FastAPI 项目里,Pydantic v2 的校验通常不是第一眼能看见的瓶颈。接口 P95 慢了,大家会先怀疑数据库、网络、缓存,最后火焰图一拉才发现:请求体解析、模型构建、重复创建校验器,正在悄悄吃掉 CPU。
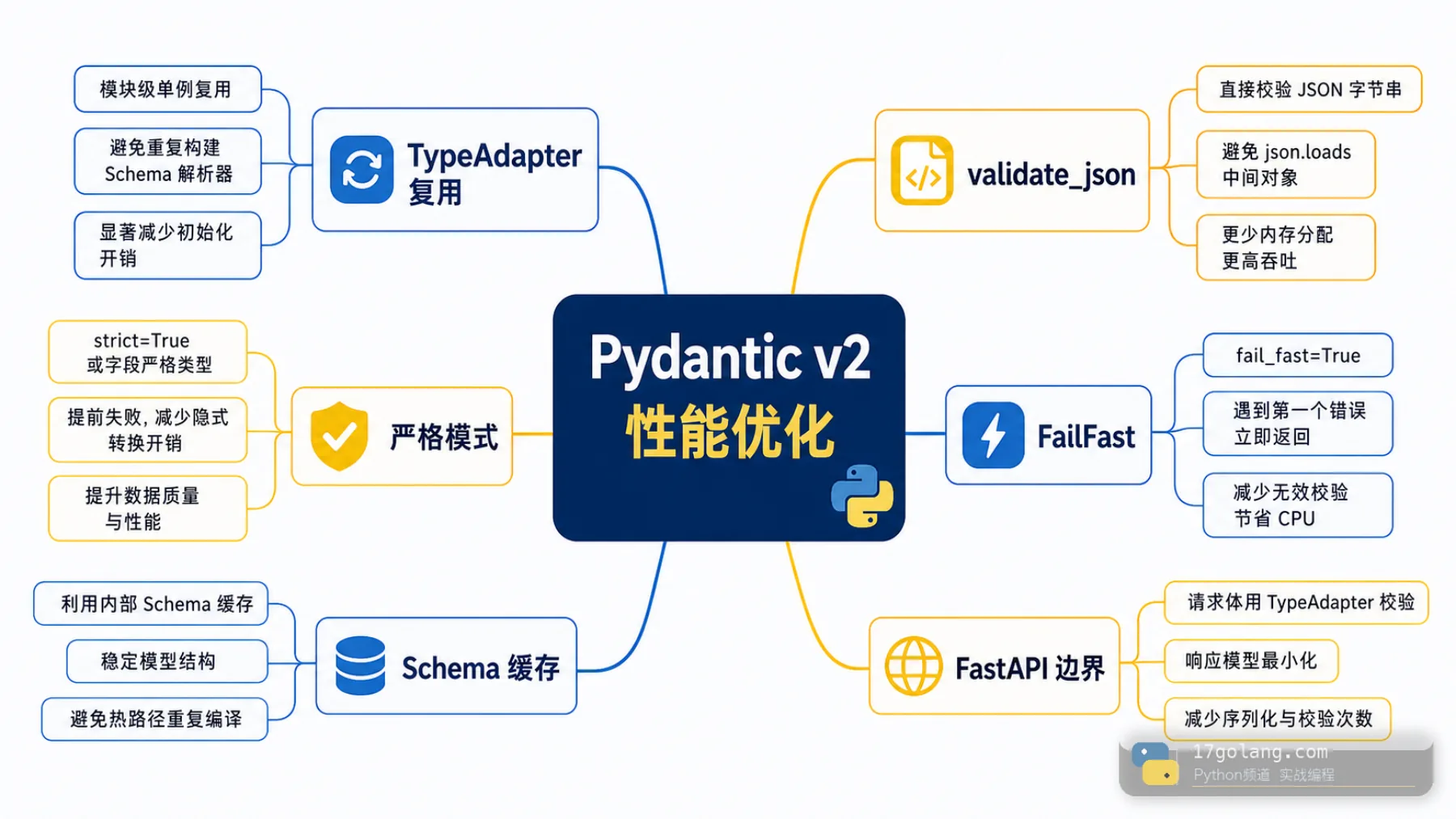
这篇聊一个很具体的优化点:Pydantic v2 里如何用 TypeAdapter 复用校验器,用 validate_json 避免多余中间对象,并把优化放进可验证的生产流程里。官方性能文档里提到的建议很直接:TypeAdapter 应尽量实例化一次并复用,JSON 数据优先考虑 model_validate_json() 或 validate_json() 路径。工程上真正难的是知道它适合放在哪里。
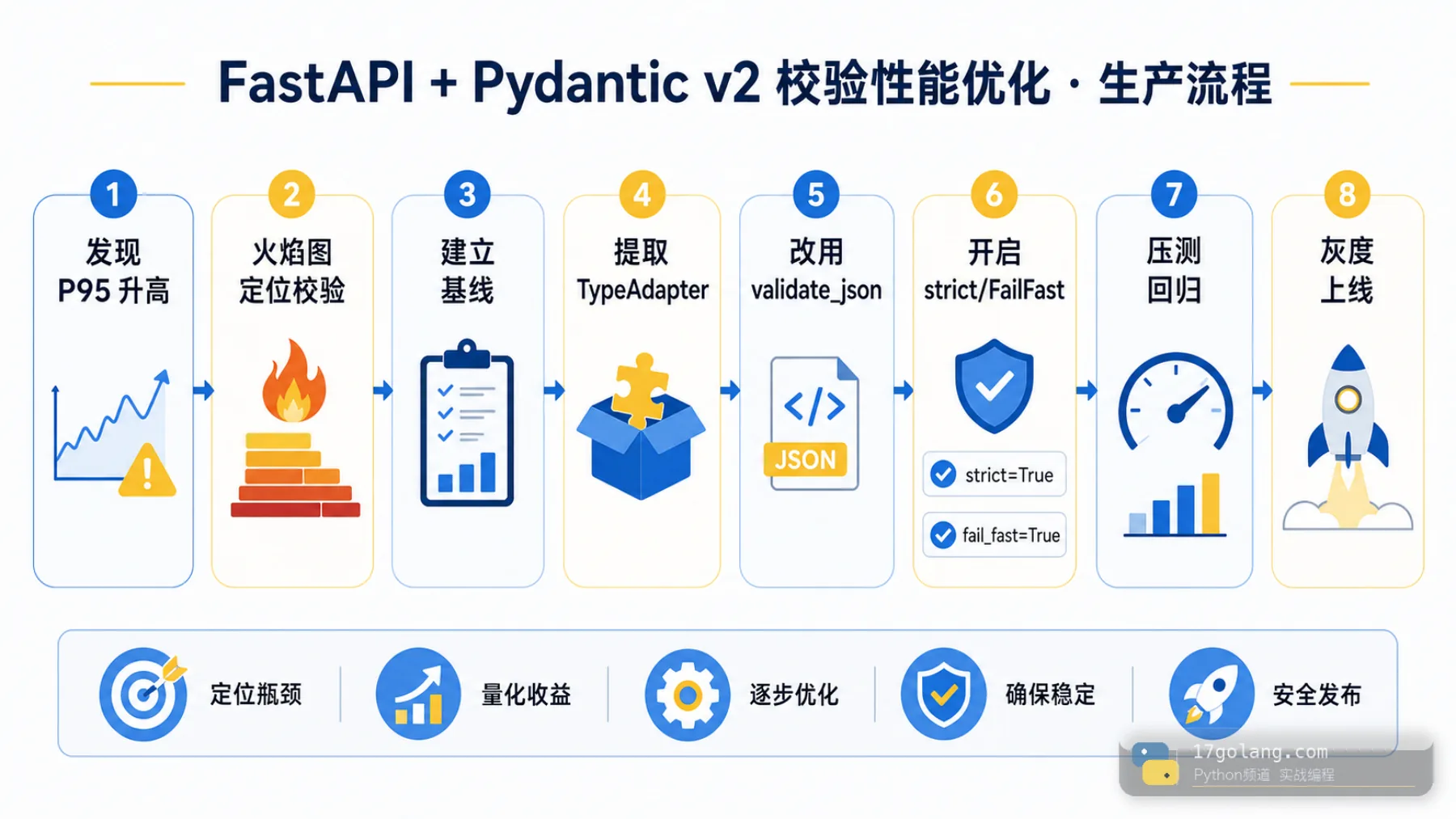
先别急着改代码,先证明校验真的慢
我会先拿一条典型链路做基线:请求体大小、字段数量、嵌套层级、批量条数、P95/P99、CPU profile、内存分配。只有火焰图里校验和模型构建占比明显,才值得动 Pydantic 这层。
如果数据库耗时 200ms,校验耗时 1ms,优化 TypeAdapter 只是锦上添花;如果批量导入接口每次解析几千条数据,重复构建 schema 和中间 dict 就很可能变成主菜。
容易出事的写法:每次请求都构建 TypeAdapter
from pydantic import TypeAdapter
async def import_users(request):
raw = await request.body()
data = json.loads(raw)
adapter = TypeAdapter(list[UserIn])
users = adapter.validate_python(data)
return await save_users(users)
这段代码能跑,但每次请求都重新构造 TypeAdapter,等于反复准备校验器。数据先 json.loads 成 Python 对象,再校验,也会多出中间对象和内存压力。
