MySQL 8.4 锁等待治理实战:NOWAIT 和 SKIP LOCKED 怎么用才不乱
来源:17golang MySQL频道原创
时间:2026-06-04 13:28:00 439浏览 收藏
先把话说清楚:锁等待不是只能等到超时
很多 MySQL 线上问题表面看是慢查询,实际是事务在等锁。尤其是任务领取、工单抢占、库存预占这类高并发接口,所有请求都盯着同一批热行,一旦前面的事务没提交,后面的事务就排队。排队时间长了,接口 P99、连接池、线程数都会被拖住。
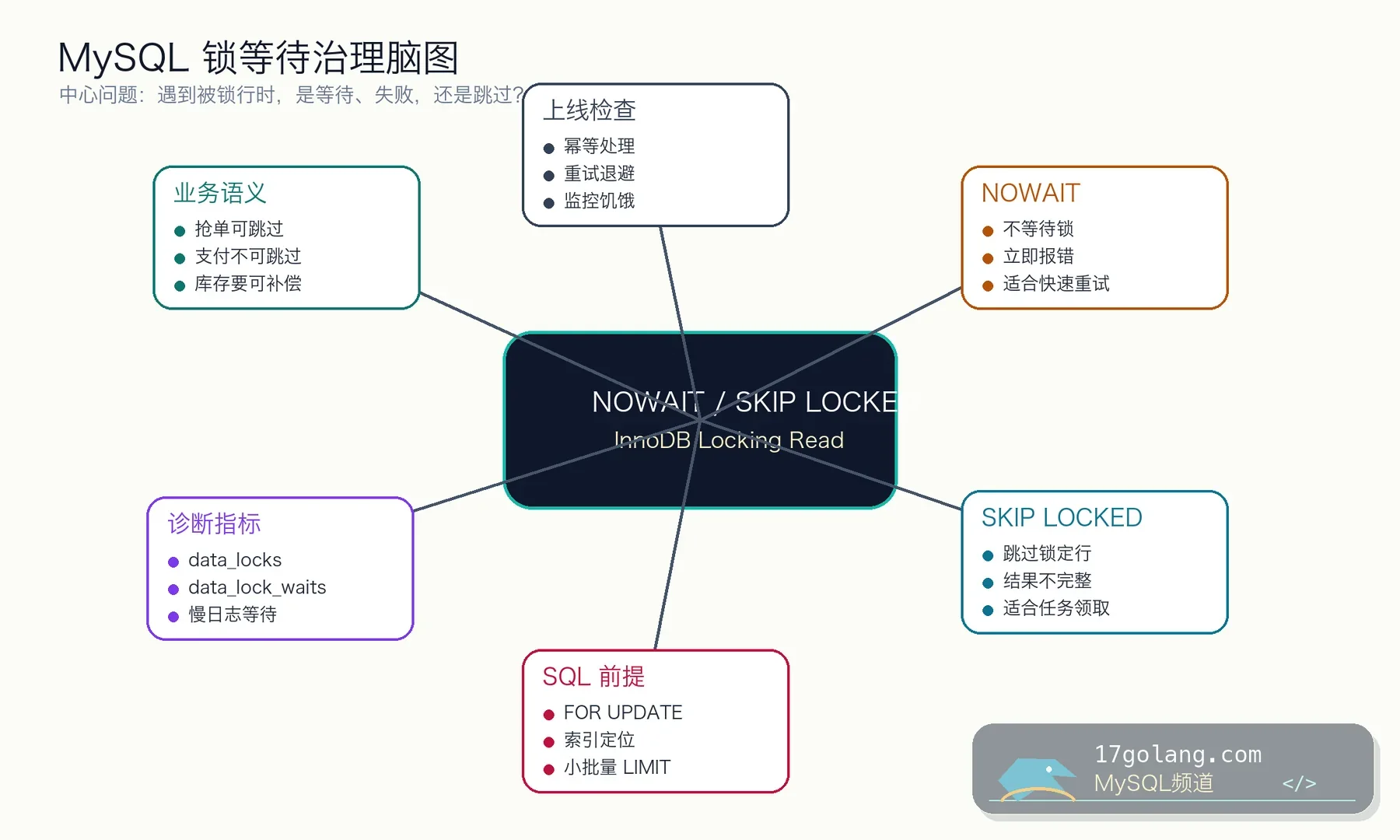
MySQL 8.x 的 InnoDB locking read 支持 NOWAIT 和 SKIP LOCKED。它们不是性能魔法,而是两种明确的业务选择:遇到被锁行时,NOWAIT 选择立即失败,SKIP LOCKED 选择跳过已锁定行继续找下一批。
业务场景:工单抢占为什么越抢越慢
假设有一张工单表,多个 worker 并发领取待处理任务:
CREATE TABLE jobs ( id BIGINT PRIMARY KEY, status VARCHAR(16) NOT NULL, priority INT NOT NULL, locked_by VARCHAR(64) DEFAULT NULL, updated_at DATETIME NOT NULL, KEY idx_pick (status, priority, id) ) ENGINE=InnoDB;
最朴素的写法是先锁住一批 READY 工单,再更新为处理中:
START TRANSACTION; SELECT id FROM jobs WHERE status = 'READY' ORDER BY priority DESC, id LIMIT 10 FOR UPDATE; UPDATE jobs SET status = 'RUNNING', locked_by = 'worker-7' WHERE id IN (...); COMMIT;
这个 SQL 语义没错,但在多个 worker 同时执行时,很容易一起堵在相同的前 10 行上。一个事务拿到锁,其他事务等锁。等锁期间连接不释放、事务不结束、线程池继续被占用,最后看起来像数据库整体变慢。
问题复现:两个会话就能看出差异
会话 A 先锁住一行但不提交:
START TRANSACTION; SELECT id FROM jobs WHERE id = 101 FOR UPDATE;
会话 B 如果普通等待,会卡住直到 A 提交或等到 innodb_lock_wait_timeout:
SELECT id FROM jobs WHERE id = 101 FOR UPDATE;
如果业务希望“拿不到就立刻返回”,用 NOWAIT:
SELECT id FROM jobs WHERE id = 101 FOR UPDATE NOWAIT;
如果业务希望“这行有人处理了,我去拿下一批”,用 SKIP LOCKED:
SELECT id FROM jobs WHERE status = 'READY' ORDER BY priority DESC, id LIMIT 10 FOR UPDATE SKIP LOCKED;

