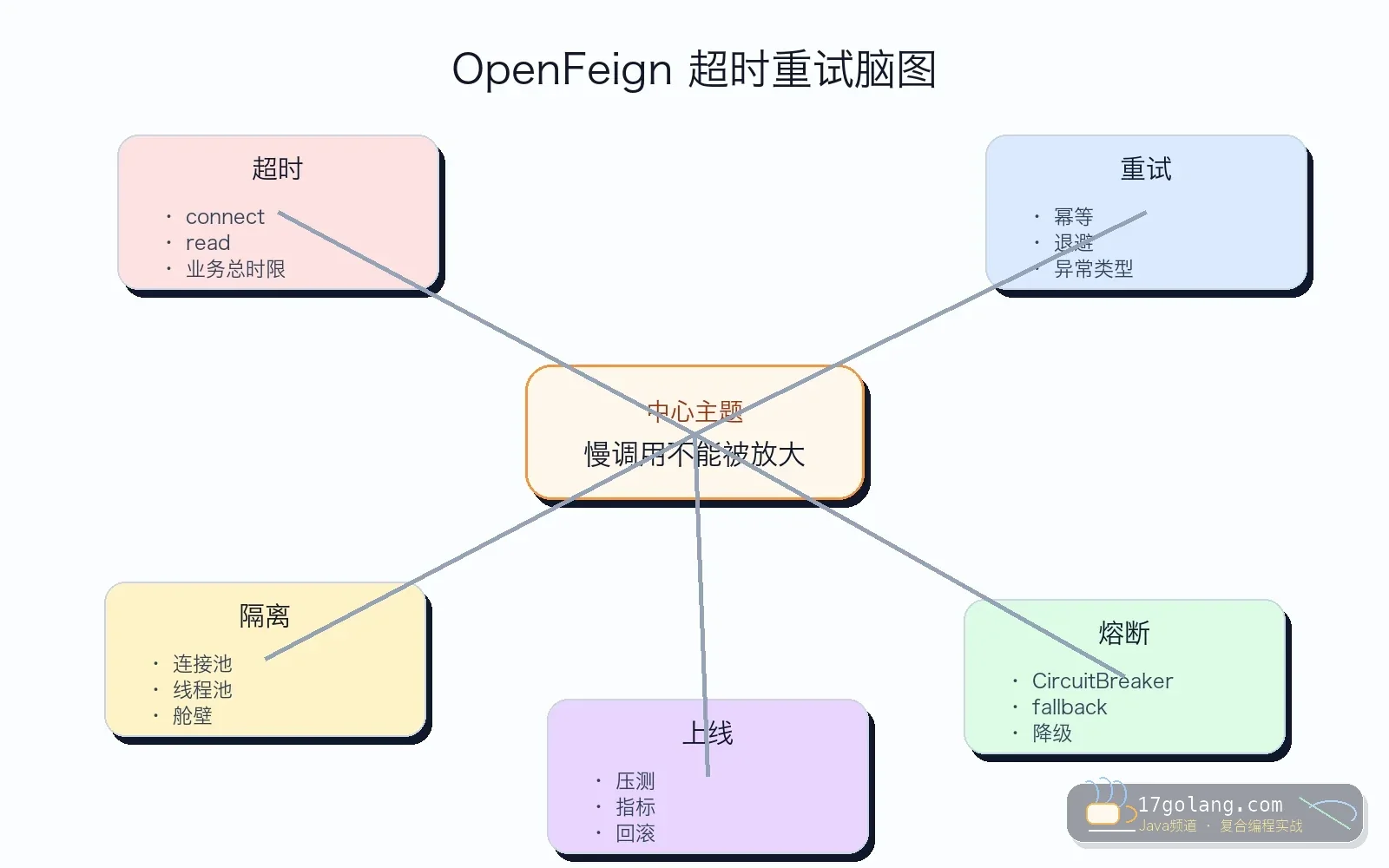
这篇写一个 Spring Cloud OpenFeign 线上常见事故:下游库存接口偶发 1 秒慢,订单服务 p99 却被拖到 5 秒,线程池开始排队。很多人第一反应是把 readTimeout 调大,但这通常是在帮慢下游占住更多资源。
本文适用于 Java 17/21、Spring Boot 3.x、Spring Cloud OpenFeign。资料只用于核对事实:OpenFeign 有 connect/read 两类 timeout;Spring Cloud OpenFeign 的重试行为和 Feign 默认行为不同,并且可接入 Spring Cloud CircuitBreaker。正文按生产复盘写,不搬官方文档。
业务场景:一个慢下游拖垮订单服务
订单提交会调用库存、优惠券和支付预校验。库存接口平时 80ms,活动期间偶发 900ms。订单服务的 Feign readTimeout 配成 10 秒,重试策略也没有按接口区分。结果一个慢调用被等待、被重试、被排队,最终拖住业务线程。
这类问题表面是“下游慢”,本质是调用方没有设置好资源边界。调用方必须决定:我最多等多久?哪些错误能重试?重试几次?失败时怎么降级?
