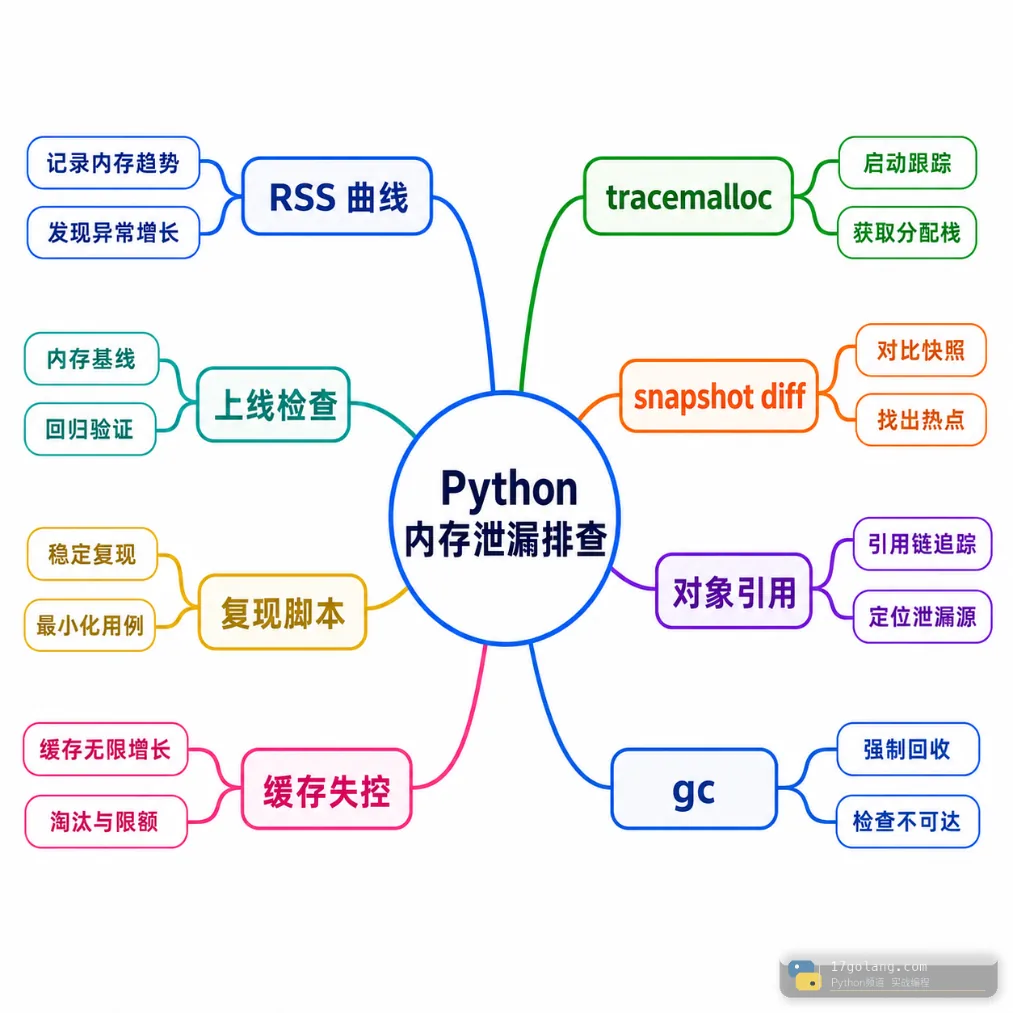
Python 服务内存持续上涨时,很多团队第一反应是“GC 没回收”或者“容器限制太小”。实际线上更常见的是:缓存没有上限、全局列表留住对象、闭包或回调链保留引用,导致 RSS 一路爬升。只看进程内存曲线,通常看不到是哪一行代码在增长。
这篇文章按一次生产排障来写:如何判断内存增长是不是 Python 对象泄漏,如何用 tracemalloc 做 snapshot diff,如何结合 gc 和引用链定位缓存/全局变量问题,最后怎样做上线回归。示例适用于 Python 3.12/3.13。
业务场景:发布后 RSS 每小时涨 300 MB
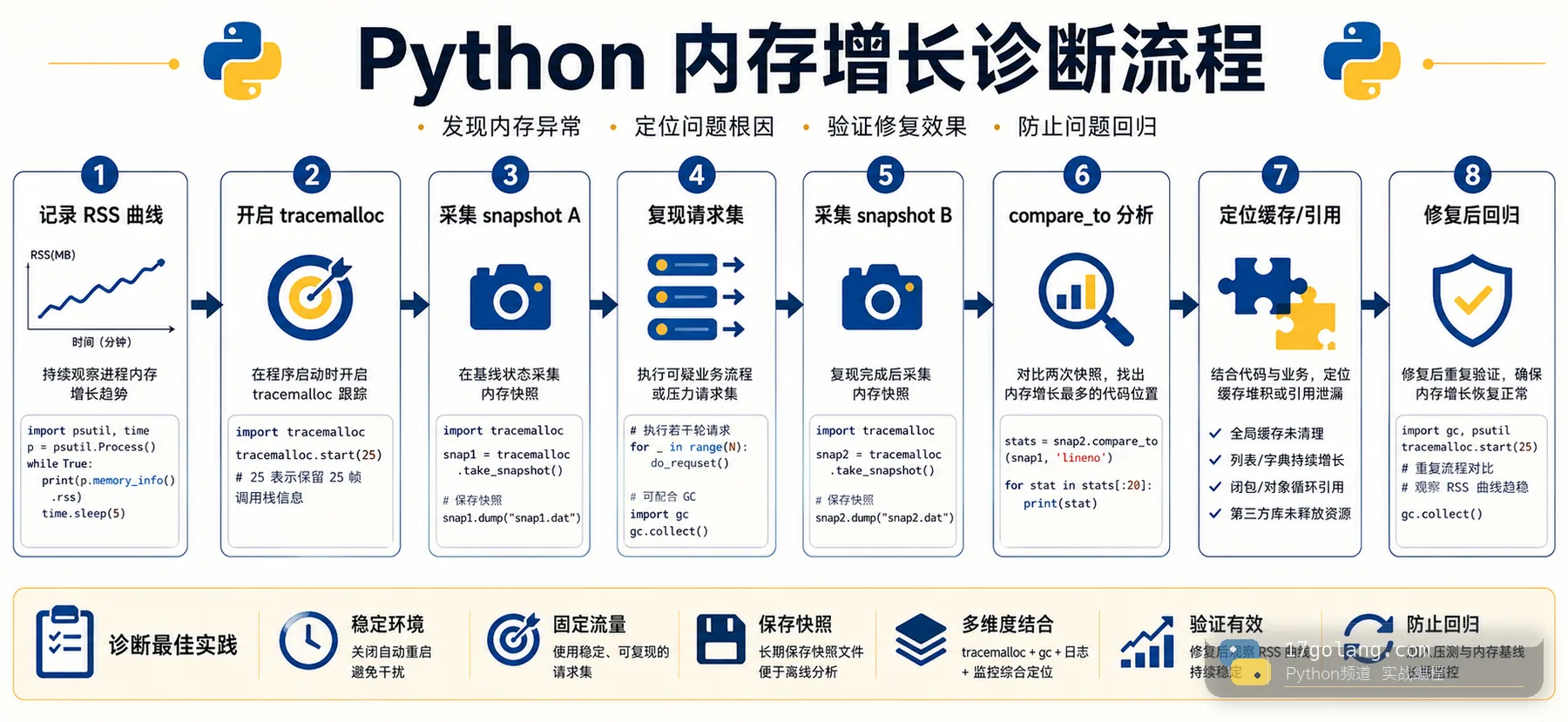
假设一个 Python API 服务发布后,容器 RSS 从 600 MB 慢慢涨到 2.5 GB。重启能恢复,流量一上来又复现。日志没有异常,CPU 正常,接口延迟在内存接近上限时开始抖动。
这时不要马上改容器内存,也不要只执行 gc.collect()。第一步是确认增长是否可复现,并把排查窗口缩小到“某类请求之后,哪些 Python 分配变多”。
# 典型风险:无上限缓存持续保留对象
user_profile_cache: dict[str, dict] = {}
def get_profile(user_id: str) -> dict:
if user_id not in user_profile_cache:
user_profile_cache[user_id] = load_profile(user_id)
return user_profile_cache[user_id]
这段代码本地压测不一定暴露问题。线上用户 ID 基数大,缓存没有过期策略,字典就会变成进程内常驻对象仓库。
第一步:尽早打开 tracemalloc
tracemalloc 追踪的是 Python 分配的内存块。它越早启动,看到的分配链路越完整。生产排障时,我通常先在灰度实例或复现环境开启,不直接全量打开。
