有一次订单库磁盘告警,大家第一反应是“是不是 binlog 没清”“是不是大表写太多”。结果一看 InnoDB 状态,真正刺眼的是 History list length 已经涨到几百万,undo 表空间也在持续变大。最后追到根因,是一个报表连接开了事务后跑了三个多小时,一直没提交,purge 被它死死拖住。
这类问题很典型:写入还在继续,旧版本却不能回收,表面像磁盘、IO、慢 SQL,底层其实是 MVCC 旧版本堆积。MySQL 8.4 里相关配置包括 innodb_purge_threads、innodb_max_purge_lag 和 innodb_max_purge_lag_delay,但我的经验是,先找长事务,再谈参数。
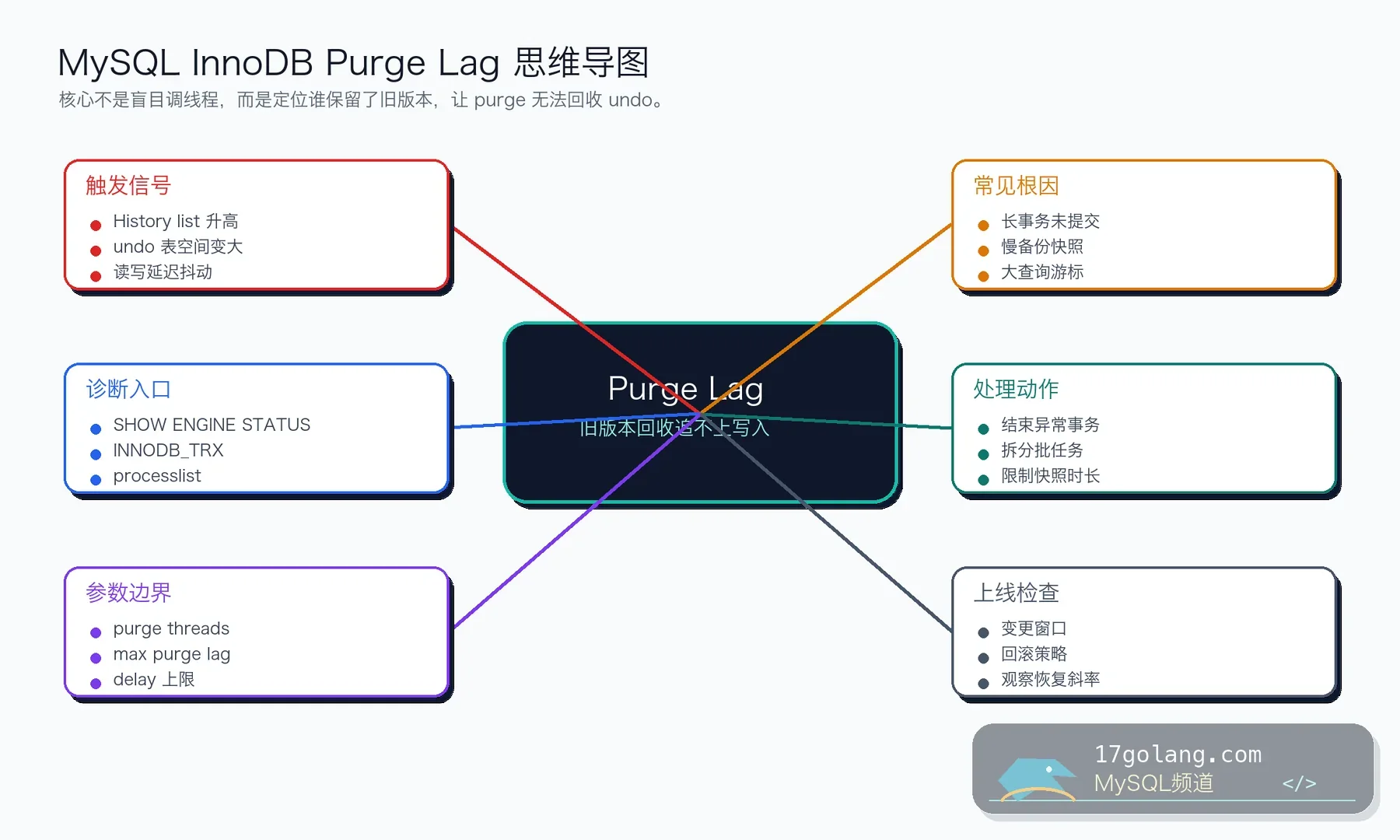
先解释一下 History list length
InnoDB 的 MVCC 会为事务保留旧版本。事务提交后,这些旧版本不是马上消失,而是由后台 purge 线程清理。如果有很老的 read view 还活着,InnoDB 就必须保留它可能读到的旧版本,history list 会越积越长。
所以 History list length 不是“越大就一定立刻出事故”的单点指标,但如果它持续上升,同时 undo 表空间增长、写入延迟抖动、检查点压力变大,就要认真排查了。
第一步:确认它是不是持续增长
我通常先连续采样 SHOW ENGINE INNODB STATUS\G,看 history list 是不是一直往上爬。单次尖峰不一定需要立刻动刀,持续增长才说明 purge 追不上或者被旧事务卡住。
SHOW ENGINE INNODB STATUS\G -- 重点看 TRANSACTIONS 区域 -- History list length 2840000
如果增长很快,先别急着调大 purge 线程。旧版本被长事务 pin 住时,线程再多也回收不了。这时候最有效的是找到最老事务。

第二步:抓最老事务
information_schema.INNODB_TRX 是最直接的入口。按事务开始时间排序,先看最老的几个事务,再用线程 id 关联 SHOW FULL PROCESSLIST,通常就能看到是哪台机器、哪个账号、哪条 SQL 或哪个任务在拖着。
SELECT trx_id,
trx_started,
trx_state,
trx_mysql_thread_id,
trx_query
FROM information_schema.INNODB_TRX
