有一次线上接口突然开始抖,CPU 不高,数据库也没慢,但网关的 P95 一路往上爬。我们把 goroutine dump 拉下来一看,一批请求都卡在调用下游 HTTP 接口上。最扎心的是,代码看起来很朴素:http.Get(url)。没有超时,没有上下文,没有连接池边界,调用方只能陪着下游一起熬。
这篇不写成 API 手册。我按自己排查 Go 服务的习惯,把 HTTP 客户端超时这件事拆成一条生产链路:请求进来以后,预算从哪里来,http.Client 怎么复用,Transport 管哪些阶段,context 怎么传,重试怎么别把事故放大,最后上线前该看哪些指标。
先说事故:默认客户端最怕下游慢半拍
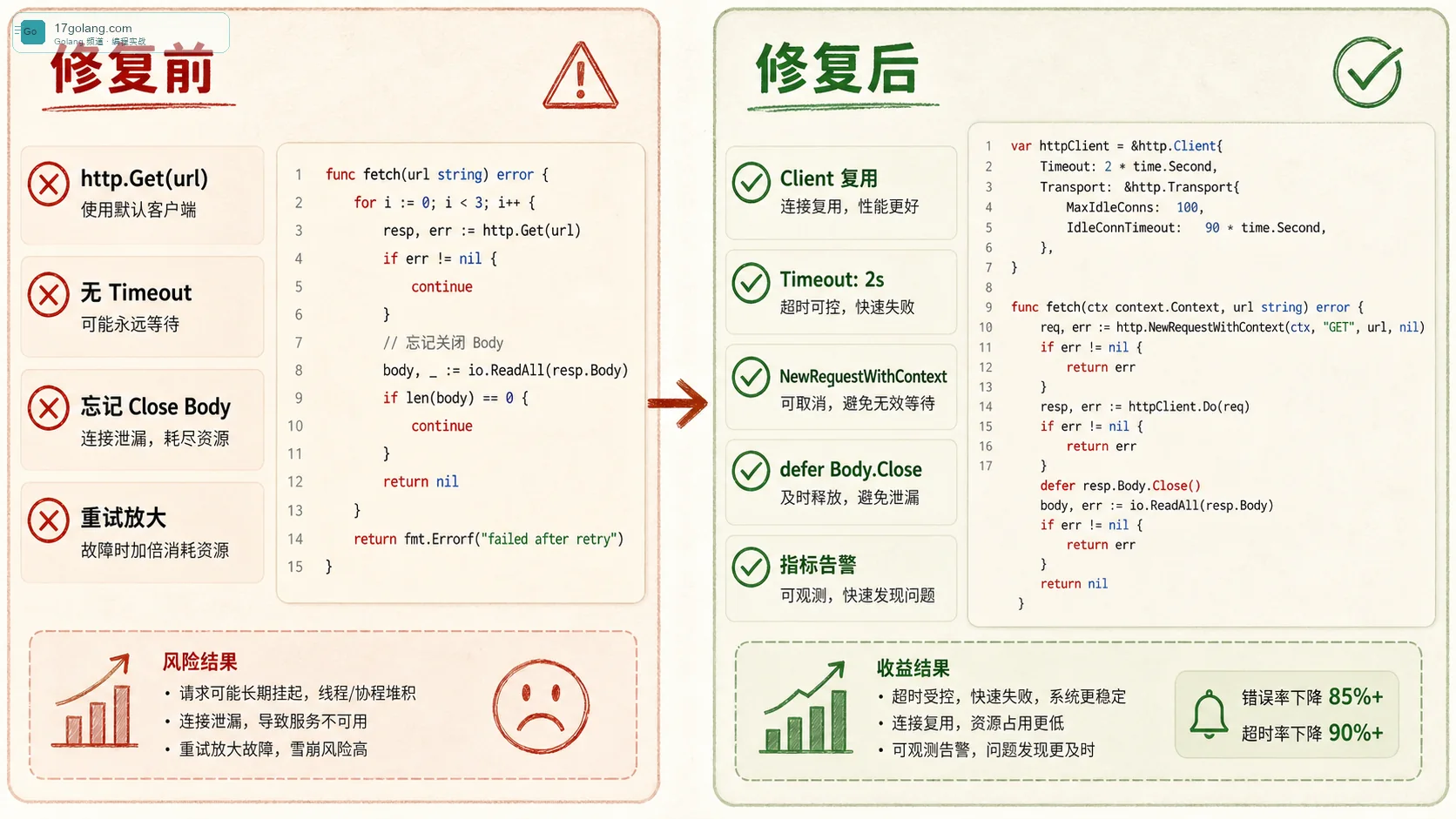
业务里最常见的写法是直接 http.Get,或者每次请求临时 new 一个 http.Client。本地调试当然没问题,下游服务健康、网络稳定、响应很快,你甚至感受不到风险。可一到线上,只要下游偶发卡住,调用方的 goroutine 就会被拖住;如果请求量还在进来,连接、内存、排队时间都会跟着涨。
Go 官方文档里有两个细节很关键:Client 可以被多个 goroutine 并发使用,应该复用;它里面的 Transport 通常也有内部状态和连接缓存,也应该复用。还有一个更容易被忽略的点:Client.Timeout 的零值表示不设置超时。也就是说,你不写超时,不是 Go 帮你选了一个合理默认值,而是它会等到网络层、服务端或者系统最终给结果。
坏写法:能跑,但没有退出边界
我见过不少线上代码长这样。它最大的问题不是短,而是没有给失败场景留出口:下游慢了怎么办?调用方取消了怎么办?响应体没关怎么办?重试会不会把时间预算打穿?这些问题在代码里都找不到答案。
func LoadPrice(sku string) ([]byte, error) {
resp, err := http.Get("https://price.internal/api?sku=" + sku)
if err != nil {
return nil, err
}
return io.ReadAll(resp.Body) // 忘记 Close,连接复用也会受影响
}
这段代码在压测报告里可能看不出问题,因为压测环境的下游很乖。但生产不是实验室。下游只要抖一下,你就会看到 goroutine 数量上升、请求耗时变长、连接池等待增加,最后用户看到的只是“偶发超时”。

我更愿意上线的写法:复用 Client,拆清预算
生产里我通常不会在每个函数里 new 客户端,而是在依赖层初始化一个可复用的 http.Client。总超时用 Client.Timeout 兜底;更细的阶段控制交给 Transport,比如 TLS 握手、等待响应头、空闲连接保留时间。然后每个请求再用调用链传下来的 context 控制业务预算。
var priceHTTPClient = &http.Client{
Timeout: 2 * time.Second,
Transport: &http.Transport{
MaxIdleConns: 100,
MaxIdleConnsPerHost: 20,
IdleConnTimeout: 90 * time.Second,
TLSHandshakeTimeout: 3 * time.Second,
ResponseHeaderTimeout: 800 * time.Millisecond,
ExpectContinueTimeout: 1 * time.Second,
},
}
真正发请求时,不要把后台任务、HTTP handler、RPC handler 的上下文丢掉。上游已经取消了,你还继续等下游,结果就是 goroutine 和连接被白白占着。context.WithTimeout 用完一定要 cancel(),这不是仪式感,而是释放计时器和相关资源。
func LoadPrice(ctx context.Context, sku string) ([]byte, error) {
ctx, cancel := context.WithTimeout(ctx, 1200*time.Millisecond)
defer cancel()
req, err := http.NewRequestWithContext(ctx, http.MethodGet,
"https://price.internal/api?sku="+url.QueryEscape(sku), nil)
if err != nil {
return nil, fmt.Errorf("new price request: %w", err)
