Go Prometheus 指标设计:RED、USE 与自定义业务指标落地
来源:Golang学习网专题原创
时间:2026-06-12 10:38:50 526浏览 收藏
很多 Go 服务只暴露 CPU 和内存,真正接口慢、错误率高、队列堆积时没有指标可看。可观测性要先从指标开始,把请求、资源和业务状态都变成可告警的数据。
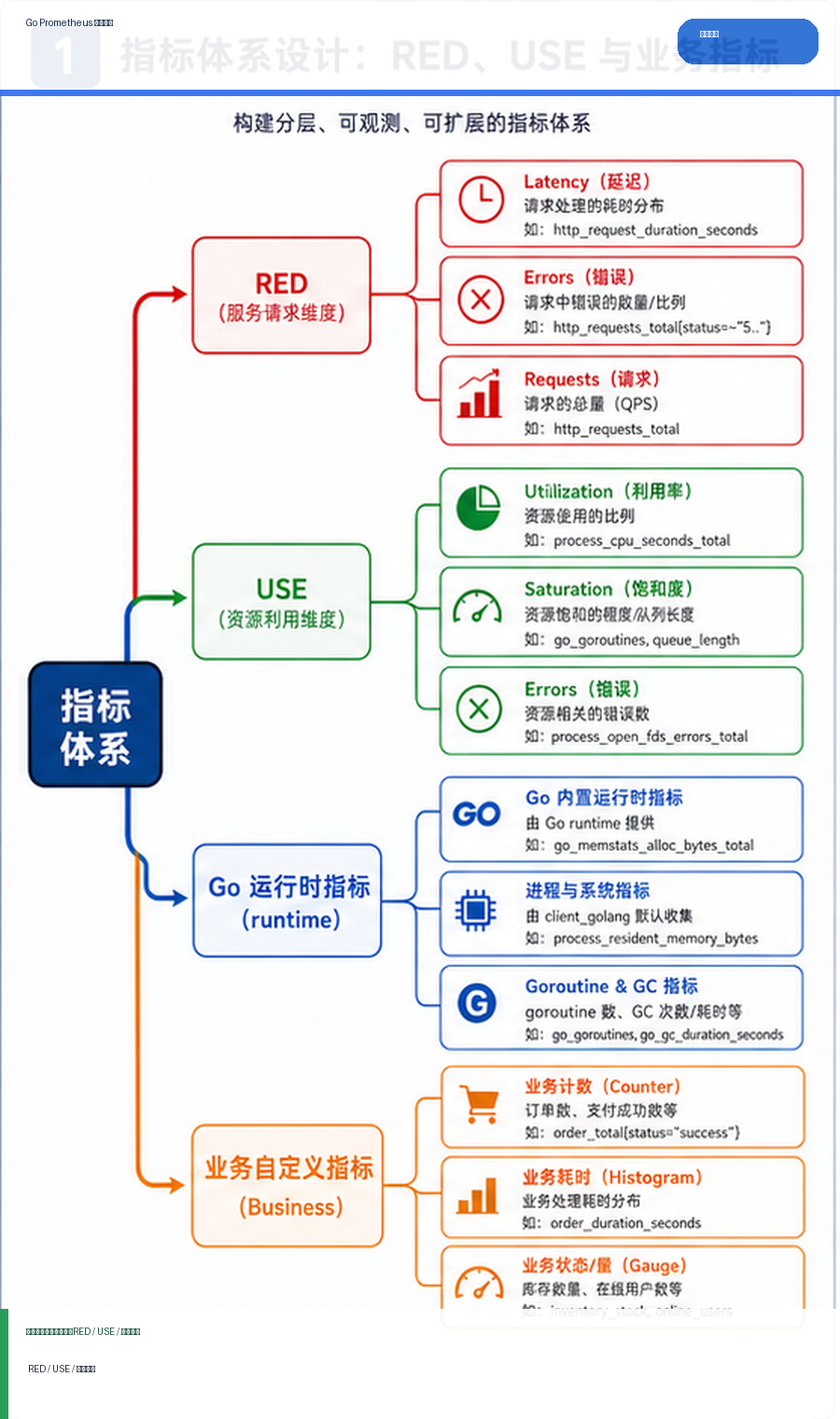
解决方案思路
接口层用 RED:请求量、错误率、延迟分布;资源层用 USE:使用率、饱和度、错误;业务层只保留能指导决策的 Counter、Gauge、Histogram。标签必须控制基数,route 使用模板名,不直接放 user_id、order_id。

