这篇写一个 Java 后端线上最常见的盲区:日志没有 ERROR,接口却已经慢到用户能感知。等客服反馈再查日志,往往已经晚了。Spring Boot Actuator + Micrometer 的价值,就是让延迟、错误率、吞吐、JVM 状态先说话。
本文适用于 Java 17/21、Spring Boot 3.x、Actuator、Micrometer、Prometheus/Grafana 场景。资料只用于核对事实:Spring Boot 会自动接入 Micrometer 并生成如 http.server.requests 的 HTTP 指标,Micrometer Timer 支持直方图和百分位。正文按生产落地写,不复述官方手册。
业务场景:接口慢了,但日志一片正常
订单查询接口某天开始变慢,日志没有异常,数据库也没有明显报错。用户反馈“偶尔转圈”,研发看平均耗时还可以,直到 p99 拉出来才发现高峰时已经超过 1 秒。
这就是只看日志和平均值的问题。生产服务需要用指标观察分布:p95、p99、错误率、吞吐和下游耗时一起看,才能知道用户实际体验。
问题复现:平均值掩盖尖刺
假设 99 个请求 50ms,1 个请求 2s,平均值看起来仍然不吓人。但这个 2s 请求可能就是用户投诉的来源。Micrometer 的 Timer 适合记录短耗时事件,配合后端监控系统可以看百分位和直方图。
踩坑原因:指标有了,但不能行动
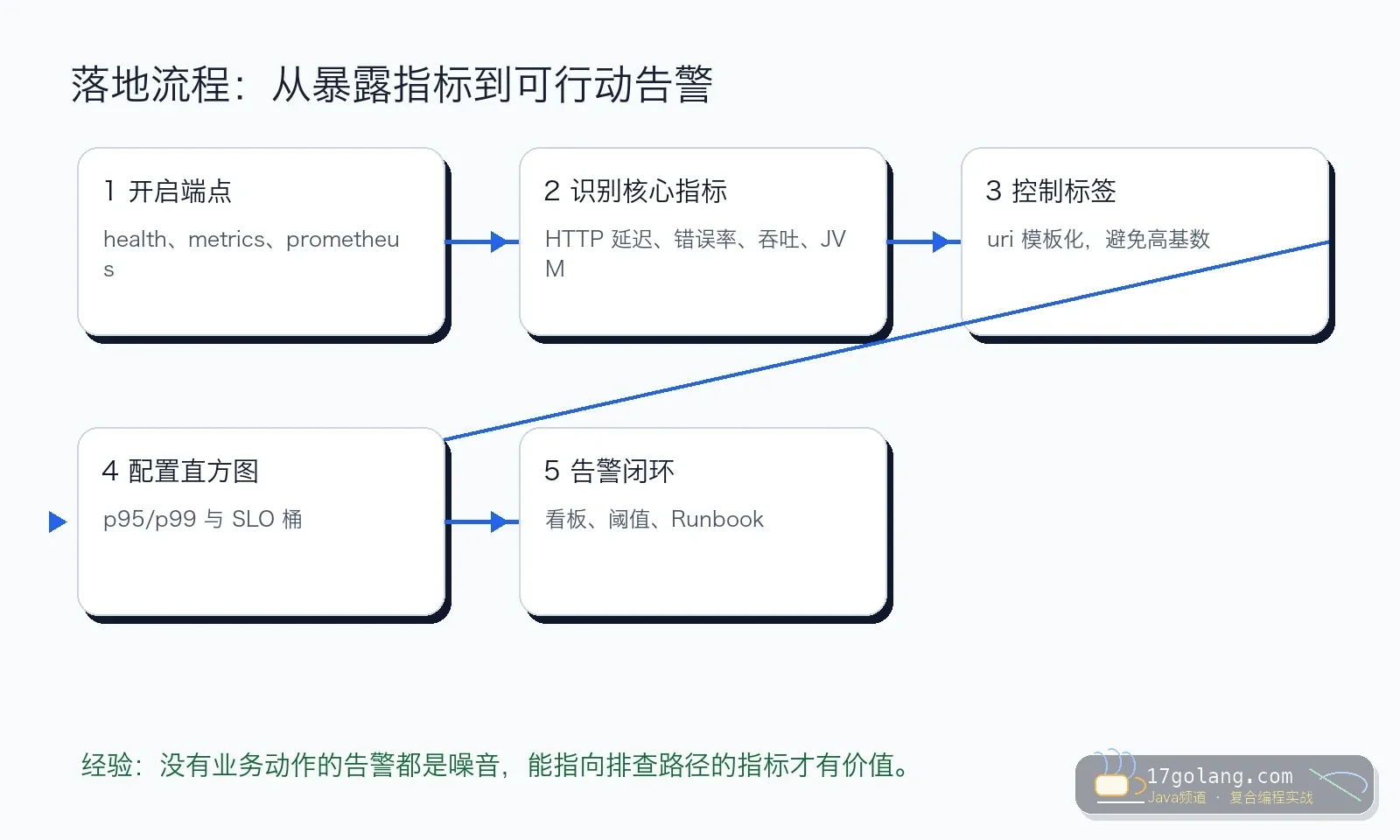
很多团队接了 Actuator,却只看 /actuator/health。真正有用的是能回答问题的指标:哪个 URI 慢?是 5xx 变多还是 2xx 变慢?是 JVM GC 抖动还是下游连接池耗尽?
另一个坑是标签失控。把 userId、orderId、完整 URL 这种高基数字段打进指标,会让监控系统时间序列爆炸,最后指标平台比业务服务先报警。
代码案例:低基数标签才适合进指标
下面这张图展示了一个典型错误:把订单号和用户 id 当 tag。指标标签要能聚合,适合放 result、type、uri 模板、exception 简类名这类低基数字段。

Timer timer = Timer.builder("order.query")
.description("订单查询耗时")
