Python CSV 批量导入实战:分批校验、错误行回写和事务提交
来源:17golang原创
时间:2026-06-13 05:58:01 204浏览 收藏
后台系统经常会有“上传 CSV 批量导入用户、商品、订单”的需求。功能看起来简单,但真放到线上很容易踩坑:文件一次性读入导致内存上涨,某一行格式不对让整批失败,或者前半批写入成功、后半批失败,最后数据状态变得很难解释。
本文用“用户 CSV 导入”做例子,拆一套更稳的处理流程:流式读取、逐行校验、按批次写入、错误行回写。代码不依赖复杂框架,重点是把导入任务拆成可观察、可回滚、可复核的步骤。
摘要
本篇文章会完成四件事:定义 CSV 字段规则、逐行收集错误、分批提交有效数据、生成失败明细文件。适合正在做管理后台、数据迁移、运营导入工具的 Python 开发者阅读。
适合人群
- 需要处理 CSV 导入,但不想一次性把文件全部读入内存的开发者。
- 需要把错误行返回给运营或业务同学复核的后端同学。
- 希望导入逻辑更容易测试、重跑和排查的团队。
目录
- 导入流程应该拆成哪些阶段
- 用生成器逐行读取 CSV
- 把校验结果拆成成功行和错误行
- 按批次提交,避免半成功难排查
- 常见坑和总结
导入流程应该拆成哪些阶段
不要把 CSV 导入写成一个大函数。更稳的方式是拆成四个阶段:读取、校验、分批、提交。每个阶段只做一件事,出了问题也能快速定位。
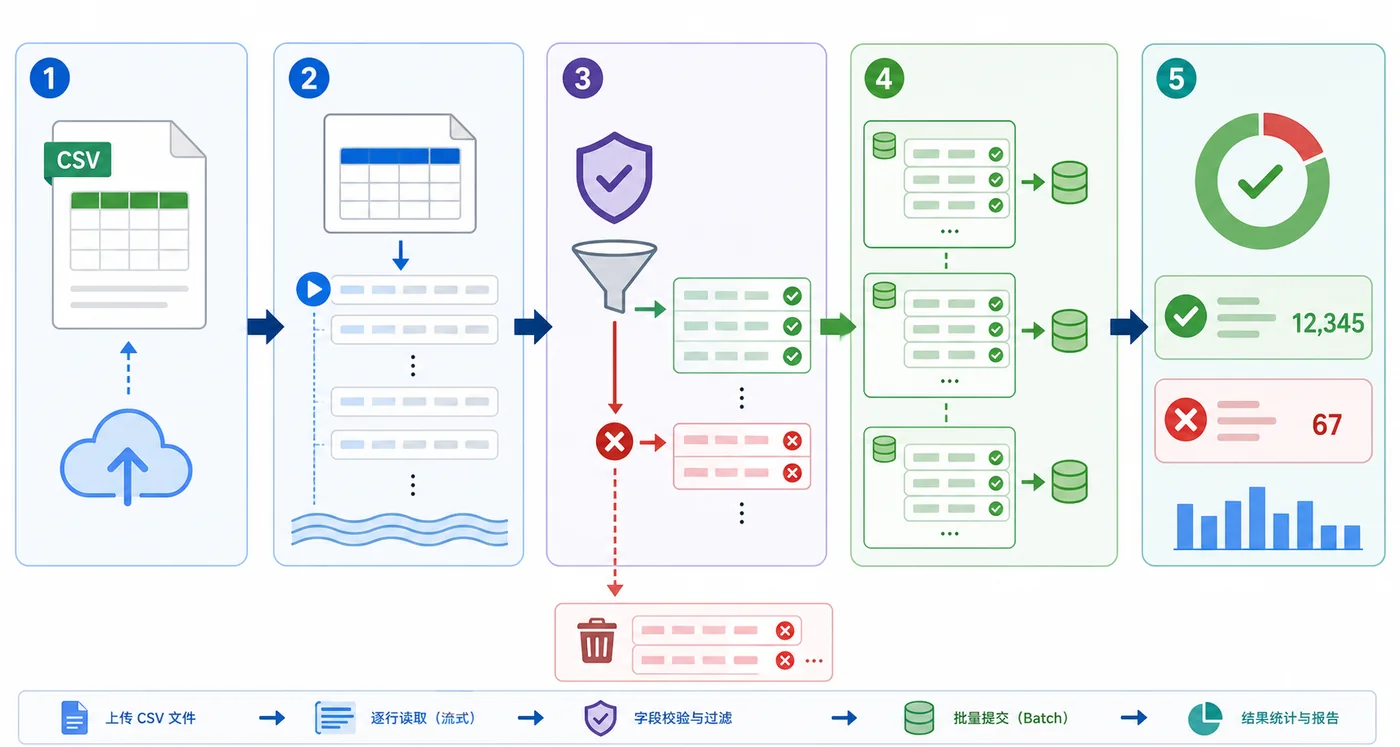
比如用户导入可以约定字段为 name、mobile、email、level。如果某一行手机号为空,就把这一行写入错误列表,而不是让整个文件直接失败。
用生成器逐行读取 CSV
CSV 文件可能只有几百行,也可能有几十万行。为了避免内存压力,推荐使用生成器逐行产出记录。
import csv
from dataclasses import dataclass
from pathlib import Path
@dataclass
class RawRow:
row_no: int
data: dict[str, str]
def read_csv_rows(path: Path):
with path.open("r", encoding="utf-8-sig", newline="") as file:
reader = csv.DictReader(file)
for row_no, row in enumerate(reader, start=2):
yield RawRow(row_no=row_no, data={k: (v or "").strip() for k, v in row.items()})
这里没有把所有行先放进列表,而是一行一行产出给后续校验逻辑。这样即使文件变大,也不会因为读取阶段就把内存顶上去。使用 utf-8-sig 是为了兼容带 BOM 的 CSV 文件。
把校验结果拆成成功行和错误行
