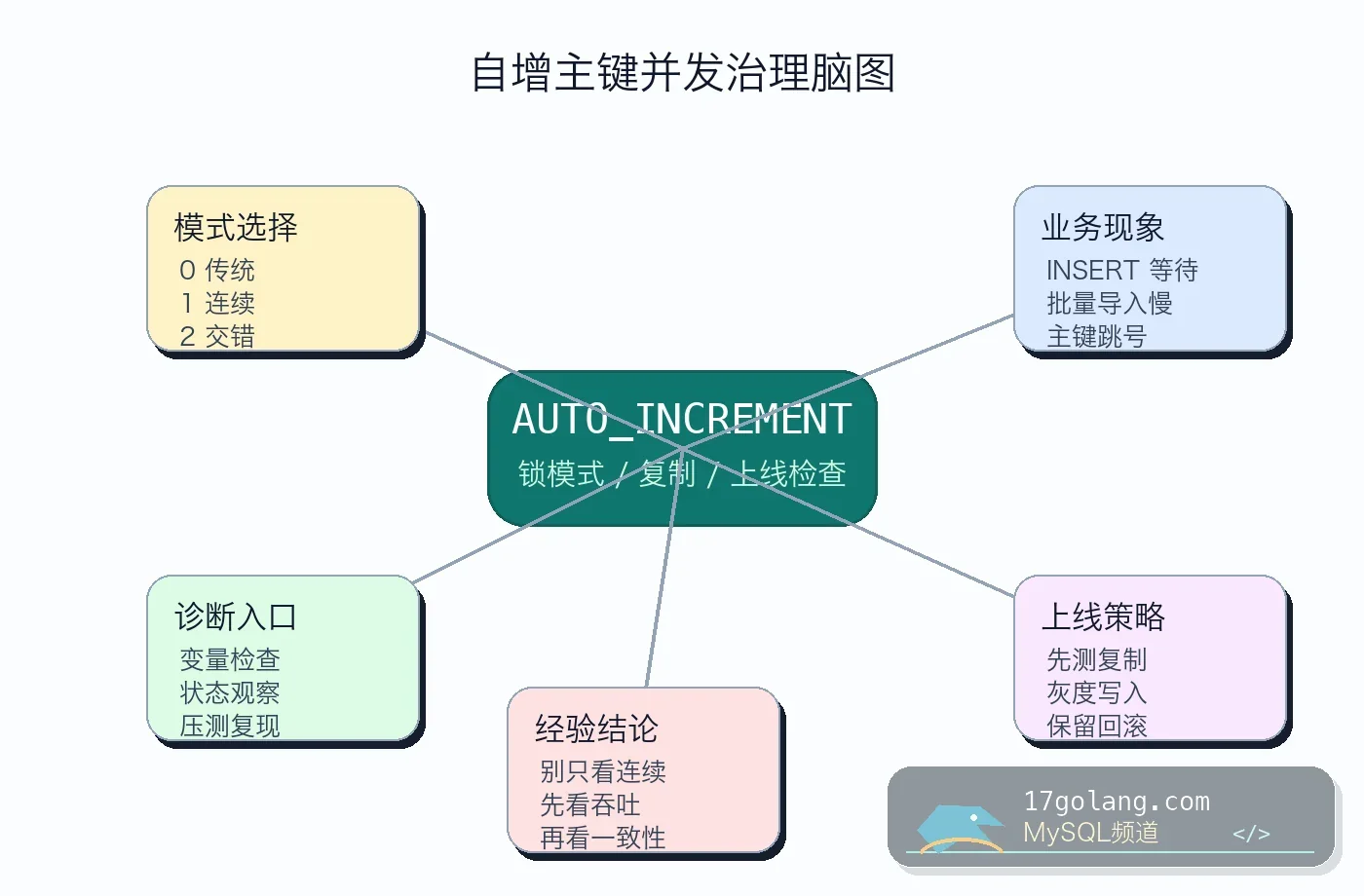
有一次订单库凌晨扩容,业务侧把写入线程数从 80 提到 240,CPU 没先满,磁盘也没先满,最早冒出来的是一串看起来很委屈的 INSERT 慢日志。表结构很普通:id BIGINT AUTO_INCREMENT PRIMARY KEY,大家第一反应是“自增主键不是最快的吗”。这句话只说对了一半:自增主键确实让聚簇索引写入更顺,但 AUTO_INCREMENT 值怎么分配、批量插入怎么拿号、复制格式能不能接受交错编号,都会影响高并发写入。
这篇只讲 MySQL 8.4 / InnoDB 场景。它不是劝你盲目把 innodb_autoinc_lock_mode 改成 2,而是给一套能在生产落地的判断路径:先看业务写入形态,再看复制格式,最后压测和灰度。
一、事故复现:单行写不慢,批量写一来全库抖
假设有一张交易流水表,平时在线请求都是单行写,夜间又有补偿任务批量导入历史订单:
CREATE TABLE trade_bill ( id BIGINT UNSIGNED NOT NULL AUTO_INCREMENT, tenant_id BIGINT NOT NULL, order_no VARCHAR(64) NOT NULL, amount DECIMAL(12,2) NOT NULL, created_at DATETIME NOT NULL, PRIMARY KEY (id), UNIQUE KEY uk_tenant_order (tenant_id, order_no), KEY idx_created_at (created_at) ) ENGINE=InnoDB; -- 在线请求 INSERT INTO trade_bill(tenant_id, order_no, amount, created_at) VALUES (1001, 'O202606050001', 89.90, NOW()); -- 夜间补偿 INSERT