.tag("result", result)
.publishPercentileHistogram()
.serviceLevelObjectives(Duration.ofMillis(100), Duration.ofMillis(300), Duration.ofSeconds(1))
.register(meterRegistry);
timer.record(() -> orderService.query(orderNo));
如果你需要定位单个用户或订单,应该把这些信息放日志、trace 或事件里,而不是放指标 tag。指标负责发现趋势,日志和 trace 负责定位个体。
诊断步骤:慢接口我会这样看
第一步,看 http.server.requests。 按 URI、method、status/outcome 拆分,先确认是少数接口慢,还是整体都慢。
第二步,看错误率和流量。 延迟变高但错误率不变,往往是下游慢、线程池排队或 GC;错误率同步升高,则先看异常类型。
第三步,看 JVM 指标。 GC pause、线程数、内存、CPU 要和 HTTP 延迟对齐时间线。
第四步,看连接池和下游。 DataSource、HTTP client、缓存客户端、消息客户端指标能帮你判断瓶颈是不是在外部依赖。
第五步,看自定义业务指标。 例如订单查询命中缓存率、价格计算耗时、库存接口结果分布,这些比泛泛的 CPU 更接近业务根因。
上线检查:告警要能指导动作
- Actuator 端点只暴露必要项,生产要做好认证、网络隔离和脱敏。
- 核心接口配置 p95/p99、错误率、吞吐三类告警。
- 指标标签控制低基数,禁止 userId、orderId、完整 URL。
- 每条告警都要有 Runbook:看哪个面板、查哪类日志、找哪个负责人。
- 灰度发布时对比新旧版本的延迟分布,而不是只看平均耗时。
我的经验总结
Actuator 和 Micrometer 不是装上依赖就完事。真正难的是定义一套能行动的指标:发现问题要早,定位方向要准,告警噪音要低。
我建议每个 Java 服务至少有四张核心看板:HTTP 延迟和错误率、JVM、连接池/下游依赖、业务关键路径。日志告诉你发生了什么,指标告诉你什么时候开始变坏。两者合起来,才像一个可靠的生产系统。




