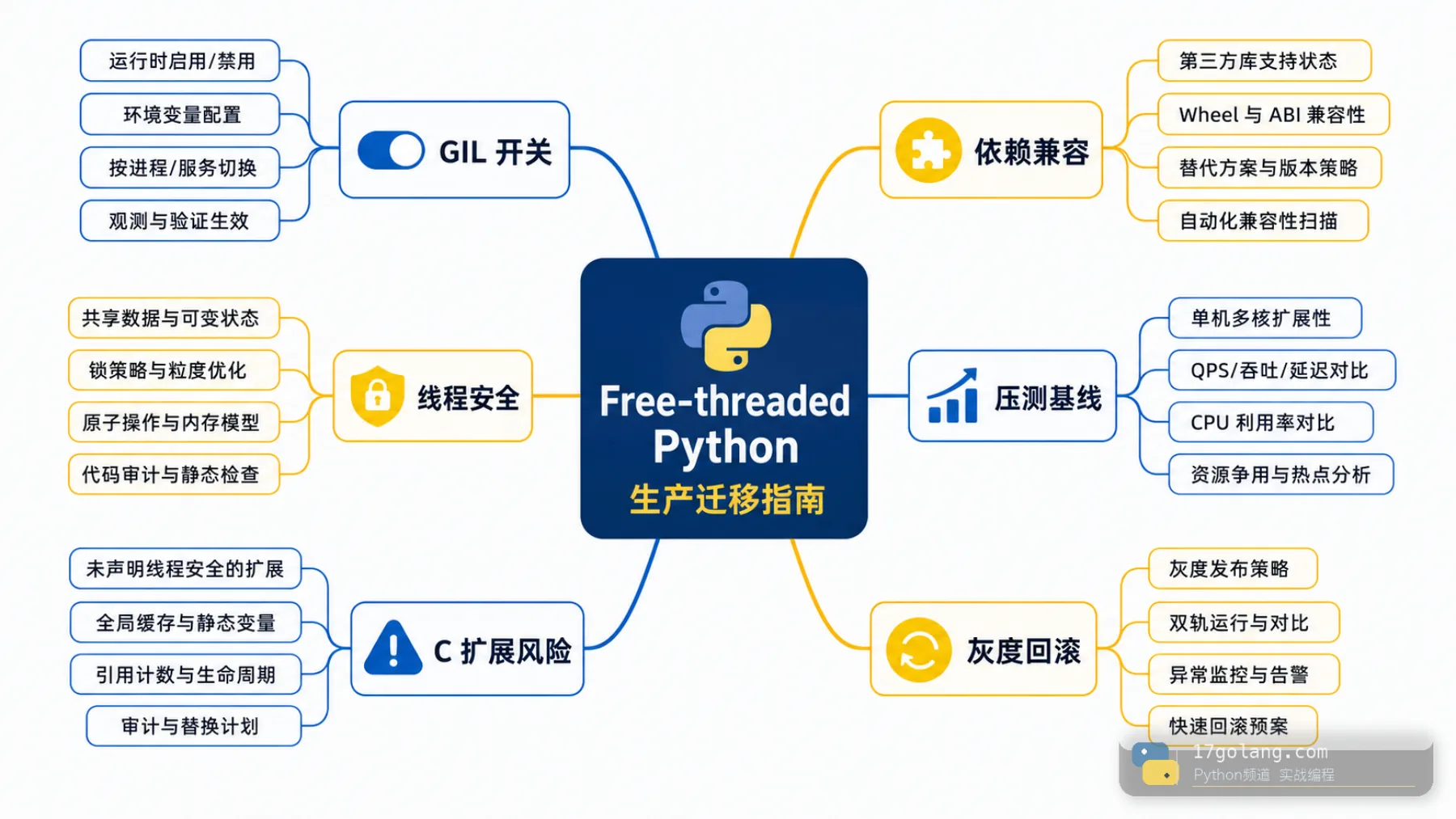
Python 3.13 之后,free-threaded CPython 终于让很多团队重新讨论“能不能在线上关掉 GIL”。但我会先泼一盆冷静水:这不是一个把开关打开就能提速的功能,它更像一次生产迁移。你要确认依赖、C 扩展、共享状态、压测基线和回滚路径,不然多核没吃到,数据竞争先冒出来。
这篇文章按生产迁移视角来写。官方文档里 free-threaded Python 的重点很清楚:它允许在特定构建下禁用 GIL,但也要求代码和扩展重新面对线程安全问题。我的建议是,别把它当成性能玄学,而是当成一次带风险的并发架构改造。
先判断:你的瓶颈真的是 GIL 吗
我见过不少团队一听“无 GIL”就兴奋,但线上接口慢的原因可能是数据库、网络、锁等待、序列化、日志阻塞,甚至是连接池配置。free-threaded 构建主要帮你处理 CPU 密集、多线程能并行执行 Python 字节码的场景。如果服务大部分时间都在等 I/O,效果未必明显。
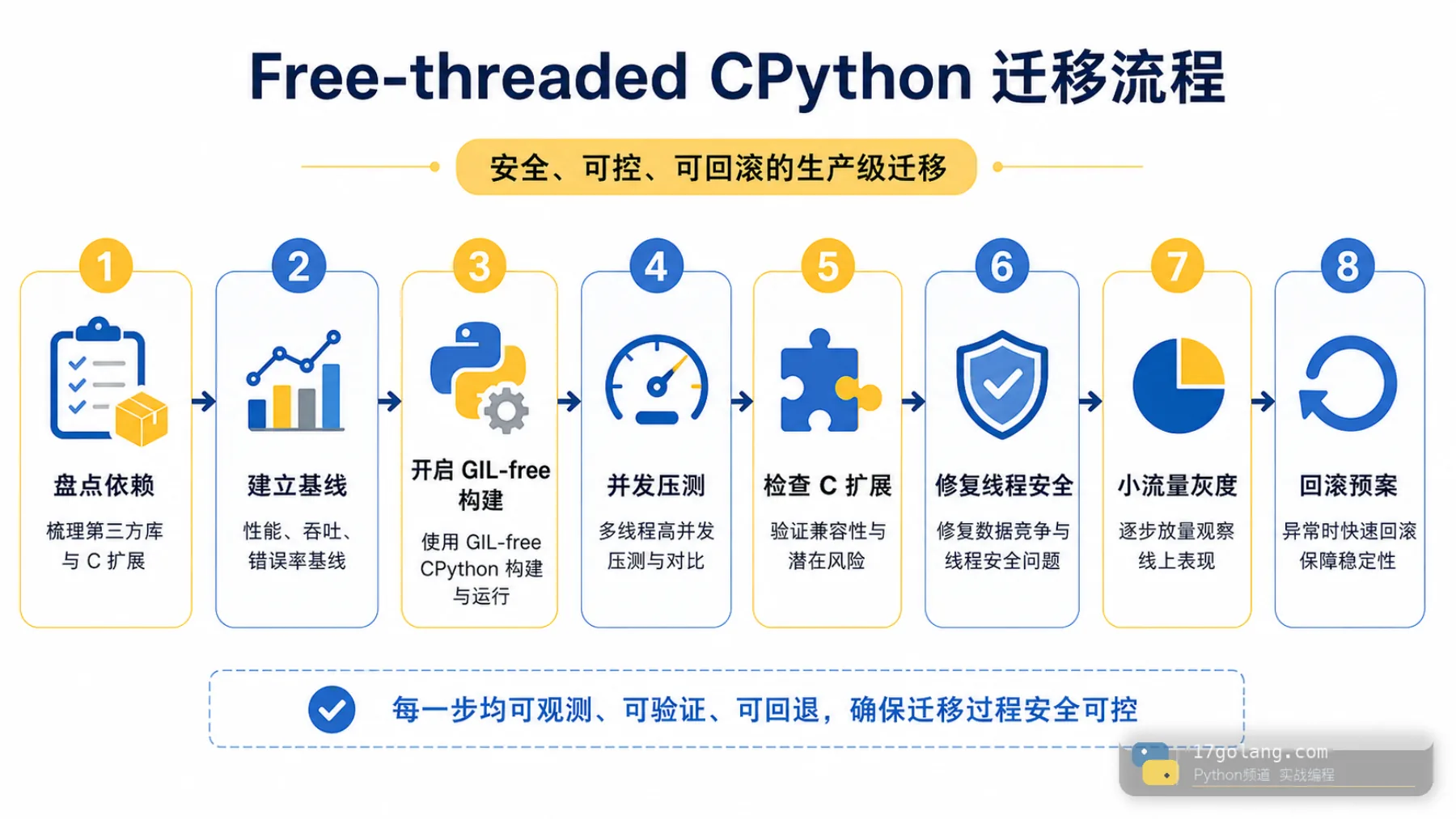
上线前先建立基线:单线程、多线程、进程池、当前生产版本、free-threaded 构建分别跑同一套压测。指标至少看吞吐、P95/P99、CPU 利用率、内存、错误率和上下文切换。没有基线,所谓“提速”很容易只是样本错觉。
依赖兼容比开关更重要