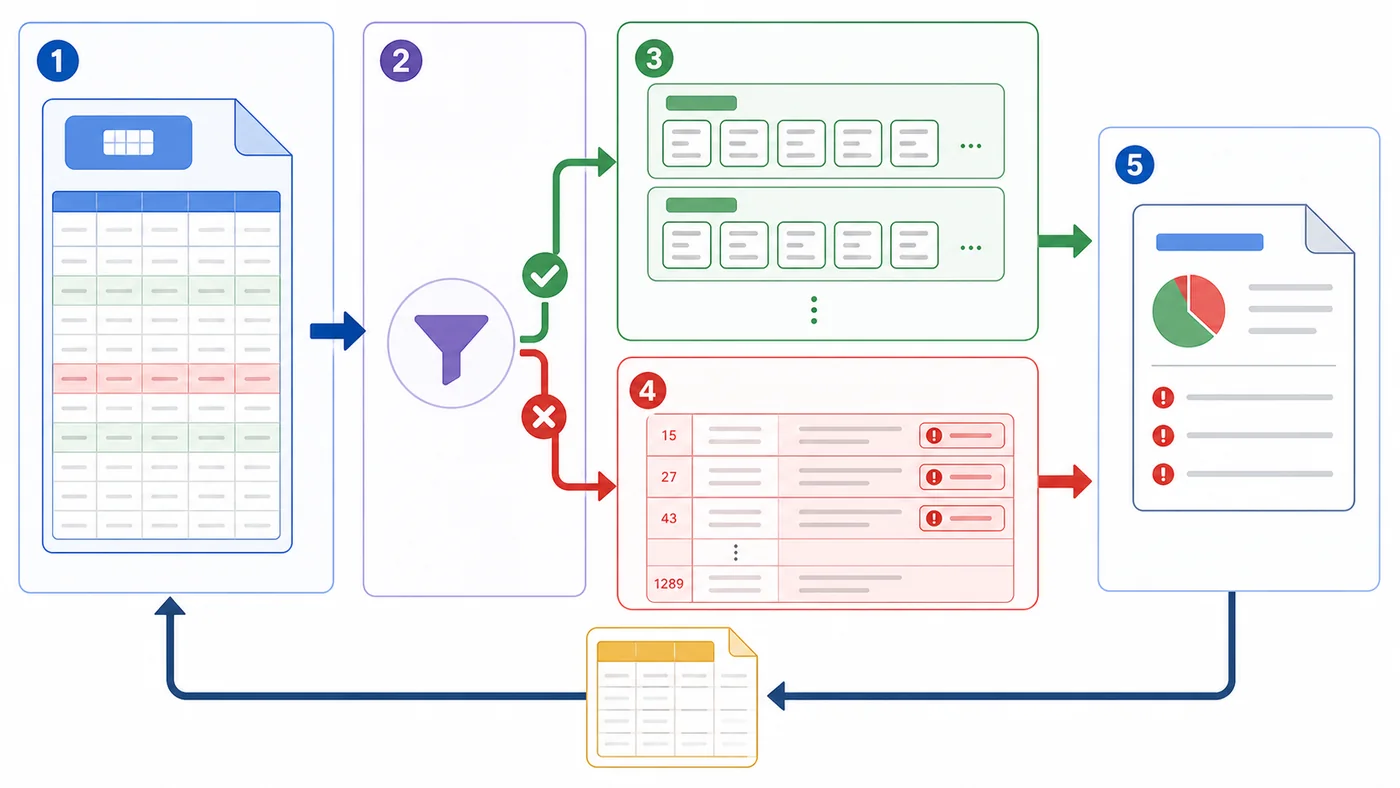
校验函数最好返回结构化结果,而不是直接抛错。这样才能把所有错误一次性反馈给用户。
import re
from dataclasses import dataclass
MOBILE_PATTERN = re.compile(r"^1[3-9]\d{9}$")
@dataclass
class ValidUser:
name: str
mobile: str
email: str
level: int
@dataclass
class RowError:
row_no: int
reason: str
data: dict[str, str]
def validate_row(row: RawRow) -> tuple[ValidUser | None, RowError | None]:
data = row.data
if not data.get("name"):
return None, RowError(row.row_no, "姓名不能为空", data)
mobile = data.get("mobile", "")
if not MOBILE_PATTERN.match(mobile):
return None, RowError(row.row_no, "手机号格式不正确", data)
try:
level = int(data.get("level", "1"))
except ValueError:
return None, RowError(row.row_no, "等级必须是数字", data)
return ValidUser(
name=data["name"],
mobile=mobile,
email=data.get("email", ""),
level=level,
), None
这样处理后,导入结果会分成两条路径:合法数据进入待提交批次,错误数据进入失败明细。业务同学可以修复失败行后再次上传,不需要猜是哪一行出错。
按批次提交,避免半成功难排查
提交阶段不要一行一行写,也不要无限积攒后一次性写。常见做法是每 500 或 1000 行作为一个批次,根据数据库压力和字段数量调整。
from collections.abc import Iterable
def split_batches(items: list[ValidUser], size: int = 500) -> Iterable[list[ValidUser]]:
for start in range(0, len(items), size):
yield items[start:start + size]
class UserRepository:
def save_many(self, users: list[ValidUser]) -> None:
# 这里对接具体数据库或 ORM 的批量保存接口
pass