更适合生产的写法:模块级复用 + validate_json
from pydantic import TypeAdapter
USERS_ADAPTER = TypeAdapter(list[UserIn])
async def import_users(request):
raw = await request.body()
users = USERS_ADAPTER.validate_json(raw)
return await save_users(users)
把 TypeAdapter 放到模块级或应用启动阶段初始化,适合 schema 稳定的高频路径。validate_json 直接吃 JSON 字节,减少一次手动解析。注意,这不是让你把所有代码都写成全局对象,而是把稳定、无状态、可复用的校验器放到热路径外。
strict 和 FailFast 要按业务场景开
严格模式能减少一些模糊转换,也让错误更早暴露,但会改变输入兼容性。FailFast 适合批量导入这类“遇到第一处错误就终止”的场景,不适合需要一次返回完整错误列表的表单接口。
我的经验是:内部 API、批处理、队列消费可以更激进;公开接口和历史兼容链路要谨慎灰度,先看错误率和用户输入分布。

上线检查清单
- 确认瓶颈来自 Pydantic 校验,而不是数据库或下游 I/O。
- 高频 schema 的 TypeAdapter 是否只构建一次并复用?
- JSON 请求体是否可以直接走 validate_json 路径?
- strict、FailFast 是否会改变业务错误返回?
- 压测是否覆盖小对象、大对象、批量对象和错误数据?
- 监控是否包含 P95/P99、CPU、内存分配和 4xx 错误率?
结语
Pydantic v2 已经很快,但热路径里“重复构建”和“多余中间对象”仍然会让性能掉下去。优化的关键不是背 API,而是把校验放进完整链路里看:哪里重复、哪里分配、哪里能复用、哪里会改变兼容性。
能用数据证明收益,再小范围灰度上线,这样的 Pydantic 优化才算真正落地。




