Go worker pool 实战:用 channel 控制并发和收集结果
来源:17golang原创
时间:2026-06-13 01:18:08 459浏览 收藏
Go 写并发很方便,go func() 一行就能启动 goroutine。但方便不代表可以无限开。如果一次有几千个任务,每个任务都启动一个 goroutine,很容易把数据库连接、接口限流、CPU 调度和内存一起压住。
worker pool 的思路很朴素:任务可以很多,但同时运行的 goroutine 数量要固定。任务排队进入 jobs,几个 worker 轮流消费,处理完的结果写回 results,最后统一收尾。
摘要
本文会从“每个任务一个 goroutine”的风险讲起,使用 jobs channel、results channel 和 sync.WaitGroup 实现一个固定并发数的 worker pool。读完后,你可以把这套模式用于批量请求、图片处理、日志清洗、消息消费等场景。
适合人群
- 已经掌握 goroutine 和 channel 基础语法的 Go 开发者。
- 正在处理批量任务,希望限制并发数量的后端同学。
- 想理解 worker pool 收尾顺序,避免 goroutine 泄漏的读者。
目录
- 为什么不能无限启动 goroutine
- worker pool 的核心结构
- 实现一个可运行版本
- 正确关闭 jobs 和 results
- 加上错误结果和超时控制
- 常见坑与总结
一、为什么不能无限启动 goroutine
假设要处理 2000 个商品库存同步任务,最直接的写法是每个任务起一个 goroutine:
for _, item := range items {
go func(item Item) {
syncStock(item)
}(item)
}
这段代码不一定马上出问题,但风险很集中:goroutine 数量不可控,下游接口可能被打满,数据库连接池可能耗尽,错误结果也不好统一收集。真正上线后,最难排查的是“偶尔很慢”和“高峰时突然失败”。
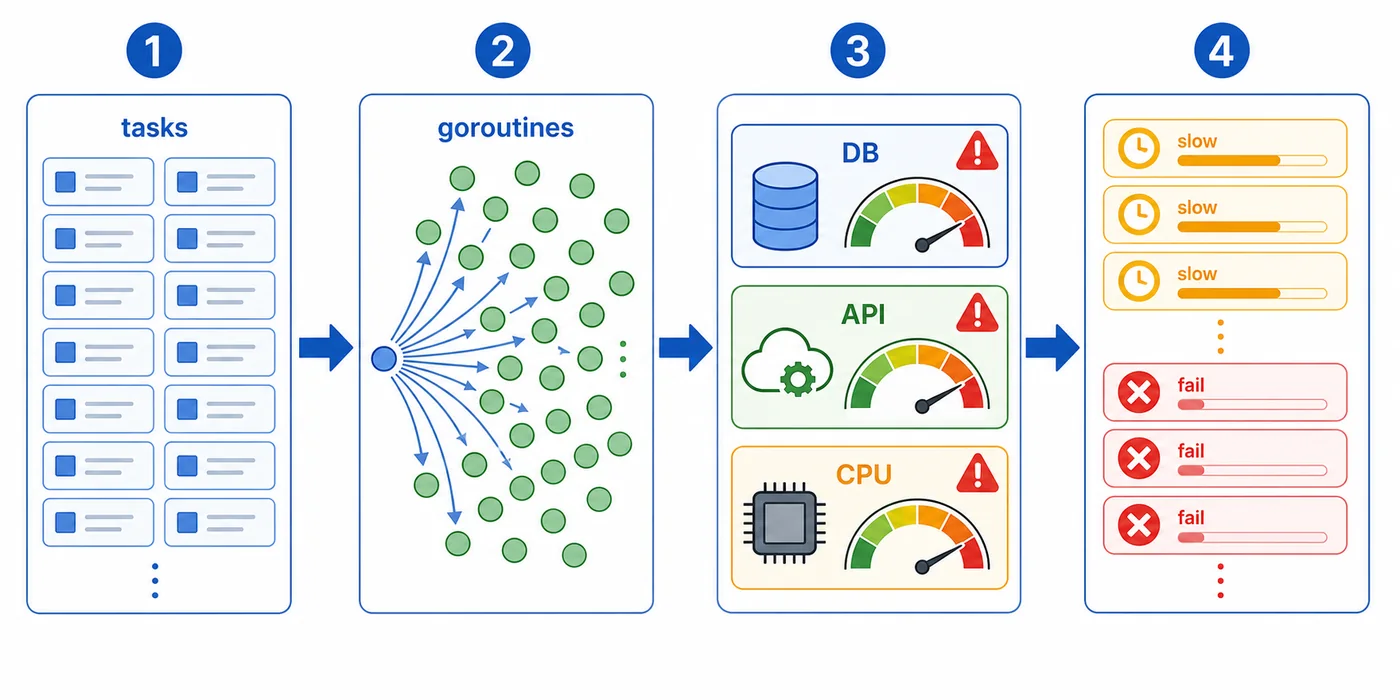
二、worker pool 的核心结构
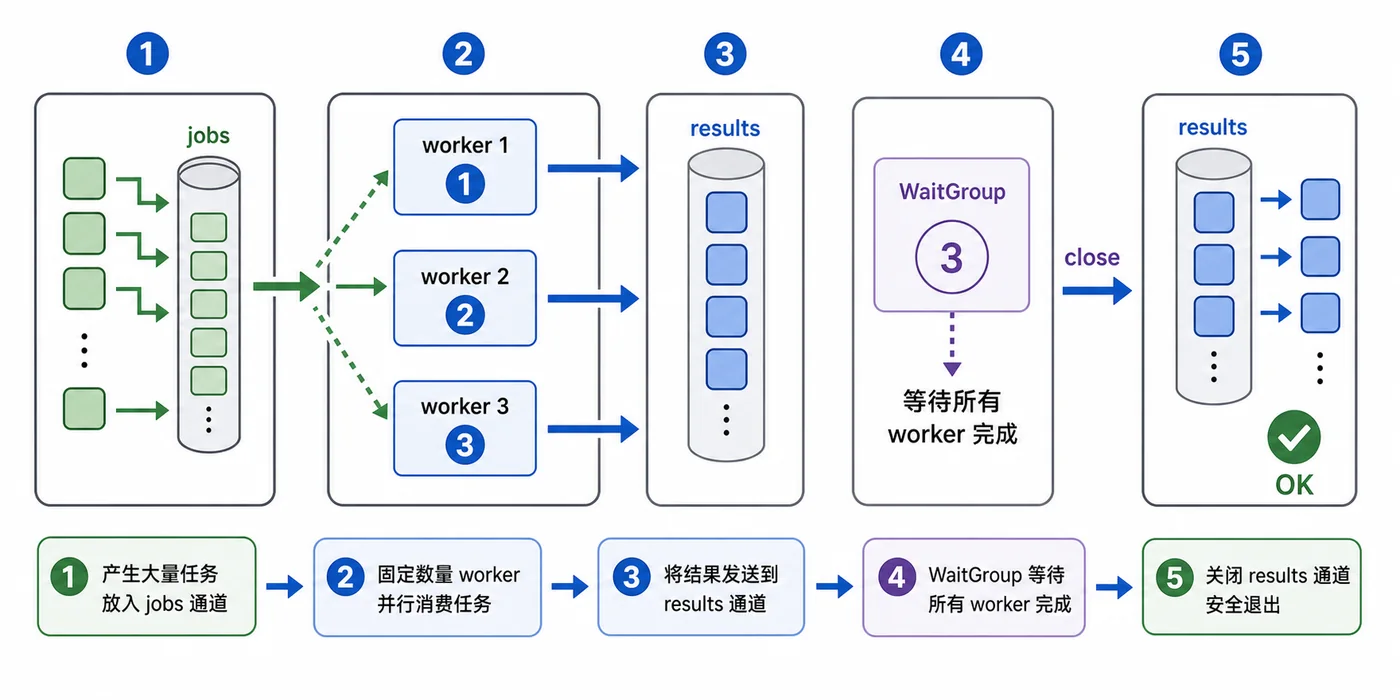
一个固定并发的 worker pool 通常由四部分组成:
- jobs:任务队列,生产者把任务写进去。
- workers:固定数量的 goroutine,从 jobs 中取任务。
- results:结果队列,worker 把处理结果写回来。
- WaitGroup:等待所有 worker 完成,再关闭 results。
关键点是:任务数量可以是 2000,但 worker 数量可以固定为 5、10 或 20。并发上限由 worker 数量决定,而不是由任务数量决定。
三、实现一个可运行版本
下面用一个简化的任务处理程序演示完整流程。每个任务有一个 ID,worker 处理后返回结果。
package main
import (
"fmt"
"sync"
"time"
)
type Job struct {
ID int
}
type Result struct {
JobID int
Value string
}
func handle(job Job) Result {
time.Sleep(100 * time.Millisecond)
return Result{
JobID: job.ID,
Value: fmt.Sprintf("job-%d-ok", job.ID),
}
}
func worker(id int, jobs
运行时你会看到 10 个任务被 3 个 worker 分批处理。这里的重点不是谁先完成,而是同时工作的 worker 数量被限制住了。
四、正确关闭 jobs 和 results
worker pool 最容易写错的是关闭顺序。可以记住两句话:
- 生产者关闭 jobs:表示不会再有新任务。
- 等待 worker 后关闭 results:表示不会再有新结果。