Python 项目很少只有纯 Python 代码。NumPy、pandas、cryptography、lxml、数据库驱动、压缩库、图像库、RPC 库,都可能包含 C 扩展或底层状态。free-threaded 环境下,扩展是否声明兼容、内部是否依赖 GIL 保护、有没有全局缓存,都会影响稳定性。
python -VV python -c "import sys; print(getattr(sys, '_is_gil_enabled', lambda: 'unknown')())" python -m pip freeze > requirements.lock
我的迁移做法是先列一张依赖表:包名、版本、是否 C 扩展、是否有 free-threaded 说明、是否覆盖核心链路、是否能替换或回滚。不要等压测炸了才回头猜是哪一个包。
最危险的是“以前靠 GIL 刚好没出事”
很多老代码有一个隐形前提:多个线程虽然会切换,但 GIL 让一些共享状态访问看起来没那么容易出事。free-threaded 之后,这个侥幸会变少。全局 dict、单例缓存、懒加载对象、计数器、内存队列、可变配置,都要重新审查。
# 风险写法:多个线程同时改共享状态
stats = {}
def incr(name: str) -> None:
stats[name] = stats.get(name, 0) + 1
这段代码在旧环境里也不是严谨的线程安全代码,只是很多时候没暴露。迁移时我会明确加锁、使用队列收口,或者把共享状态改成不可变快照。
from threading import Lock