# app_bootstrap.py
import os
import tracemalloc
if os.getenv("PYTHON_TRACE_MEMORY") == "1":
tracemalloc.start(25) # 保留最多 25 层分配调用栈
如果能控制启动参数,也可以用 PYTHONTRACEMALLOC=25 或 -X tracemalloc=25。保留更多 frame 会增加开销,但排查复杂调用链时很有价值。
第二步:用两次快照做 diff
单次快照只能告诉你“现在谁占得多”,不一定说明泄漏。更可靠的是在复现前后各采一张快照,然后比较增量。
# memory_probe.py
import pathlib
import tracemalloc
SNAPSHOT_DIR = pathlib.Path("/tmp/python-memory")
SNAPSHOT_DIR.mkdir(exist_ok=True)
def dump_snapshot(name: str) -> pathlib.Path:
snapshot = tracemalloc.take_snapshot()
path = SNAPSHOT_DIR / f"{name}.snap"
snapshot.dump(path)
return path
def compare_snapshot(before: pathlib.Path, after: pathlib.Path) -> None:
snap1 = tracemalloc.Snapshot.load(before)
snap2 = tracemalloc.Snapshot.load(after)
for stat in snap2.compare_to(snap1, "lineno")[:20]:
print(stat)
建议把快照文件写到临时目录,避免在内存紧张时还把大对象保留在进程变量里。分析时优先看 size_diff 和 count_diff 同时增长的行。
