我见过不少慢 SQL,表面看像缺索引,真正的问题却是优化器估错了行数。尤其是订单状态、渠道、城市、会员等级这类列,值不多但分布很偏:大部分订单是 SUCCESS,FAILED 只占很小一撮。如果优化器按平均分布猜,执行计划就容易跑偏。
MySQL 8.4 里,直方图统计信息是处理这类问题的一个好工具。官方文档里 ANALYZE TABLE ... UPDATE HISTOGRAM 可以给列生成直方图并存到数据字典,8.4 还支持 AUTO UPDATE,让直方图随统计信息更新自动刷新。它不是替代索引,而是帮优化器更接近真实数据分布。
什么时候我会考虑直方图
我会先看 EXPLAIN ANALYZE 或线上 SQL 指纹:如果优化器估算 rows 和实际扫描行数差距很大,且误差来自非索引过滤列或低选择性倾斜列,直方图就值得试。典型例子是状态、渠道、枚举类型、地域、租户等级。
但如果这个列本来就应该支撑高频过滤和排序,别拿直方图逃避建索引。直方图只能改善估算,它不能让 MySQL 少读数据页,也不能替代一个真正合适的组合索引。
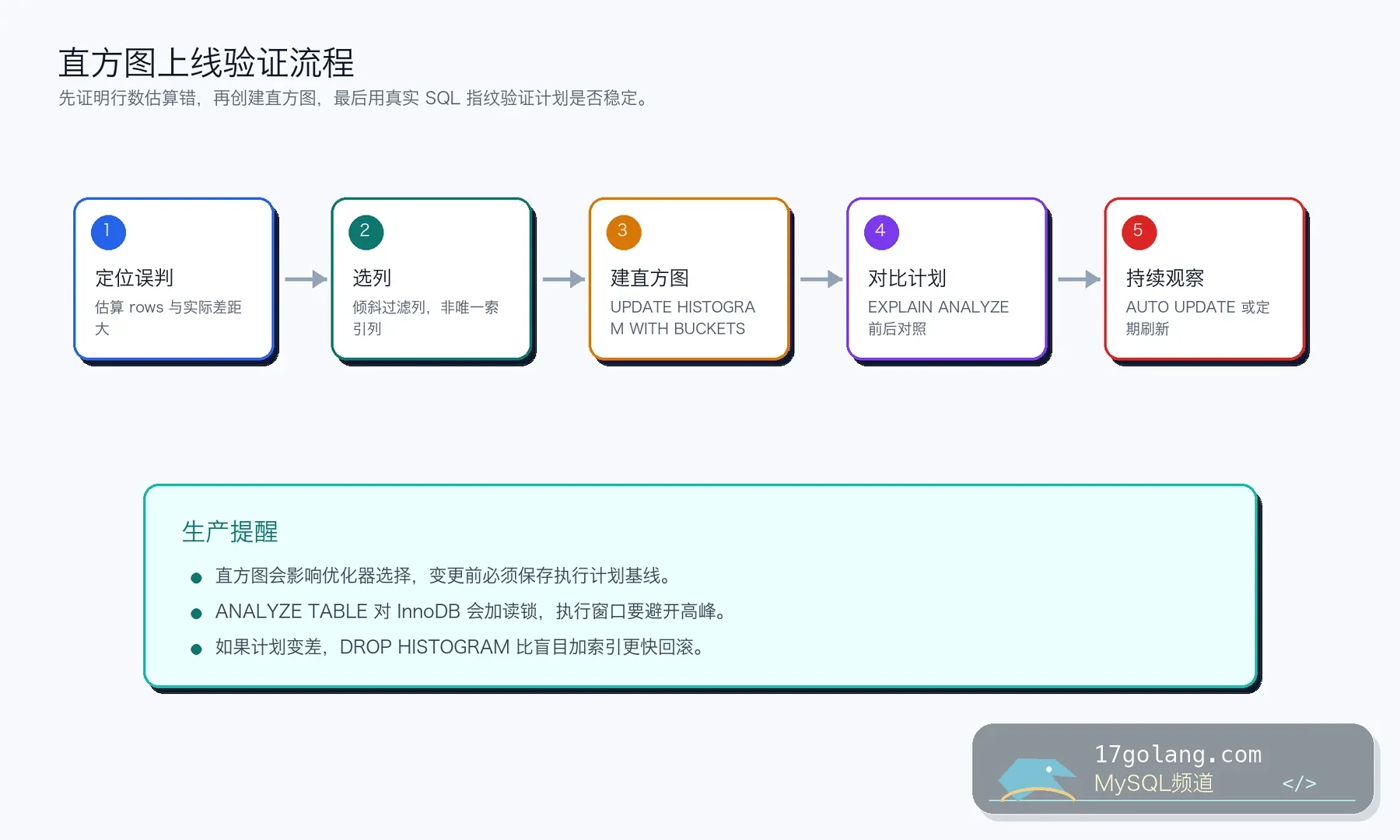
先做基线,再创建直方图
上线前我会保存 SQL、执行计划、实际耗时和 rows 估算。没有基线,调完以后你很难判断是直方图有效,还是缓存、流量和数据波动在骗你。
EXPLAIN ANALYZE SELECT * FROM orders WHERE status = 'FAILED' AND created_at >= NOW() - INTERVAL 1 DAY;
确认误判以后,再对候选列创建直方图。桶数不是越大越好,生产里我通常从 32 或 64 开始,观察计划是否稳定,再决定是否调整。
ANALYZE TABLE orders UPDATE HISTOGRAM ON status, channel WITH 64 BUCKETS AUTO UPDATE;
怎么确认它真的生效