不要让 worker 关闭 jobs,因为 worker 只是消费者;也不要在任务刚发完时立刻关闭 results,因为 worker 可能还在写结果。
go func() {
for _, job := range allJobs {
jobs
这个顺序能保证:所有任务都被 worker 读完,所有结果都写完,主 goroutine 再从 results 里读到结束。
五、加上错误结果和超时控制
真实业务里,任务可能失败。建议把错误也放进结果结构,而不是在 worker 里直接打印后丢掉。
type TaskResult struct {
JobID int
Value string
Err error
}
如果任务里有外部接口调用,还可以把 context.Context 传入处理函数,由上层统一控制超时或取消。
func handleWithContext(ctx context.Context, job Job) TaskResult {
select {
case
注意,超时控制不是为了让代码看起来复杂,而是为了在下游变慢时尽快释放 worker,不让任务队列一直堆积。
六、常见坑与总结
1. results 没人读会卡住
如果 results 是无缓冲 channel,而主 goroutine 没有读取,worker 写结果时会阻塞。要么及时读取,要么按场景设置合理缓冲。
2. worker 数量不是越大越好
worker 数量要结合下游能力来定。比如数据库连接池只有 20 个连接,就不要让 200 个 worker 同时冲进去。
3. 不要忘记关闭 jobs
worker 通过 for job := range jobs 退出。如果生产者不关闭 jobs,worker 会一直等待新任务,程序就可能无法结束。
4. 结果要统一收集
批量任务最怕“失败了但没人知道”。把成功和失败都放进结果结构,最后统一汇总,日志和重试都会更清楚。
总结一下:worker pool 的价值不是让任务跑得越多越好,而是让并发数量可控、结果可追踪、收尾顺序可靠。掌握 jobs、workers、results 和 WaitGroup 这四块,绝大多数批量任务场景都能稳稳落地。
-
200 收藏
-
440 收藏
-
477 收藏
-
399 收藏
-
455 收藏
-
367 收藏
-
Golang · Go教程 | 2天前 | channel · select · Context · Go教程 · 性能排查 · select channel context default time.Ticker Go教程 CPU飙高 for select459 收藏
-
Golang · Go教程 | 2天前 | map · 基准测试 · 性能优化 · Go教程 · 内存分配 · 内存分配 Go性能优化 benchmark Go教程 map预分配 make map benchmem395 收藏
-
Golang · Go教程 | 2天前 | defer · 单元测试 · testing · Go教程 · t.Cleanup · defer 单元测试 Testing 子测试 Go教程 T.Cleanup 测试资源清理418 收藏
-
Golang · Go教程 | 2天前 | defer · Go教程 · 文件句柄 · 资源释放 · 数据库rows · defer for循环 文件句柄 资源释放 close Go教程 rows.Close421 收藏
-
Golang · Go教程 | 2天前 | HTTP · 文件上传 · Go教程 · 资源预算 · multipart · 文件上传 临时文件 ParseMultipartForm multipart Go教程 MaxBytesReader 资源预算237 收藏
-
Golang · Go教程 | 3天前 | 中间件 · HTTP · recover · Go教程 · 日志排障 · recover panic 结构化日志 HTTP中间件 request_id Go教程 接口排障111 收藏
-
399 收藏
-
386 收藏
-
234 收藏
-
476 收藏
-
176 收藏
-

