并发 bug 最烦人的地方,不是它难修,而是它经常“不按时上班”。压测十次九次正常,线上一到高峰就偶发错账、缓存脏读、状态回退。很多团队最后会在代码里加一堆 time.Sleep、日志和重试,表面上问题少了,其实数据竞争还在。
这篇我按真实排障写:从一个共享计数器和订单状态缓存的场景出发,讲清楚 Go 的 race detector 怎么跑、报告怎么看、哪些修复方式靠谱,以及为什么它应该进 CI,而不是等线上出事再临时想起来。
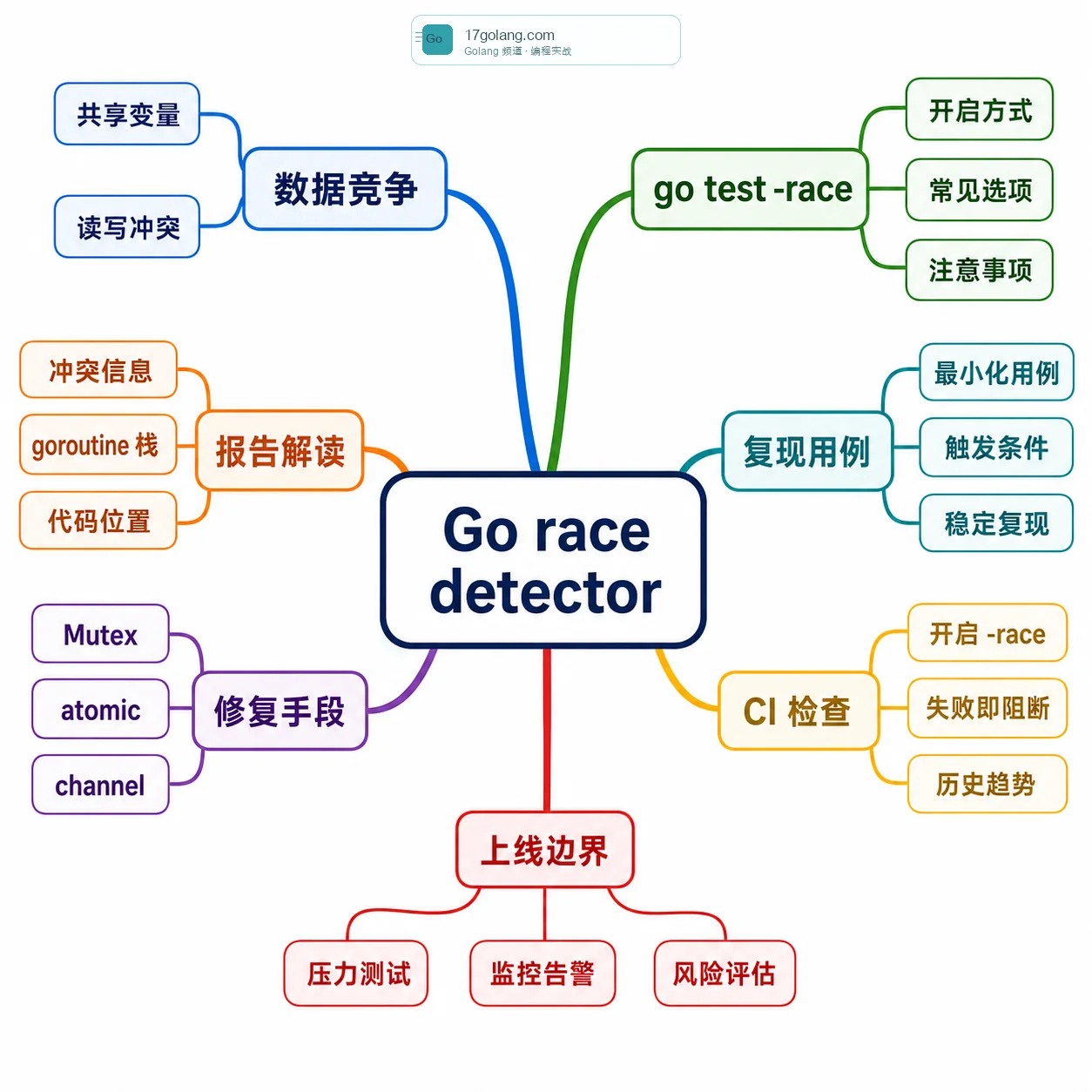
先说结论:race detector 不是性能工具,是事故拦截器
Go 官方的 race detector 会在程序运行时检测数据竞争。简单说,只要两个 goroutine 同时访问同一块内存,其中至少一个是写,并且没有同步保护,就可能被抓出来。它不是静态分析,必须把代码跑起来,所以测试覆盖和复现场景非常关键。
我在项目里会把它当成“上线前的并发体检”。平时开发可以局部跑,合并前跑重点包,发布前对核心链路做带 -race 的压测。它会让程序变慢、占用更多内存,但这个成本比线上追偶发脏数据便宜太多。
业务场景:一个看起来无害的计数器
先看一个很小的例子。某个接口里我们想统计内存中的成功次数,代码像这样:
type Counter struct {
n int
}
func (c *Counter) Inc() {
c.n++
}
func (c *Counter) Value() int {
return c.n
}
单测里顺序调用没有问题,压测时却会出现统计不准。原因很直接:c.n++ 不是一个原子动作,它至少包含读、加、写。两个 goroutine 同时进来,就可能互相覆盖。
写一个最小复现用例,不要靠睡眠撞运气:
func TestCounterRace(t *testing.T) {
var c Counter
var wg sync.WaitGroup
for i := 0; i < 100; i++ {
wg.Add(1)
go func() {
defer wg.Done()
c.Inc()
}()
}
wg.Wait()
_ = c.Value()
}
怎么跑:先局部,再全量
最常用的是这条:
go test -race ./...