创建后可以从 information_schema.COLUMN_STATISTICS 查看直方图信息,也可以再次跑 EXPLAIN ANALYZE 对比估算和实际。我的判断标准不是“计划变了”,而是估算更接近实际、慢查询分位更稳、没有把其他 SQL 带偏。
SELECT SCHEMA_NAME, TABLE_NAME, COLUMN_NAME, HISTOGRAM FROM information_schema.COLUMN_STATISTICS WHERE TABLE_NAME = 'orders';
这里要记住一个生产细节:ANALYZE TABLE 对 InnoDB 会加读锁,虽然通常不算重操作,但高峰期别随手跑。涉及复制环境时,也要确认是否需要 NO_WRITE_TO_BINLOG 或按你们的变更规范处理。

直方图的边界和回滚
直方图来自采样,不一定覆盖所有重要值。数据变化快、分布突变明显的表,要么开启自动更新,要么定期刷新,并观察计划是否抖动。如果新计划反而变差,回滚也很直接:
ANALYZE TABLE orders DROP HISTOGRAM ON status, channel;
我不建议把直方图当万能补丁。它最适合修正优化器认知,不适合掩盖坏 SQL、坏索引和坏数据模型。真正要让查询稳定,还是要把 SQL 形态、索引、统计信息和业务数据分布放在一起看。
上线检查清单
- 确认目标列存在明显分布倾斜,且误判能从执行计划里看出来。
- 保存变更前 SQL 指纹、执行计划、rows 估算和慢查询分位。
- 从较小桶数开始,比如 32 或 64,不要直接拉满 1024。
- 避开高峰执行
ANALYZE TABLE,并确认复制和 binlog 策略。 - 创建后观察一个完整业务周期,防止低频 SQL 被带偏。
- 保留
DROP HISTOGRAM回滚语句和变更记录。
我的经验结论
直方图最有价值的地方,是让优化器别再用“平均值想象世界”。当列值分布严重倾斜时,一点统计信息就可能让执行计划从绕路回到正路。
但它依然只是证据,不是魔法。生产环境里,先证明估算错,再小步创建直方图,最后用真实流量验证,这个顺序比任何参数口诀都可靠。