第三步:过滤噪音,盯住业务代码
快照 diff 里经常会出现 import、模板、日志、traceback 缓存等噪音。排查时要过滤掉虚拟环境、标准库和已知框架目录,把注意力放到业务模块。
def business_stats(snapshot):
return snapshot.filter_traces((
tracemalloc.Filter(False, ""),
tracemalloc.Filter(False, "*/site-packages/*"),
tracemalloc.Filter(False, "*/lib/python*/logging/*"),
)).statistics("traceback")
如果某个业务文件的某一行持续增长,再切到 statistics("traceback"),看它从哪个入口一路分配过来。只看文件行号容易误判公共工具函数。
第四步:结合 gc 看引用是否还活着
tracemalloc 能告诉你“哪里分配了更多 Python 内存”,但不直接告诉你“谁还引用着对象”。定位到可疑类型后,可以用 gc 做辅助检查。
import gc
def count_live_dicts() -> int:
gc.collect()
return sum(1 for obj in gc.get_objects() if isinstance(obj, dict))
def show_referrers(obj) -> None:
for ref in gc.get_referrers(obj)[:10]:
print(type(ref), repr(ref)[:200])
gc.get_referrers() 只能在诊断环境谨慎使用,输出里会包含解释器内部对象、当前栈帧和调试器引用。不要把这类函数直接挂到公网接口。
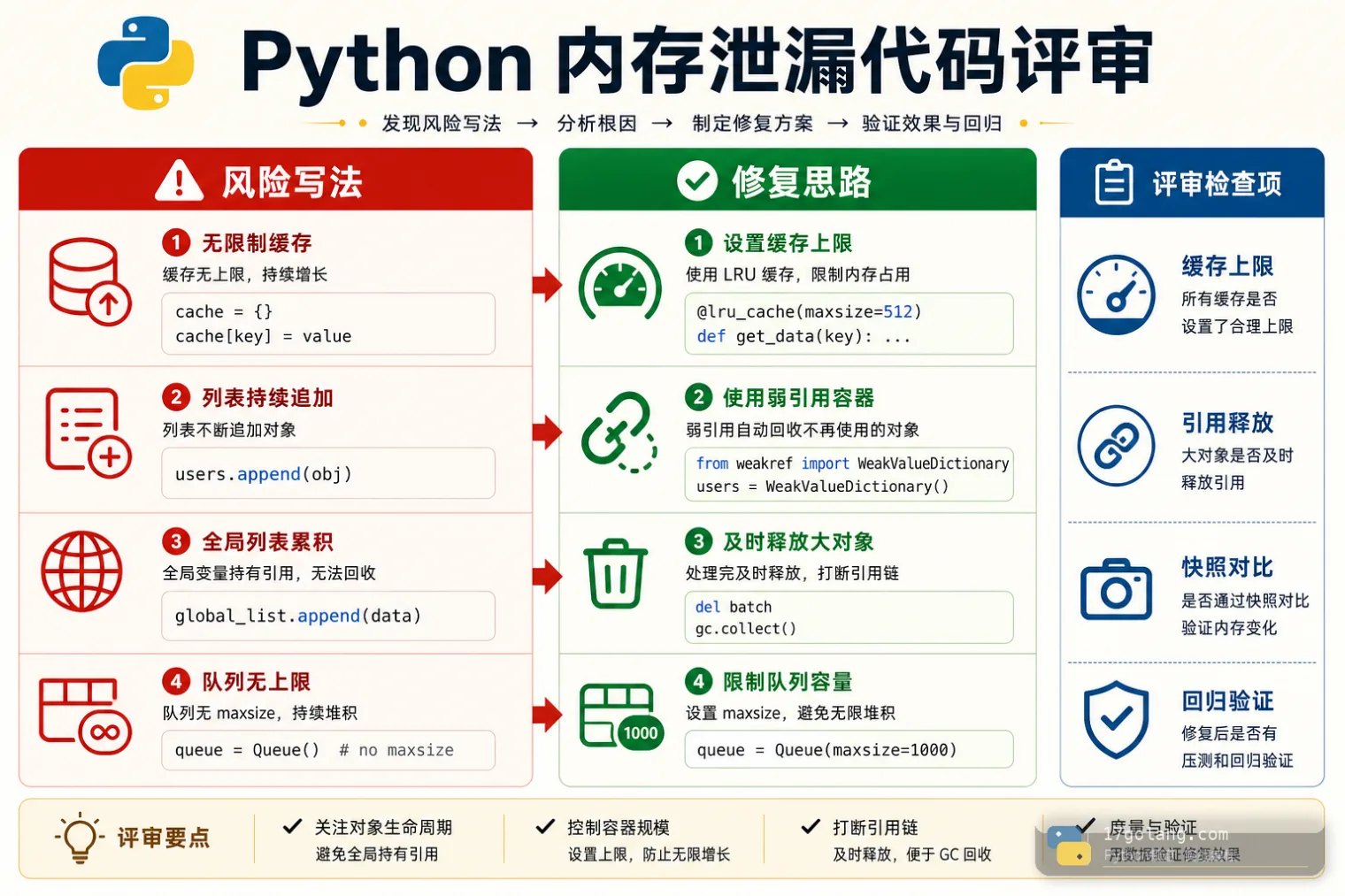
修复:给缓存边界和对象生命周期