ORDER BY trx_started
LIMIT 10;
SHOW FULL PROCESSLIST;
如果看到一个事务跑了几个小时,SQL 还是普通 SELECT,大概率是业务连接池里有人关掉了 autocommit 后没提交,或者报表/备份工具开了一致性快照后迟迟不结束。

第三步:处置前先确认业务风险
不要看到长事务就直接 KILL。先确认它是不是备份、数据迁移、账务批处理、报表导出这类有业务语义的任务。能让应用主动提交或停止最好,不能的话再评估 kill 连接的影响。
-- 确认连接来源和当前 SQL 后再执行 KILL 123456;
长事务解除后,history list 不会瞬间清零。要观察它的下降斜率、undo 表空间是否停止增长、业务延迟是否恢复。如果写入仍然很猛,purge 追赶需要时间。
参数怎么调才不乱
innodb_purge_threads 可以提高并行 purge 能力,但不是所有场景都靠它解决。写入压力大、旧版本能正常释放时,它有价值;长事务挡住旧版本时,先解决事务生命周期。
innodb_max_purge_lag 和 innodb_max_purge_lag_delay 更像保护阀:当 purge lag 超过阈值时,对 DML 做延迟,让后台清理有机会追上。这个参数要谨慎,因为它会直接影响写入接口延迟。
SHOW VARIABLES LIKE 'innodb_purge_threads'; SHOW VARIABLES LIKE 'innodb_max_purge_lag%';
我会加的上线保护
- 应用侧设置事务最长执行时间,报表和导出任务不能无限持有事务。
- 连接池归还连接前确认事务状态,避免把未提交事务放回池里。
- 监控 history list length 的趋势,而不是只看单点阈值。
- 把
INNODB_TRX中超过阈值的事务打到告警里,包含账号、主机、线程 id。 - 大批量更新拆批提交,别让单个事务积累大量 undo。
- 备份、报表、迁移任务使用独立账号,方便快速识别和限流。
我的经验结论
Purge lag 很少是一个单纯参数问题。它通常是事务生命周期管理、报表查询、批处理和 InnoDB MVCC 交织出来的问题。最可靠的排查顺序是:确认 history list 趋势,找到最老事务,判断业务来源,安全处置,再观察 purge 追赶。
如果你只记一句话:undo 暴涨时,不要先怪磁盘,也不要先调线程,先抓住那个让旧版本不能被回收的长事务。




