有一次订单查询接口 p99 从 180ms 飙到 1.8s,团队第一反应是“数据库慢了,要不要加缓存”。我没急着改代码,而是在出问题的实例上抓了一段 120 秒的 JDK Flight Recorder。结果很快就变清楚:不是 SQL 本身慢,而是连接池等待叠加一次对象分配暴涨,把接口拖成了长尾。
JFR 的价值不是图好看,而是它能把 CPU、锁等待、GC、分配、线程阻塞放在同一个时间轴里。Oracle/OpenJDK 文档和 JDK Mission Control 说明可以帮我们核对事件含义,但真正写生产教程时,重点应该是怎么抓、怎么看、怎么避免误判。
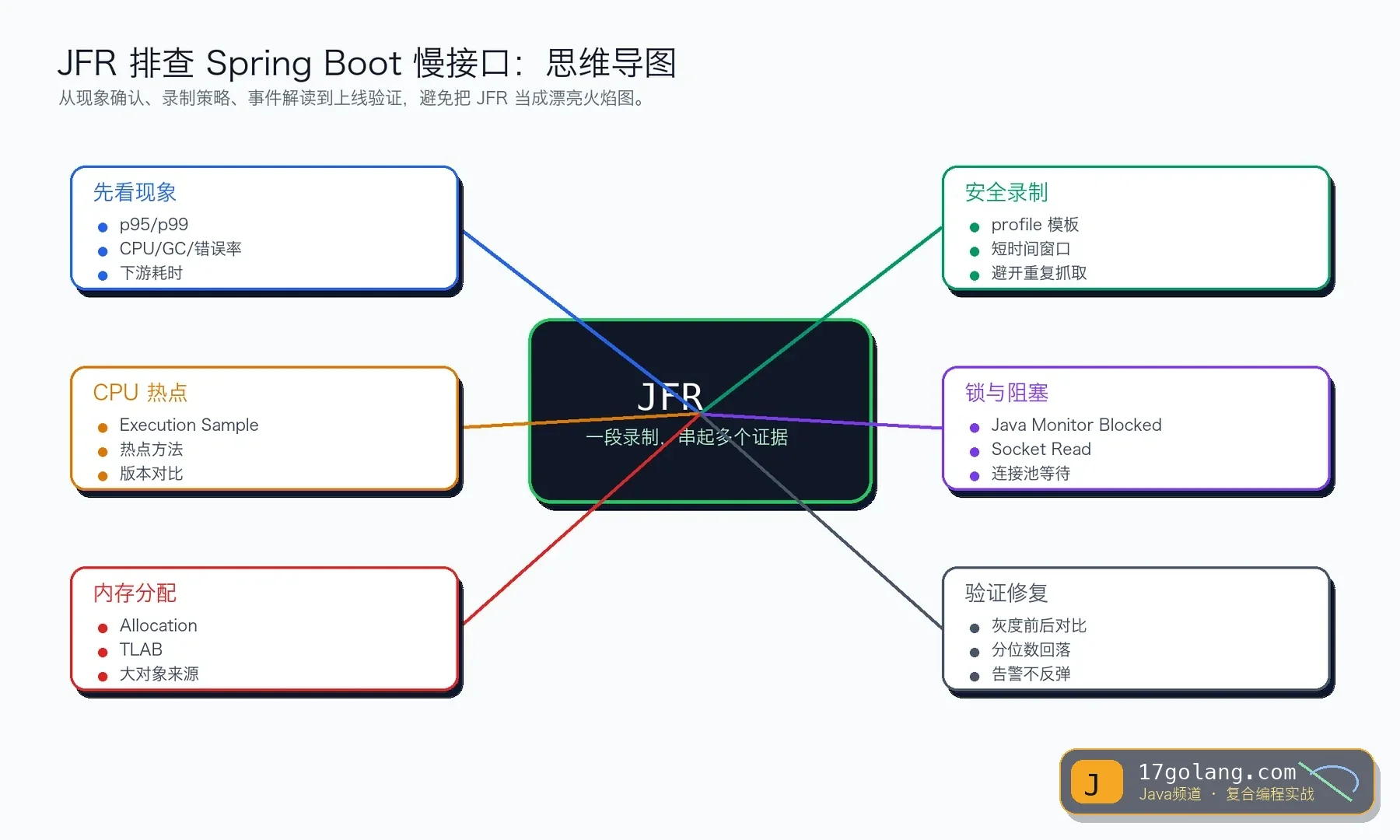
什么时候我会抓 JFR
如果只是某个下游偶发 500,我会先看日志和链路追踪;但如果 p95/p99 抬升、CPU 和 GC 又说不清楚,JFR 就很适合。它比普通线程 dump 多了时间维度,也比单纯火焰图更容易看到锁、分配和 I/O 等待。
我的习惯是先缩小窗口:哪台实例、哪一分钟、哪个接口、有没有刚发布的版本。窗口越小,JFR 越好读。千万别一上来全站长时间录制,排障工具也要讲边界。
生产上怎么安全录制
常用方式是 jcmd,对已经运行的 JVM 启动一段短录制:
jcmd $PID JFR.start name=slow-api settings=profile duration=120s filename=/tmp/slow-api.jfr
如果是容器环境,先确认容器里能拿到目标 JVM 的 PID,文件路径也要能导出。录制时间我一般控制在 60 到 180 秒,足够覆盖慢接口,又不会让文件大到难分析。