问题复现:慢接口被重试放大
最小复现很简单:让库存接口每 10 个请求慢 1 次,再给 Feign 配较长 readTimeout 和无差别重试。压测时你会看到库存服务请求数变多,订单服务线程等待变多,用户响应变慢。
踩坑原因:超时和重试没有业务语义
不是所有接口都适合重试。查询类、幂等读请求可以考虑少量重试;下单、扣库存、扣款这类写请求,必须先证明幂等和去重机制可靠,否则重试会制造更大的事故。
超时也不是越大越稳。用户请求有总时限,网关有超时,线程池和连接池也有上限。Feign 的 readTimeout 设置得比上游网关还长,往往没有意义。
配置案例:短超时、少重试、可降级
下面这张图展示了常见错误:全局把 readTimeout 拉长,却没有熔断、没有隔离、没有指标。生产配置应该按下游和接口粒度拆分。

spring:
cloud:
openfeign:
circuitbreaker:
enabled: true
client:
config:
inventoryClient:
connectTimeout: 300
readTimeout: 800
loggerLevel: basic
如果要配置 Retryer,我建议只给明确幂等的接口启用,并设置退避、最大次数和异常白名单。默认全局重试很容易把下游慢故障放大成调用方雪崩。
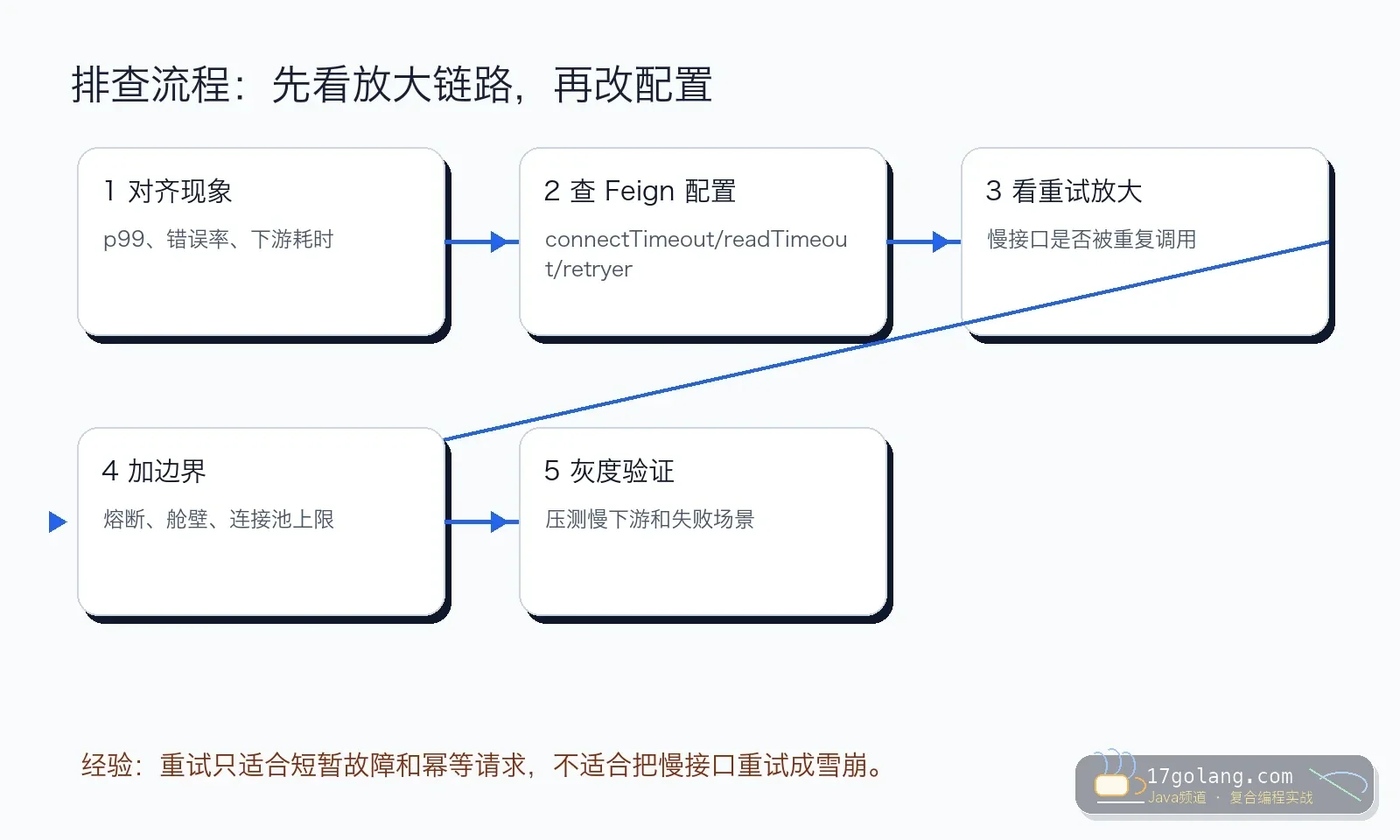
诊断步骤:我会按这五步查
第一步,对齐时间线。 把订单 p99、库存接口耗时、Feign 错误率、线程池队列放在同一张图。
第二步,看 Feign 配置来源。 多环境、多 client 配置容易被覆盖,确认最终生效的是哪个 connectTimeout、readTimeout、Retryer。
第三步,查重试次数。 通过下游 access log 或 trace 看一次用户请求到底打了几次下游。
第四步,看资源隔离。 HTTP 连接池、业务线程池、Bulkhead、CircuitBreaker 都是边界,不能让一个下游占满全部资源。
第五步,做坏天气压测。 模拟下游慢 1 秒、失败 5%、连接拒绝、半开恢复,验证是否会放大故障。
上线检查
- 每个 Feign Client 都有明确 connectTimeout/readTimeout。
- 重试只用于幂等接口,并限制次数、退避和异常类型。
- 核心下游配置 CircuitBreaker、fallback 和告警。
- 指标覆盖调用耗时、错误率、重试次数、熔断状态和连接池。
- 灰度时压测慢下游,确认调用方不会排队雪崩。
我的经验总结
OpenFeign 很方便,但方便不等于安全。微服务调用最怕“默认能跑就上线”,真正上生产必须有等待边界、重试边界和降级边界。
我的建议是:先按接口定义超时,再按业务幂等性决定重试,最后用熔断和指标兜底。慢下游不可怕,可怕的是调用方把慢故障重试成全链路事故。