INTO trade_bill(tenant_id, order_no, amount, created_at) SELECT tenant_id, order_no, amount, created_at FROM trade_bill_stage WHERE batch_id = 20260605;
白天单行 INSERT 很稳,补偿任务一上来就开始抖。这里不要急着怪索引,也不要只盯 redo 或 buffer pool。先把自增锁模式、语句类型和复制格式摆在一起看。
二、先把三个锁模式说成人话
InnoDB 的 innodb_autoinc_lock_mode 用来控制 AUTO_INCREMENT 值分配时的锁策略。不同版本和配置默认值可能不一样,线上必须以实际变量为准:
SHOW VARIABLES LIKE 'innodb_autoinc_lock_mode'; SHOW VARIABLES LIKE 'binlog_format';
我在排障时通常这样理解:
- 0 traditional:传统表级自增锁,兼容性强,但高并发写入吞吐最吃亏。
- 1 consecutive:尽量保证批量语句拿到连续自增值,很多老系统会见到这个模式。
- 2 interleaved:交错分配自增值,并发性能更好,但如果你还依赖 statement-based replication 或业务假设连续编号,就要非常谨慎。
三、踩坑根因:业务把 id 当业务序号,DBA 把模式当性能开关
我见过两类事故最常见。第一类是业务把自增 id 当“连续流水号”,后来改成更高并发的模式后发现编号有空洞或交错,就认为数据库错了。其实自增主键只适合作为技术主键,不应该承诺连续、无缺口、可审计含义。流水号要单独设计。
第二类是 DBA 看到 INSERT 等待,直接把模式改成 2,却没检查复制格式、导入 SQL、下游订阅和回放工具。结果线上写入确实快了,但某个依赖 statement 回放的链路开始不一致。这种锅很难背,因为它不是参数本身错,而是上线前没有把链路盘全。