stats = {}
stats_lock = Lock()
def incr(name: str) -> None:
with stats_lock:
stats[name] = stats.get(name, 0) + 1
代码审查要盯共享状态
free-threaded 迁移不是只给性能工程师看的事,业务代码 review 也要变。看到全局变量、模块级缓存、后台线程、线程池回调、单例对象,我都会问一句:这里有没有并发写?有没有跨请求共享?有没有靠初始化顺序保证安全?

上线检查清单
- 确认运行时版本、构建参数和 GIL 状态,不要只看 Python 版本号。
- 列出关键依赖,标注 C 扩展和 free-threaded 兼容性。
- 用同一套 workload 对比当前版本、进程池方案和 free-threaded 方案。
- 审查全局可变状态、单例缓存、懒加载对象和后台线程。
- 压测时观察吞吐、P99、CPU、内存、错误率和数据一致性。
- 灰度只放 CPU 密集链路,保留一键回滚到普通 CPython 的方案。
结语
free-threaded CPython 是 Python 生态很重要的一步,但工程上不能把它神化。它给了 CPU 密集型多线程代码新的可能,也把以前被 GIL 遮住的一些线程安全问题推到台前。
我的建议是:先用数据证明瓶颈,再用依赖表控制风险,最后用小流量灰度验证收益。能这样推进,free-threaded 才可能是生产优化,而不是一次靠运气的冒险。