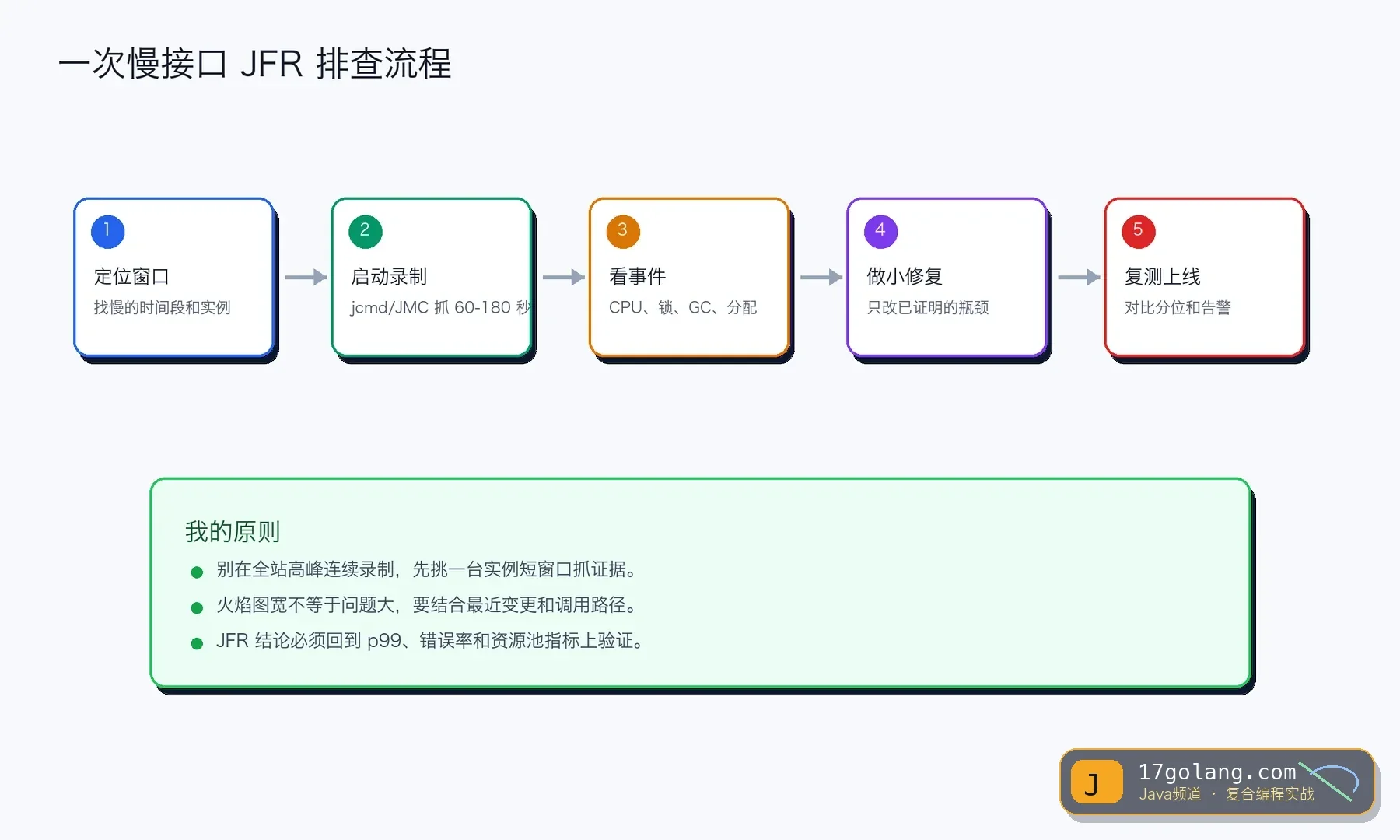
看 JFR 时我先看这四类事件
第一是 Execution Sample,看 CPU 时间花在哪里。注意火焰图最宽的方法不一定是罪魁祸首,它可能只是正常业务热点,要结合最近变更和接口路径。
第二是 Java Monitor Blocked、Thread Park、Socket Read 这类等待事件。很多慢接口不是“跑得慢”,而是在等锁、等连接、等下游。第三是 GC Pause 和 Allocation,看是不是分配暴涨把 GC 推高。第四是异常和日志事件,它们能帮你把慢的时间点对齐到业务行为。
一个典型误判:以为数据库慢,其实是连接池排队
我们那次事故里,SQL 执行本身不慢,但连接池等待时间在高峰抬起来。JFR 里能看到大量线程停在获取连接的路径上,同时分配事件显示某个 DTO 转换在高峰制造了很多临时对象。最后修复不是盲目加缓存,而是拆掉一次无意义的全量映射,并把连接池等待指标接入告警。

上线检查清单
- 录制窗口是否覆盖真实慢请求,而不是低峰随手抓一段?
- 是否同时看了 CPU、锁等待、I/O 等待、GC 和分配事件?
- 结论是否能和链路追踪、连接池指标、GC 日志相互印证?
- 修复后是否对比了同流量下的 p95/p99 和错误率?
- JFR 文件是否包含敏感业务数据,是否按团队规范保存和清理?
最后聊两句
JFR 最适合解决“大家都觉得可能是某个问题,但没人拿得出证据”的场景。它不会替你做判断,却能把判断需要的证据摆出来。
我的建议是把 JFR 当成 Java 后端的生产基本功:平时就练会短窗口录制、事件解读和版本对比。真到 p99 爆掉那天,你会少很多拍脑袋,多一条清晰的排障路线。