什么时候用 NOWAIT
NOWAIT 适合那些“必须处理指定行,但不愿意把请求挂住”的场景。比如后台管理页点一次“锁定订单”,如果这行正在被另一个事务处理,直接告诉用户稍后重试,比让 HTTP 请求卡几十秒更友好。
START TRANSACTION; SELECT id, status FROM orders WHERE id = 900001 FOR UPDATE NOWAIT; -- 拿到锁才继续做状态迁移 UPDATE orders SET status = 'CONFIRMING' WHERE id = 900001; COMMIT;
它的关键是应用层要把错误当成可预期分支处理,而不是一股脑打成数据库故障。我的经验是给这类错误加短退避重试,最多重试一两次,超过就返回“资源繁忙”。
什么时候用 SKIP LOCKED
SKIP LOCKED 最适合任务队列和批量领取:任务 A 被 worker-1 锁住,worker-2 没必要等它,可以跳过后继续拿任务 B、C、D。这样吞吐通常会比排队等待稳定很多。
START TRANSACTION; SELECT id FROM jobs FORCE INDEX (idx_pick) WHERE status = 'READY' ORDER BY priority DESC, id LIMIT 20 FOR UPDATE SKIP LOCKED; UPDATE jobs SET status = 'RUNNING', locked_by = 'worker-2', updated_at = NOW() WHERE id IN (...); COMMIT;
但它有一个非常重要的副作用:查询结果是不完整视图。它会跳过被锁住的行,所以不适合“必须准确看到所有符合条件的数据”的业务。报表、强一致扣减、指定订单处理,都不要轻易用它。