如果泄漏来自无上限缓存,优先修缓存策略,而不是定时重启。常见修复包括:functools.lru_cache(maxsize=...)、TTL 缓存、按租户隔离的容量上限、批处理后显式丢弃临时列表。
from functools import lru_cache
@lru_cache(maxsize=512)
def load_profile_cached(user_id: str) -> tuple[str, str]:
profile = load_profile(user_id)
return profile["name"], profile["level"]
def process_batch(rows: list[dict]) -> None:
try:
for row in rows:
handle(row)
finally:
rows.clear()
不要为了省查询把完整 ORM 对象、请求对象、响应对象直接塞进全局缓存。它们通常带着连接、上下文、回调和大量间接引用。
上线检查清单
- 确认 RSS 增长可以在灰度或压测环境稳定复现。
- 在复现前后采集两次
tracemallocsnapshot,并保留分析文件。 - 使用
compare_to(..., "lineno")看增量,再用statistics("traceback")查调用链。 - 过滤标准库、site-packages 和已知噪音,优先看业务文件。
- 检查全局缓存、类变量、模块级列表、闭包、回调注册表和批处理临时对象。
- 修复后用相同请求集压测,确认 RSS 曲线稳定,快照 diff 不再持续增长。
- 不要依赖定时重启掩盖泄漏;重启只能作为临时止损。
总结
Python 内存泄漏排查要避免两个误区:只看 RSS 就下结论,以及只调用 gc.collect() 就认为问题解决。真正有效的路径是:复现增长、采集快照、对比增量、定位引用、修复生命周期。
我的经验是,tracemalloc 负责把问题缩小到具体文件和调用链,gc 负责验证对象是否还被引用。把这两件事做扎实,内存泄漏排查就会从猜测变成可验证的工程流程。