}
resp, err := priceHTTPClient.Do(req)
if err != nil {
return nil, fmt.Errorf("call price service: %w", err)
}
defer resp.Body.Close()
if resp.StatusCode >= 500 {
return nil, fmt.Errorf("price service status: %d", resp.StatusCode)
}
return io.ReadAll(resp.Body)
}
Client.Timeout、Context、Transport 到底怎么分工
Client.Timeout 是客户端层面的总时间上限,从请求开始到响应体读取结束都算进去。它适合作为兜底,不适合替代业务预算。比如用户请求只剩 300ms 预算了,你不能因为客户端配置了 2s 就继续等满 2s。
Request Context 是调用链预算,适合表达“这个业务动作还值不值得继续”。HTTP handler 取消、RPC 调用取消、批任务被停止,都应该沿着 context 往下传。它的好处是统一,坏处是如果你到处新建背景 context,整条链路就断了。
Transport 更偏网络阶段和连接池。比如连接复用、空闲连接、等待响应头、TLS 握手,这些都和它有关。线上排查时,如果你发现大量请求卡在连接、握手或者等响应头,就不要只盯着业务代码,应该把 Transport 的配置和指标一起看。
重试不是越多越稳,别把 SLA 打穿
很多人修超时时会顺手加重试。重试本身没错,但它必须服从调用方预算。比如上游给你 1.5 秒,你每次请求 1 秒、重试 3 次,那不是容错,是把延迟债务往上游甩。我的习惯是先算总预算,再给每次尝试分配小预算,并且只对明确可重试的错误重试。
deadline := time.Now().Add(1500 * time.Millisecond)
for attempt := 1; attempt <= 2; attempt++ {
left := time.Until(deadline)
if left <= 200*time.Millisecond {
return nil, context.DeadlineExceeded
}
tryCtx, cancel := context.WithTimeout(ctx, min(left, 700*time.Millisecond))
data, err := LoadPrice(tryCtx, sku)
cancel()
if err == nil {
return data, nil
}
if !isTemporaryHTTPError(err) {
return nil, err
}
}
return nil, fmt.Errorf("price service retry exhausted")
上线前我会检查这些东西
- Client 是否复用:不要在热路径里每次 new 客户端和 Transport。
- 是否有总超时:零值超时要明确接受,不能无意识留空。
- Context 是否传递:不要在请求链路中随手用
context.Background()切断取消信号。 - Body 是否关闭:不关响应体,连接复用和资源释放都会出问题。
- 重试是否受预算约束:重试次数、单次超时、总耗时必须一起看。
- 指标是否够用:至少记录下游名、状态码、耗时分位、超时错误、重试次数和失败原因。
排障时我会先看什么
如果线上已经抖了,我不会第一时间改超时值。我会先看 goroutine 数量、HTTP 下游耗时、错误类型、连接池等待、响应头等待时间和最近变更。如果 CPU 不高但 goroutine 堆积,大概率不是计算慢,而是某个外部等待没有边界。
还有一个小经验:日志不要只打 request failed。至少把下游服务名、attempt、deadline、耗时、错误链打出来。否则你只能知道“失败了”,不知道是 DNS、连接、TLS、响应头、读取 body,还是 context 到期。
最后聊两句
Go 的 HTTP 客户端很稳,但稳不等于你可以不设边界。默认无超时、临时创建 Client、忘记关闭 Body、重试不看 SLA,这几个点单独看都不起眼,组合到高峰流量里就是一次很典型的线上事故。
我的建议是:把 HTTP 调用当成一个小型资源池来治理。复用客户端,传递 context,配置 Transport,关闭响应体,给重试套预算,再用指标证明它真的稳定。这样写出来的 Go 服务,才经得住下游慢半拍。