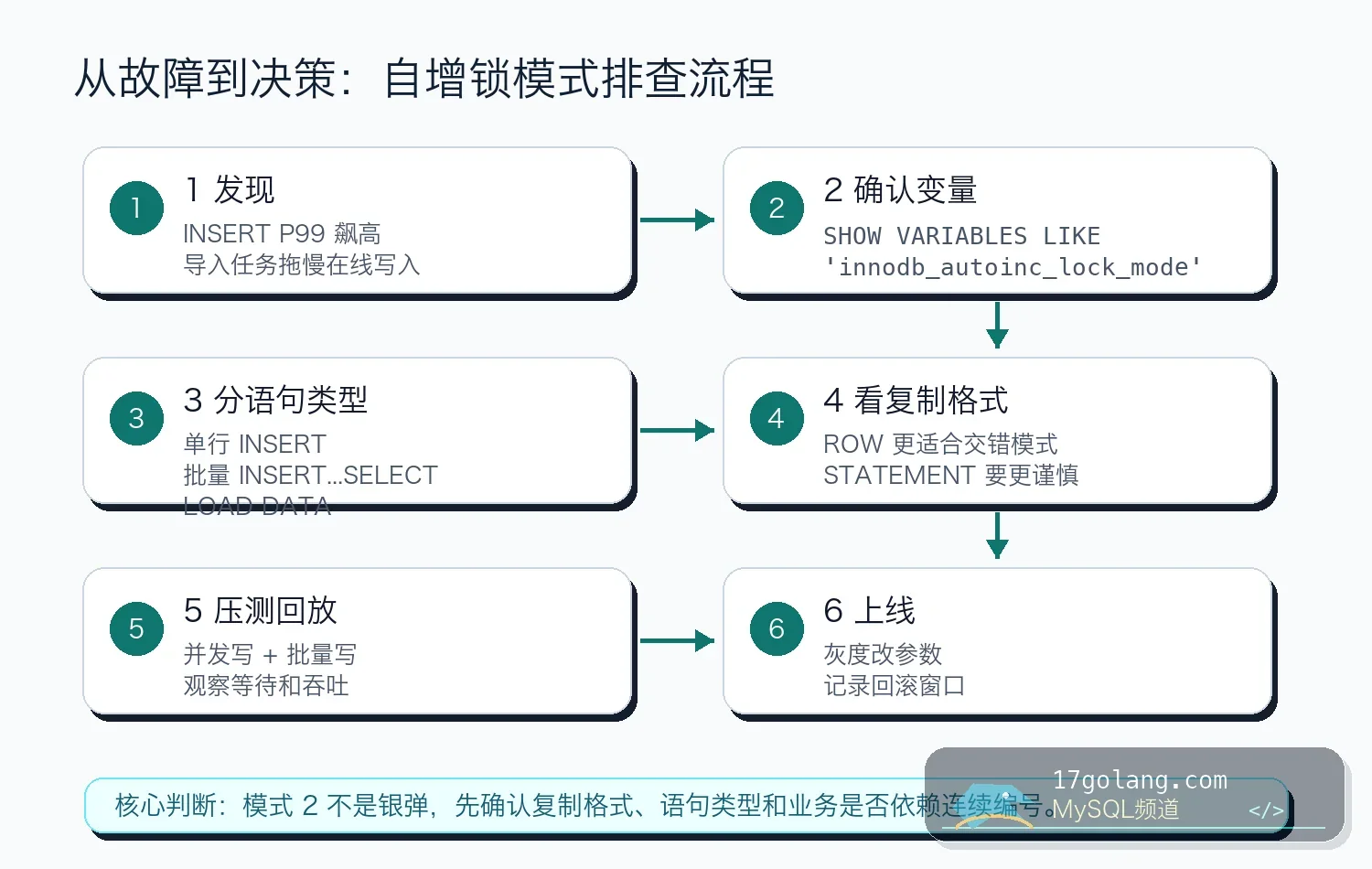
四、诊断步骤:先证明等待在哪里
我会按下面顺序查,尽量少猜:
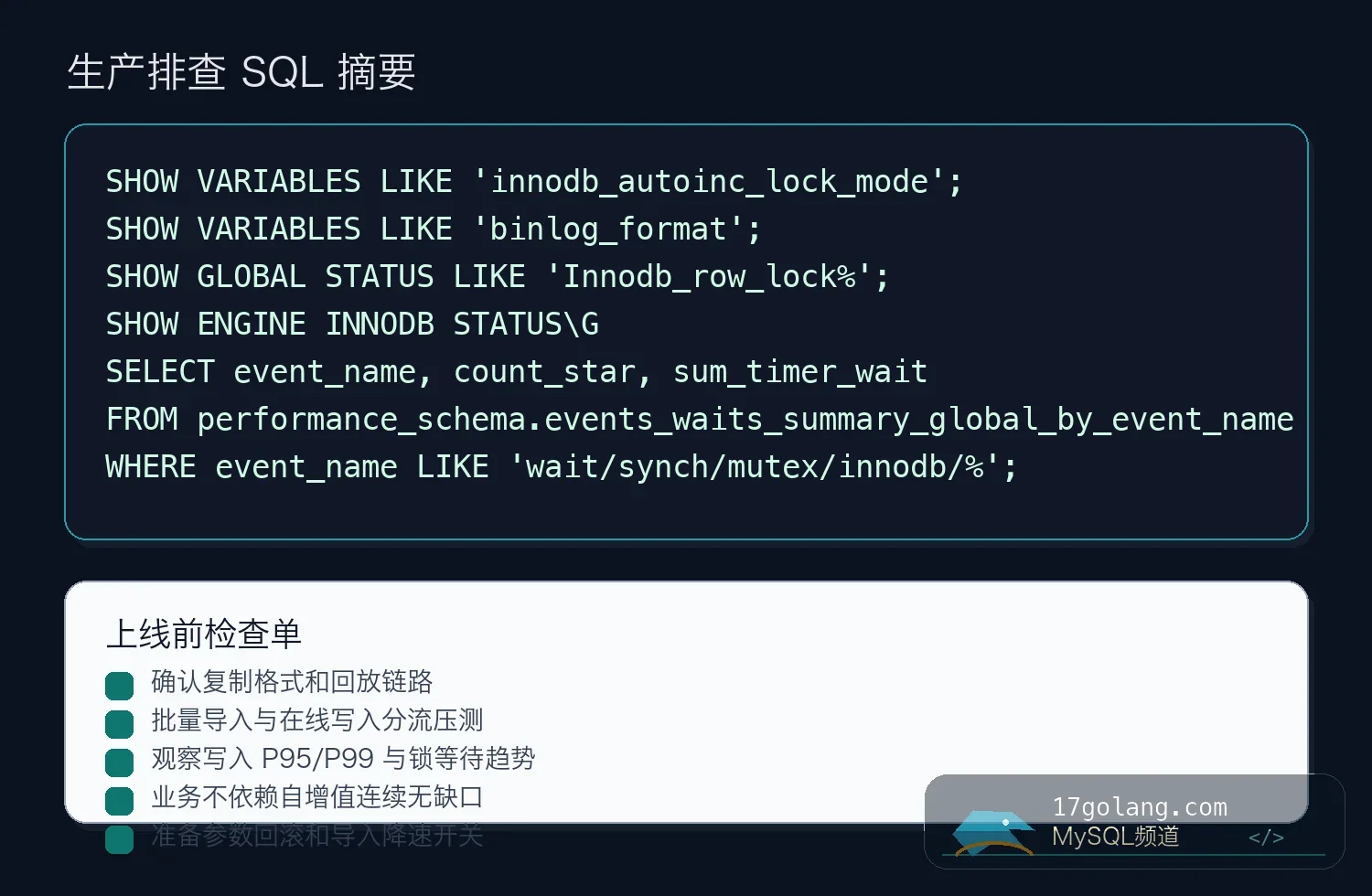
SHOW VARIABLES LIKE 'innodb_autoinc_lock_mode'; SHOW VARIABLES LIKE 'binlog_format'; SHOW GLOBAL STATUS LIKE 'Innodb_row_lock%'; SHOW ENGINE INNODB STATUS\G
如果你启用了 Performance Schema,可以继续看等待统计。不同小版本事件名会有差异,不要死背一条 SQL,要把它当入口:
SELECT event_name, count_star, sum_timer_wait FROM performance_schema.events_waits_summary_global_by_event_name WHERE event_name LIKE 'wait/synch/%/innodb/%' ORDER BY sum_timer_wait DESC LIMIT 20;
五、SQL 改写:批量导入不要和在线写入硬挤一条路
如果你的问题主要来自 INSERT ... SELECT 或 LOAD DATA,先不要急着改全局模式。更稳的做法是把批量任务限速、拆批,并避开在线高峰。
-- 每批只导入固定窗口,应用侧循环推进 last_id INSERT INTO trade_bill(tenant_id, order_no, amount, created_at) SELECT tenant_id, order_no, amount, created_at FROM trade_bill_stage WHERE batch_id = 20260605 AND stage_id > ? ORDER BY stage_id LIMIT 5000;