def import_users(path: Path, repo: UserRepository) -> dict[str, int]:
valid_users: list[ValidUser] = []
errors: list[RowError] = []
for raw in read_csv_rows(path):
user, error = validate_row(raw)
if error:
errors.append(error)
else:
valid_users.append(user)
for batch in split_batches(valid_users, size=500):
repo.save_many(batch)
write_error_report(path.with_suffix(".errors.csv"), errors)
return {"success": len(valid_users), "failed": len(errors)}
如果业务要求“只要有一行错误就整批不入库”,可以在提交前判断 errors 是否为空。反过来,如果允许部分成功,就必须把成功数量、失败数量、失败明细都记录清楚。
生成错误明细文件
错误明细最好保留原始字段,并额外加上行号和失败原因。这样运营同学打开文件后,可以直接修改并重新上传。
def write_error_report(path: Path, errors: list[RowError]) -> None:
if not errors:
return
fieldnames = ["row_no", "reason", "name", "mobile", "email", "level"]
with path.open("w", encoding="utf-8-sig", newline="") as file:
writer = csv.DictWriter(file, fieldnames=fieldnames)
writer.writeheader()
for item in errors:
writer.writerow({
"row_no": item.row_no,
"reason": item.reason,
"name": item.data.get("name", ""),
"mobile": item.data.get("mobile", ""),
"email": item.data.get("email", ""),
"level": item.data.get("level", ""),
})
这个失败文件也是排查依据。后续如果有人问“为什么导入少了 37 行”,直接看错误明细就能解释,不需要翻日志猜测。
常见坑
- 没有行号。 用户只知道失败,却不知道失败在哪一行,沟通成本会很高。
- 错误遇到一个就停止。 批量导入更适合一次性收集所有格式错误。