诊断锁等待:不要只等 timeout
线上排查时,我会先查 performance_schema 的锁表,确认到底是谁等谁。MySQL 8.x 里可以从 data_locks 和 data_lock_waits 看到锁等待关系:
SELECT w.REQUESTING_ENGINE_TRANSACTION_ID AS waiting_trx, w.BLOCKING_ENGINE_TRANSACTION_ID AS blocking_trx, r.OBJECT_SCHEMA, r.OBJECT_NAME, r.INDEX_NAME, r.LOCK_TYPE, r.LOCK_MODE FROM performance_schema.data_lock_waits w JOIN performance_schema.data_locks r ON w.REQUESTING_ENGINE_LOCK_ID = r.ENGINE_LOCK_ID;
如果等待集中在某个索引范围,通常要反查 SQL 的访问路径。没有合适索引时,FOR UPDATE 可能锁得比你想象中多;范围太大时,就算用了 SKIP LOCKED,扫描成本也会很难看。
踩坑原因:SKIP LOCKED 用错会制造饥饿
我见过最典型的坑是任务表永远按同一个排序领取,某些热任务长期被跳过,后面的任务一直被消费,前面的任务却因为反复冲突迟迟没人处理。这就是饥饿问题。
解决方式不是简单取消 SKIP LOCKED,而是给任务设计可恢复机制:任务领取超时后回到 READY,失败次数有上限,调度排序不能只盯着一个热分区,必要时按业务分片领取。
上线检查清单
- 确认业务能接受不等待或跳过锁定行。
- 确认 SQL 使用了足够窄的索引路径,避免大范围锁扫描。
- 领取任务必须幂等,事务提交前不要把外部副作用做死。
- 应用层区分锁冲突、死锁、普通 SQL 错误,重试策略不能一样。
- 监控等待事务数、任务积压、跳过比例、任务最长等待时间。
个人经验:这是并发控制工具,不是队列中间件
用 MySQL 做轻量任务领取完全可以,但要承认它的边界。SKIP LOCKED 能让多个 worker 少互相阻塞,却不会自动处理任务超时、失败重试、死信、优先级反转。你需要在表结构和应用逻辑里补上这些能力。
NOWAIT 也一样。它适合把“锁冲突”从长等待变成快速失败,但不能把冲突变没。真正的优化往往还包括缩短事务、减少热点行、按业务拆分队列、把长耗时操作挪出事务。
总结
MySQL 8.x 的 NOWAIT 和 SKIP LOCKED 可以显著改善高并发锁等待体验,但前提是你知道自己在牺牲什么。指定资源必须处理,用 NOWAIT 快速失败;任务池可以换一批处理,用 SKIP LOCKED 提升吞吐;强一致、完整结果、不可跳过的业务,老老实实等待或重新设计并发模型。
-

- 前端进阶之JavaScript设计模式
- 设计模式是开发人员在软件开发过程中面临一般问题时的解决方案,代表了最佳的实践。本课程的主打内容包括JS常见设计模式以及具体应用场景,打造一站式知识长龙服务,适合有JS基础的同学学习。
- 立即学习 543次学习
-

- GO语言核心编程课程
- 本课程采用真实案例,全面具体可落地,从理论到实践,一步一步将GO核心编程技术、编程思想、底层实现融会贯通,使学习者贴近时代脉搏,做IT互联网时代的弄潮儿。
- 立即学习 516次学习
-

- 简单聊聊mysql8与网络通信
- 如有问题加微信:Le-studyg;在课程中,我们将首先介绍MySQL8的新特性,包括性能优化、安全增强、新数据类型等,帮助学生快速熟悉MySQL8的最新功能。接着,我们将深入解析MySQL的网络通信机制,包括协议、连接管理、数据传输等,让
- 立即学习 500次学习
-

- JavaScript正则表达式基础与实战
- 在任何一门编程语言中,正则表达式,都是一项重要的知识,它提供了高效的字符串匹配与捕获机制,可以极大的简化程序设计。
- 立即学习 487次学习
-

- 从零制作响应式网站—Grid布局
- 本系列教程将展示从零制作一个假想的网络科技公司官网,分为导航,轮播,关于我们,成功案例,服务流程,团队介绍,数据部分,公司动态,底部信息等内容区块。网站整体采用CSSGrid布局,支持响应式,有流畅过渡和展现动画。
- 立即学习 485次学习