如果项目很大,第一次不要全仓硬跑,可以先从出问题的包开始:
go test -race ./internal/order -run TestCounterRace -count=1
如果是接口压测或命令行程序,也可以用:
go run -race ./cmd/api
我通常会把复现分三层:最小单测确认 race detector 能抓住;集成测试覆盖真实调用链;最后在预发环境用 -race 跑一轮小流量压测。只跑最小单测容易漏掉对象复用、缓存刷新、回调和异步任务里的竞争。
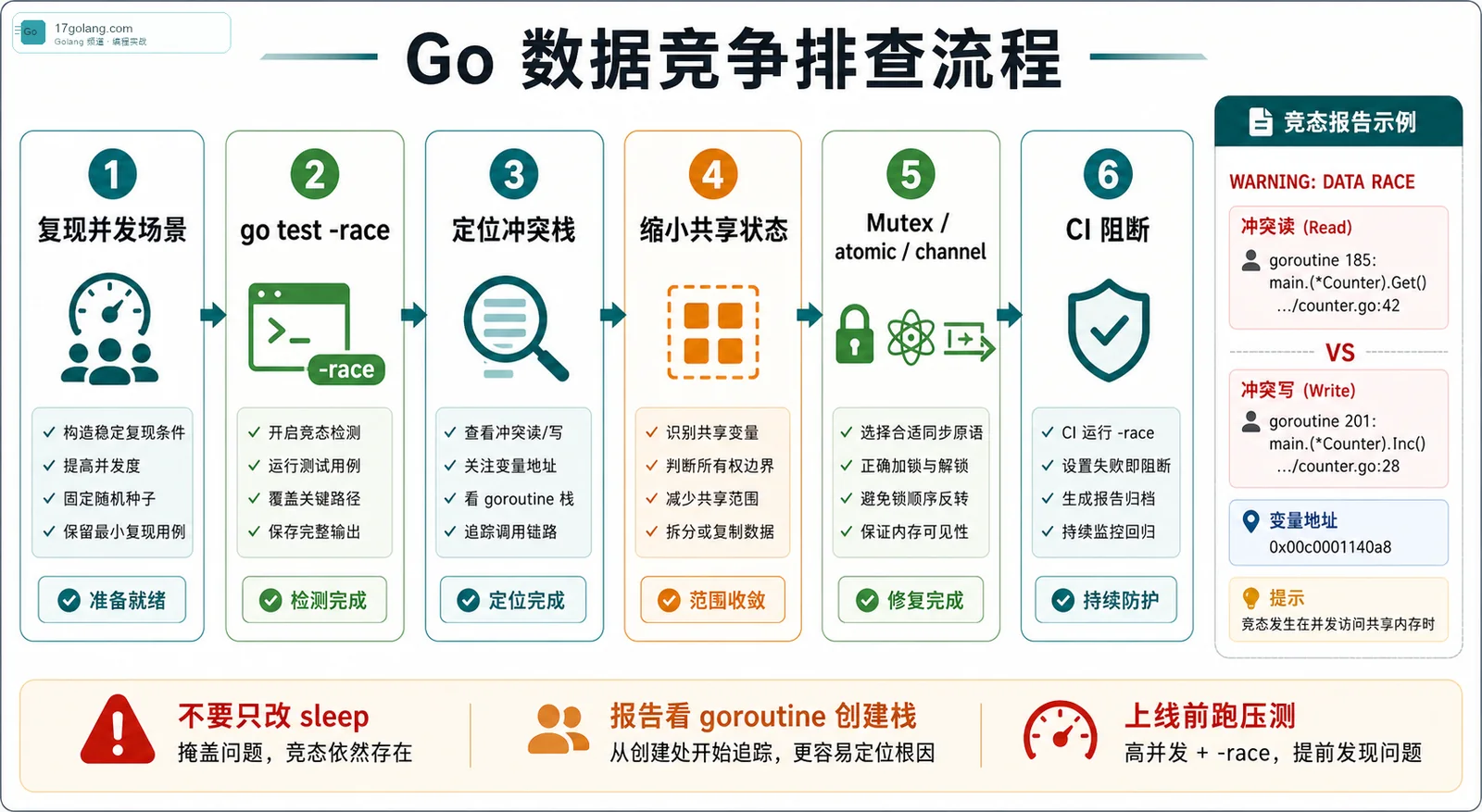
报告怎么看:重点不是 WARNING,而是两段栈
race detector 报告里最有价值的是两组信息:一次读或写发生在哪里,另一次冲突访问发生在哪里,以及相关 goroutine 是在哪里创建的。很多人只看到 WARNING: DATA RACE 就开始乱改锁,结果锁加在外围,真正共享变量还在裸奔。
我看报告会按这个顺序:
- 先找冲突变量:是计数器、map、slice,还是结构体里的状态字段。
- 再看读写方向:读写冲突、写写冲突,还是对象复用导致的旧引用被改。
- 然后看 goroutine 创建栈:很多根因不在报错函数,而在启动异步任务的地方。
- 最后回到业务语义:这个状态到底应该共享、复制,还是交给一个 goroutine 独占。
修复方式:别一上来就全局大锁
最直接的修复是加互斥锁:
type Counter struct {
mu sync.Mutex
n int
}
func (c *Counter) Inc() {
c.mu.Lock()
defer c.mu.Unlock()
c.n++
}
func (c *Counter) Value() int {
c.mu.Lock()
defer c.mu.Unlock()
return c.n
}
如果只是单个计数器,atomic.Int64 更轻:
type Counter struct {
n atomic.Int64
}
func (c *Counter) Inc() { c.n.Add(1) }
func (c *Counter) Value() int64 { return c.n.Load() }
但我不建议看到 race 就无脑 atomic。atomic 适合简单数值状态;一旦涉及多个字段一致性、map 更新、状态机流转,锁或 channel ownership 更容易写对。尤其是订单状态、库存快照、连接池元信息这种业务对象,正确性比少一次锁开销重要。

线上项目里,我会重点查这些位置