- 不限制文件大小。 上传入口要限制大小和行数,避免把后台接口拖慢。
- 不处理重复数据。 手机号、订单号这类唯一字段要在入库前或入库时明确冲突策略。
- 失败明细没有编码兼容。 输出 CSV 推荐使用
utf-8-sig,方便常见表格软件打开。
总结
Python CSV 批量导入的关键,不是把文件读出来这么简单,而是把流程拆清楚:逐行读取、逐行校验、分批提交、错误回写。这样做之后,导入任务既能支撑更大的文件,也能给业务方一个可复核的失败结果,线上排查会轻松很多。
-
361 收藏
-
346 收藏
-
235 收藏
-
413 收藏
-
501 收藏
-
133 收藏
-
322 收藏
-
136 收藏
-
496 收藏
-
219 收藏
-
210 收藏
-
268 收藏
-
330 收藏
-
文章 · python教程 | 5天前 | 并发 · python · 故障排查 · asyncio · 任务取消 · Python asyncio.create_task Python 任务取消 asyncio CancelledError Python 异步任务收尾490 收藏
-
196 收藏
-
495 收藏
-
文章 · python教程 | 1星期前 | 时间处理 · python · zoneinfo · 后端开发 · UTC · Python DateTime UTC 夏令时 zoneinfo fold469 收藏
-

- 前端进阶之JavaScript设计模式
- 设计模式是开发人员在软件开发过程中面临一般问题时的解决方案,代表了最佳的实践。本课程的主打内容包括JS常见设计模式以及具体应用场景,打造一站式知识长龙服务,适合有JS基础的同学学习。
- 立即学习 543次学习
-

- GO语言核心编程课程
- 本课程采用真实案例,全面具体可落地,从理论到实践,一步一步将GO核心编程技术、编程思想、底层实现融会贯通,使学习者贴近时代脉搏,做IT互联网时代的弄潮儿。
- 立即学习 516次学习
-

- 简单聊聊mysql8与网络通信
- 如有问题加微信:Le-studyg;在课程中,我们将首先介绍MySQL8的新特性,包括性能优化、安全增强、新数据类型等,帮助学生快速熟悉MySQL8的最新功能。接着,我们将深入解析MySQL的网络通信机制,包括协议、连接管理、数据传输等,让
- 立即学习 500次学习
-

- JavaScript正则表达式基础与实战
- 在任何一门编程语言中,正则表达式,都是一项重要的知识,它提供了高效的字符串匹配与捕获机制,可以极大的简化程序设计。
- 立即学习 487次学习
-

- 从零制作响应式网站—Grid布局
- 本系列教程将展示从零制作一个假想的网络科技公司官网,分为导航,轮播,关于我们,成功案例,服务流程,团队介绍,数据部分,公司动态,底部信息等内容区块。网站整体采用CSSGrid布局,支持响应式,有流畅过渡和展现动画。
- 立即学习 485次学习