- 前端进阶之JavaScript设计模式
- 设计模式是开发人员在软件开发过程中面临一般问题时的解决方案,代表了最佳的实践。本课程的主打内容包括JS常见设计模式以及具体应用场景,打造一站式知识长龙服务,适合有JS基础的同学学习。
- 立即学习 543次学习
-

- GO语言核心编程课程
- 本课程采用真实案例,全面具体可落地,从理论到实践,一步一步将GO核心编程技术、编程思想、底层实现融会贯通,使学习者贴近时代脉搏,做IT互联网时代的弄潮儿。
- 立即学习 516次学习
-

- 简单聊聊mysql8与网络通信
- 如有问题加微信:Le-studyg;在课程中,我们将首先介绍MySQL8的新特性,包括性能优化、安全增强、新数据类型等,帮助学生快速熟悉MySQL8的最新功能。接着,我们将深入解析MySQL的网络通信机制,包括协议、连接管理、数据传输等,让
- 立即学习 500次学习
-

- JavaScript正则表达式基础与实战
- 在任何一门编程语言中,正则表达式,都是一项重要的知识,它提供了高效的字符串匹配与捕获机制,可以极大的简化程序设计。
- 立即学习 487次学习
-

- 从零制作响应式网站—Grid布局
- 本系列教程将展示从零制作一个假想的网络科技公司官网,分为导航,轮播,关于我们,成功案例,服务流程,团队介绍,数据部分,公司动态,底部信息等内容区块。网站整体采用CSSGrid布局,支持响应式,有流畅过渡和展现动画。
- 立即学习 485次学习