如果业务允许,也可以让导入任务写入独立表,再用低峰合并;或者直接让业务生成雪花 ID、号段 ID,把主键分配压力从 InnoDB 自增机制里移出去。但这属于架构选择,不要在事故凌晨临时改。
六、什么时候考虑调 innodb_autoinc_lock_mode
我的经验是满足下面条件,才值得认真评估模式 2:
- 复制格式是 ROW,或者你已经确认没有 statement-based 回放链路。
- 业务不依赖 AUTO_INCREMENT 连续、无缺口或按提交顺序严格递增。
- 主要瓶颈确实来自并发插入和批量插入交织,不是二级索引、唯一键冲突或磁盘刷脏。
- 有完整压测脚本,能同时跑在线单行写和批量导入。
- 准备了回滚方案,并知道参数变更对连接和实例重启策略的影响。
-- 示例:只在评估通过后执行,先在测试环境和灰度库验证 SET PERSIST innodb_autoinc_lock_mode = 2;
有些环境这个变量是否动态生效、是否需要重启,要以你的 MySQL 版本和实际输出为准。生产上我更倾向用变更单记录:当前值、目标值、复制格式、压测结果、回滚步骤。
七、上线检查单
- 检查主库、从库、延迟从库的
binlog_format和回放工具。 - 压测单行 INSERT、批量 INSERT、唯一键冲突三种场景。
- 观察写入 P95/P99、
Innodb_row_lock_time、错误率和复制延迟。 - 确认业务没有用自增 id 做连续流水号、分页游标以外的审计含义。
- 导入任务保留限速开关,出现复制延迟或锁等待时能降速。
八、我的结论
AUTO_INCREMENT 问题最容易被低估,因为表结构看起来太普通了。真正的风险不在“自增主键能不能用”,而在你是否知道当前锁模式适合哪类 SQL、复制链路能不能接受交错分配、业务有没有偷偷依赖连续编号。MySQL 8.4 下做高并发写入治理,最稳的路径仍然是:先观测,后压测,再灰度;参数是最后一公里,不是第一反应。