第一类是缓存和 map。Go 的 map 并发读写不安全,轻则 race detector 报告,重则直接 panic。只要 map 被多个 goroutine 访问,就要明确保护策略:sync.RWMutex、sync.Map、拷贝后替换,或者单 goroutine 管理。
第二类是请求上下文之外启动的 goroutine。比如 HTTP handler 里起异步任务,闭包里引用了请求对象、响应对象、循环变量或临时 buffer。handler 返回以后,这些对象可能被复用或继续修改,race 就藏在这里。
第三类是对象池。sync.Pool 本身是并发安全的,但你从池里拿出来的对象不是自动安全的。对象归还后还有 goroutine 持有引用,下一次被别人拿走修改,就会出现很难看的数据污染。
CI 怎么接:失败就阻断,不要只存日志
我的建议是:核心包每次合并都跑 go test -race,全量包可以定时跑。对耗时特别大的项目,可以先筛出并发密集模块,比如缓存、任务队列、连接池、限流器、状态机、RPC 客户端。
go test -race ./internal/cache ./internal/order ./pkg/worker
有些团队只把 race 报告作为 artifact 保存,构建还显示成功,这个意义不大。race detector 抓到数据竞争时,我更倾向于让 CI 直接失败。因为数据竞争不是“代码风格问题”,它就是潜在生产事故。
几个容易误判的点
-race没报不代表没有竞争,它只能检测执行到的路径。- 给测试加
time.Sleep不是复现策略,稳定复现应该靠并发门闩、循环次数和明确触发条件。 - 修复时不要只保护写,读也要在同一套同步规则里。
- 不要把所有状态都塞进一个全局锁,先缩小共享范围,再决定锁、atomic 还是 channel。
我的上线检查清单
- 出问题的包是否有最小复现测试,并能被
go test -race抓住。 - 修复后是否再次运行
-race,并覆盖真实并发路径。 - 共享变量的所有读写是否经过同一种同步机制。
- 异步 goroutine 是否还引用请求生命周期内的对象。
- CI 是否把 race 结果作为阻断条件,而不是仅仅打印日志。
最后聊两句
Go 的并发写起来很顺手,但顺手不等于安全。race detector 最适合挡住那种“平时没事,高峰偶发”的问题。它不会替你设计并发模型,却能逼你面对共享状态。
我的经验是:能不共享就不共享;必须共享就把所有权写清楚;上线前用 -race 跑真实路径。别等数据错了再补锁,那时候你修的不只是代码,还有用户和业务对系统的信任。