核心代码示例
requestDuration := prometheus.NewHistogramVec(
prometheus.HistogramOpts{Name: "http_request_duration_seconds"},
[]string{"route", "method", "code"},
)
http.Handle("/metrics", promhttp.Handler())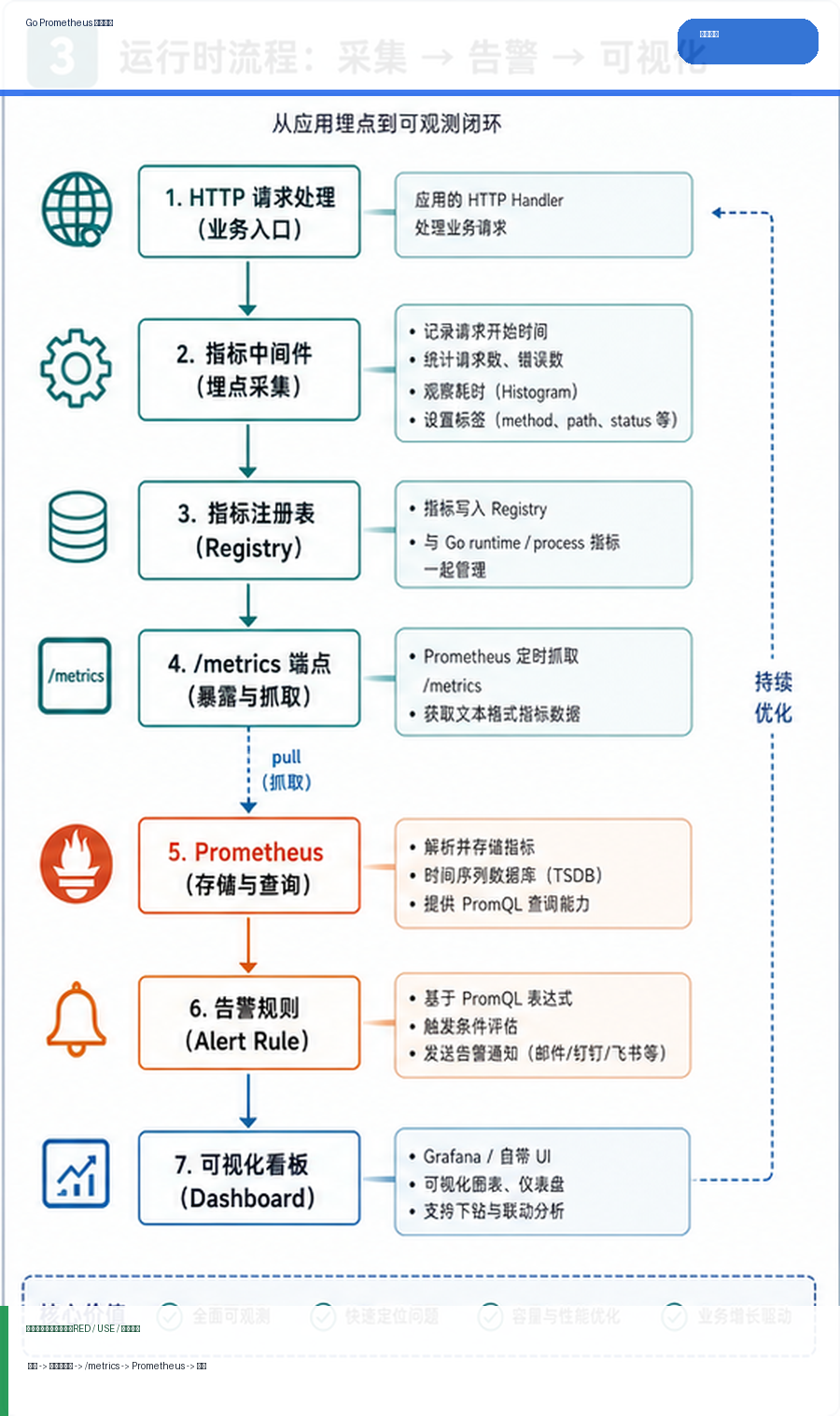
运行逻辑
请求经过指标中间件时记录 route、status code 和耗时,Prometheus 定时抓取 /metrics,告警规则再根据错误率、P99 和饱和度触发通知。
重点观察指标
- http_request_duration_seconds P95/P99
- http_requests_total 错误率
- goroutines、heap、GC pause、队列长度和业务积压量
常见误区
- 标签基数过高压垮 Prometheus
- 只看平均值,不看分位数和错误率
- 业务指标没有 owner,告警触发后无人处理
参考方案
落地检查
- 字段、指标和 Span 名称要稳定,便于长期聚合。
- 上线前先在灰度环境验证采集成本和数据量。
- 告警必须能指向 owner、排查入口和回滚方案。
声明:本文转载于:Golang学习网专题原创 如有侵犯,请联系study_golang@163.com删除
相关阅读
更多>
-
860 收藏
-
843 收藏
-
826 收藏
-
809 收藏
-
792 收藏
最新阅读
更多>
-
367 收藏
-
Golang · Go教程 | 1天前 | channel · select · Context · Go教程 · 性能排查 · select channel context default time.Ticker Go教程 CPU飙高 for select459 收藏
-
Golang · Go教程 | 1天前 | map · 基准测试 · 性能优化 · Go教程 · 内存分配 · 内存分配 Go性能优化 benchmark Go教程 map预分配 make map benchmem395 收藏
-
Golang · Go教程 | 1天前 | defer · 单元测试 · testing · Go教程 · t.Cleanup · defer 单元测试 Testing 子测试 Go教程 T.Cleanup 测试资源清理418 收藏
-
Golang · Go教程 | 1天前 | defer · Go教程 · 文件句柄 · 资源释放 · 数据库rows · defer for循环 文件句柄 资源释放 close Go教程 rows.Close421 收藏
-
Golang · Go教程 | 1天前 | HTTP · 文件上传 · Go教程 · 资源预算 · multipart · 文件上传 临时文件 ParseMultipartForm multipart Go教程 MaxBytesReader 资源预算237 收藏
-
Golang · Go教程 | 2天前 | 中间件 · HTTP · recover · Go教程 · 日志排障 · recover panic 结构化日志 HTTP中间件 request_id Go教程 接口排障111 收藏
-
399 收藏
-
386 收藏
-
234 收藏
-
476 收藏
-
176 收藏
课程推荐
更多>
-

