这个版本有几个好处。asyncio.timeout 定义了整体预算;TaskGroup 让三个任务在同一个作用域内结束;其中一个任务异常时,其余任务会收到取消;任务结果只在 TaskGroup 正常退出后读取。你不用在函数最后猜哪些后台任务还活着。
最容易忽略的是 finally
很多人讨论 asyncio 只盯着 await,但真正的生产事故经常来自清理路径。协程被取消时,会在等待点抛出 CancelledError,你的代码必须允许它继续向外传播,同时在 finally 里释放资源。
async def fetch_user(user_id: int):
conn = await pool.acquire()
try:
return await query_user(conn, user_id)
finally:
await pool.release(conn)
如果你为了“日志好看”捕获了所有异常,然后没有重新抛出 CancelledError,超时预算就会失效。我的习惯是:业务异常可以转换,取消信号尽量不要拦;确实要记录日志,也要继续 raise。
异常分组不是装饰品
TaskGroup 退出时,多个任务的异常可能以 ExceptionGroup 的形式出现。Python 3.11 引入的 except* 正是为了这类并发异常。上线代码里,我会区分下游错误、业务错误和不可恢复错误,不会把所有异常都压成一句 failed。
try:
await detail(user_id, order_id)
except* DownstreamTimeout as eg:
metrics.increment("downstream.timeout", len(eg.exceptions))
raise ServiceTimeout()
except* ValidationError:
raise BadRequest()
一次真实排查路径
如果你怀疑异步任务没有收口,不要只看接口日志。先看超时之后连接池是否下降,再看事件循环里任务数量是否持续增长,最后给关键协程补上取消日志。Python 里可以在压测环境周期性打印 len(asyncio.all_tasks()),再结合 OpenTelemetry span 和连接池指标确认是不是任务残留。

上线检查清单
- 每个请求入口有没有明确的总超时预算?
- 并发子任务是否都在 TaskGroup 这样的结构化作用域里创建?
- 有没有捕获
CancelledError后不重新抛出的代码? - 数据库连接、HTTP client、锁、临时文件是否在
finally里释放? - 异常日志里能不能区分超时、下游失败和业务校验失败?
- 压测时任务数量、连接池占用、延迟分位是否能在超时后回落?
结语
Python 异步代码的生产质量,不取决于你用了多少 async 关键字,而取决于任务有没有边界、取消能不能传播、资源能不能释放。TaskGroup 给了我们一个更清楚的结构,但它不是自动修复器;你仍然要尊重取消语义,别吞掉该向上传的信号。
我的建议很朴素:写异步接口时,先画出请求预算和任务作用域,再写代码。能在纸上说清楚“谁启动、谁等待、谁取消、谁清理”,这段 Python 才更像能上生产的代码。




