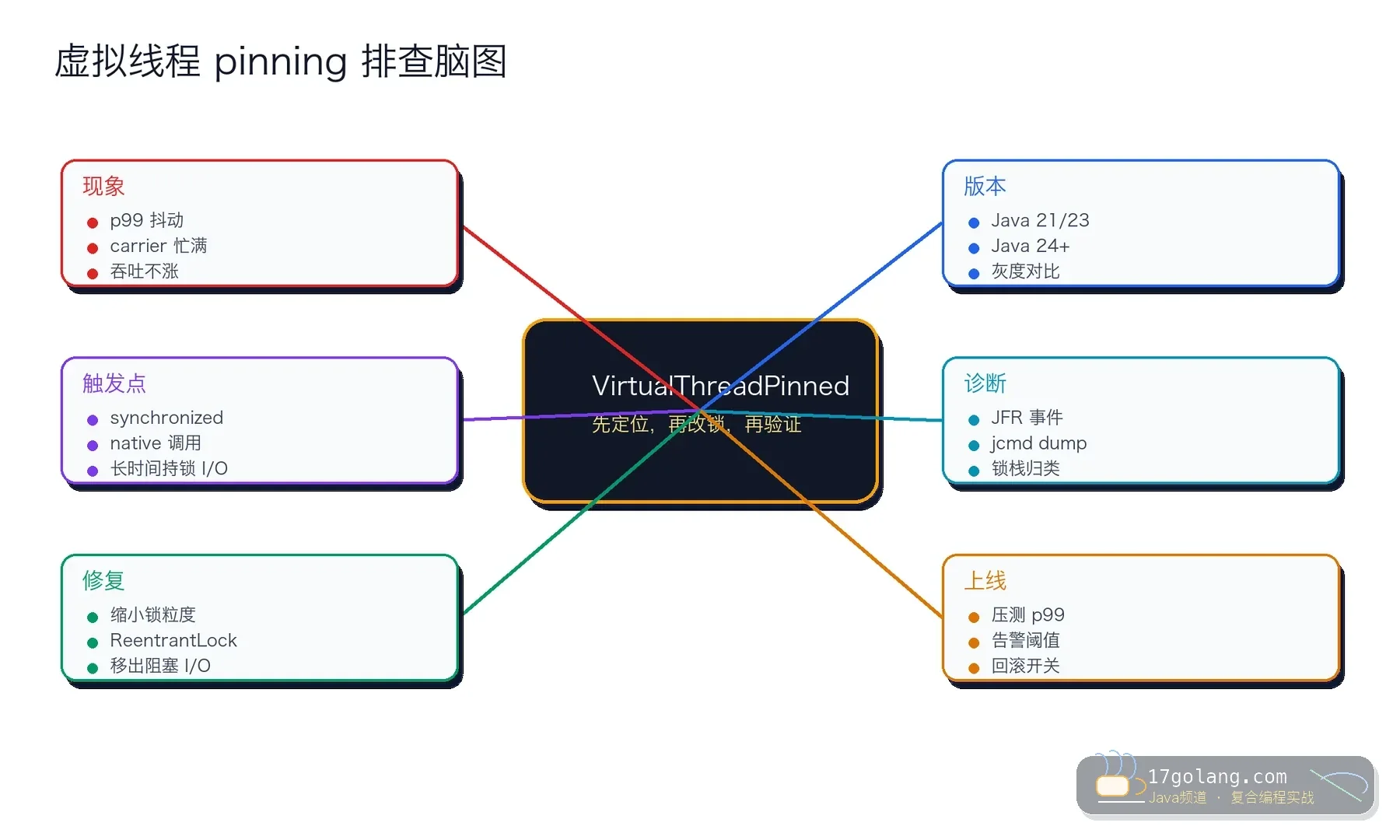
这篇写一个最近 Java 团队升级 JDK 时经常会问的问题:虚拟线程上线后,JDK 21/23 里 synchronized 导致的 pinning,到 JDK 24/25 还要不要管?我的答案是:版本改善是真的,但生产排查不能靠一句“已经修了”。
适用范围:Java 21 到 25、Spring Boot 3.x 虚拟线程、JFR、ThreadPoolTaskExecutor 迁移、同步代码改造。OpenJDK/JEP/JFR 资料只用来核对事实,正文按一次后端服务升级复盘来写。
业务场景:订单详情接口开了虚拟线程,p99 还是抖
我们有个订单详情接口,Spring Boot 3.x 开了虚拟线程后,平均响应时间好看了不少,但高峰 p99 仍然偶发抖动。线程 dump 看不到传统线程池排队,数据库连接池也没满,第一眼很容易误判成“下游偶发慢”。
后来抓 JFR 才发现,少量请求会进入一个带 synchronized 的收据组装方法,方法里还夹着远程价格查询。Java 21/23 上这类写法可能把虚拟线程 pin 在 carrier 上,carrier 一忙,虚拟线程再便宜也救不了尾延迟。
先说版本差异:JDK 24+ 不是免死金牌
Java 24 开始,常见 synchronized 场景导致虚拟线程 pinning 的问题有明显改善,这对保留老代码迁移虚拟线程非常有价值。但我不会因此把所有锁审查删掉,因为 native 调用、长时间持锁、锁里做阻塞 I/O 这些生产坏味道仍然会伤害吞吐和可维护性。
我的升级建议是:Java 21/23 环境先把锁里阻塞 I/O 当成高风险处理;Java 24/25 环境也要用 JFR 证明 pinned 事件和 p99 已经受控。版本帮你减少坑,不会替你完成架构 review。
问题复现:一个看起来无害的 synchronized 方法