- 前端进阶之JavaScript设计模式
- 设计模式是开发人员在软件开发过程中面临一般问题时的解决方案,代表了最佳的实践。本课程的主打内容包括JS常见设计模式以及具体应用场景,打造一站式知识长龙服务,适合有JS基础的同学学习。
- 立即学习 543次学习
-

- GO语言核心编程课程
- 本课程采用真实案例,全面具体可落地,从理论到实践,一步一步将GO核心编程技术、编程思想、底层实现融会贯通,使学习者贴近时代脉搏,做IT互联网时代的弄潮儿。
- 立即学习 516次学习
-

- 简单聊聊mysql8与网络通信
- 如有问题加微信:Le-studyg;在课程中,我们将首先介绍MySQL8的新特性,包括性能优化、安全增强、新数据类型等,帮助学生快速熟悉MySQL8的最新功能。接着,我们将深入解析MySQL的网络通信机制,包括协议、连接管理、数据传输等,让
- 立即学习 500次学习
-

- JavaScript正则表达式基础与实战
- 在任何一门编程语言中,正则表达式,都是一项重要的知识,它提供了高效的字符串匹配与捕获机制,可以极大的简化程序设计。
- 立即学习 487次学习
-

- 从零制作响应式网站—Grid布局
- 本系列教程将展示从零制作一个假想的网络科技公司官网,分为导航,轮播,关于我们,成功案例,服务流程,团队介绍,数据部分,公司动态,底部信息等内容区块。网站整体采用CSSGrid布局,支持响应式,有流畅过渡和展现动画。
- 立即学习 485次学习