最容易出事故的代码不是大锁套大锁,而是“为了保护一点缓存状态”,顺手把数据库查询、HTTP 调用、JSON 组装都包进了同步方法。低并发没事,一到高峰就变成 carrier 被拖住。

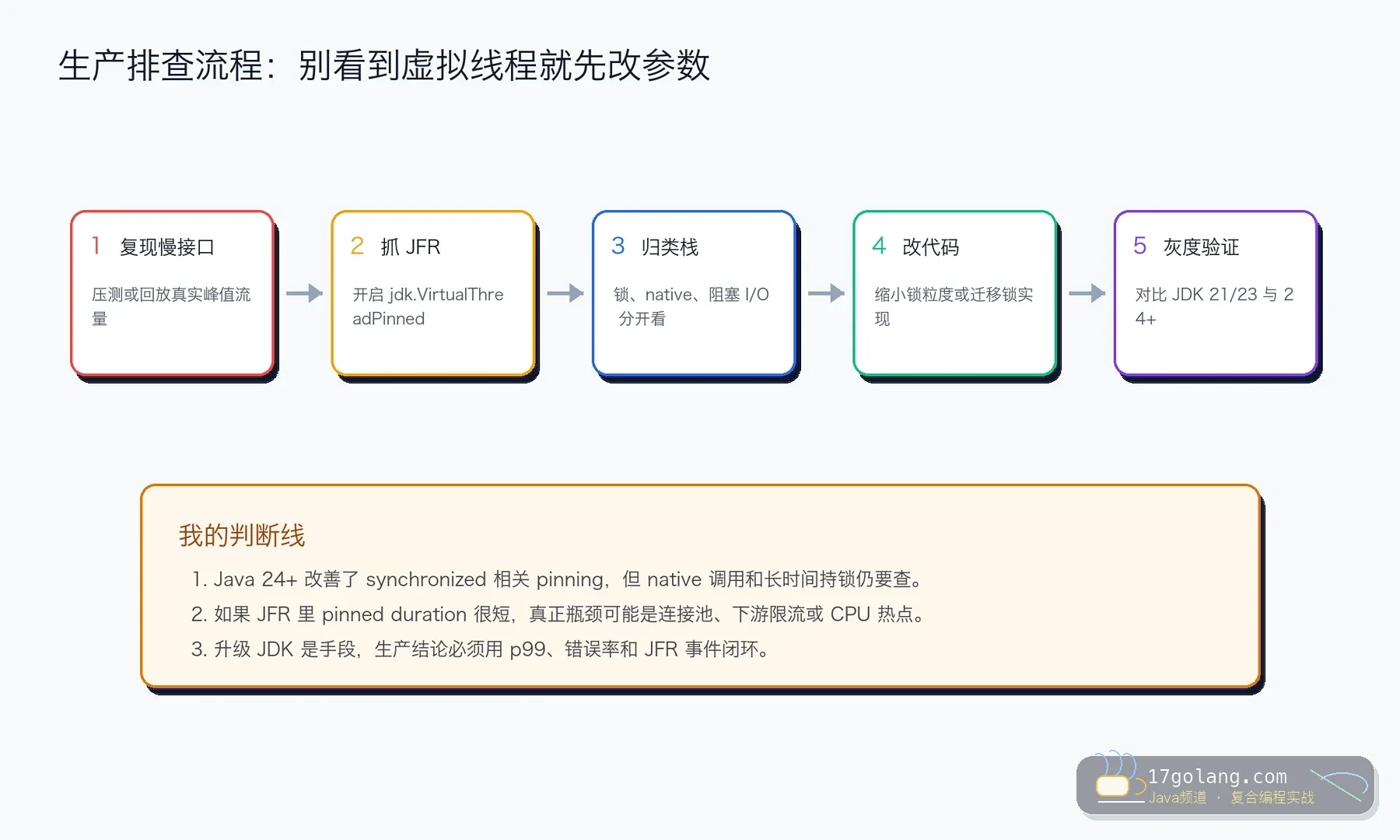
诊断步骤:别靠猜,用 JFR 把栈抓出来
我一般先在灰度实例开一段短 JFR,重点看 jdk.VirtualThreadPinned、线程状态、HTTP/JDBC 等待时间和接口 p99。抓到事件以后不要只看数量,要按调用栈归类:是业务锁、框架锁、native 调用,还是某个 SDK 在锁里做了阻塞。
如果 pinned duration 很短,但 p99 仍然高,就别继续盯着 pinning 了,去看连接池等待、下游限流、GC 暂停和 CPU 热点。排障最怕抓到一个“看起来像原因”的信号就停。
上线检查:我会盯这 7 个点
- 确认运行时版本:Java 21/23 与 Java 24/25 的压测结果分开记录。
- JFR 是否开启过
VirtualThreadPinned观察,是否保存样本。 - 锁内是否还存在 JDBC、HTTP、文件 I/O 或慢序列化。
- 连接池、Bulkhead、Semaphore 是否限制的是下游资源,而不是虚拟线程数量。
- p95/p99、错误率、超时率是否和老版本同流量对比。
- 是否有快速关闭虚拟线程或回退 JDK 的配置路径。
- ThreadLocal 大对象和 MDC 清理是否通过压测和日志验证。
我的经验
虚拟线程真正改变的是“等待线程”的成本,不是让阻塞资源无限变多。JDK 24/25 让 synchronized 的迁移体验更好,但生产系统里最贵的往往不是线程,而是数据库连接、下游 QPS、锁粒度和排障时间。
所以我会把这类升级拆成三步:先用 JFR 找证据,再把锁内阻塞点移出去,最后用灰度数据决定是否扩大流量。这样文章里的结论不是版本宣传,而是能在凌晨事故里救人的操作手册。




